David Wong, Department of Geography and Earth Systems, George
Mason University, Fairfax, VA 22030-4444. dwong2@gmu.edu
For this study, we use the parcel level data set of Geauga County in Ohio. Geauga
Count is located in Northeast Ohio. It is one of the sub-urban counties in the
greater Cleveland Metropolitan Region. Due to the process of suburbanization
occurring in Cleveland over the last two decades, there has been significant urban sprawl
observed in Geauga and nearby counties at the same time. While the sprawling
built-out in Geauga County is by no means an isolated phenomenon, the reasons
and patterns of residential development displayed in it are similar to many
other regions in the country. As such, a case study based on a suburban county
for investigating the spatial structure of urban sprawl will provide much
needed insights that can be generalized in other parts of the country.
In the following figure, parcels that were
built earlier are shown in darker colors while parcels built recently are
shown in lighter color. The four categories are: pre-1900, 1900-1950,
1950-1970, and 1970-2000.
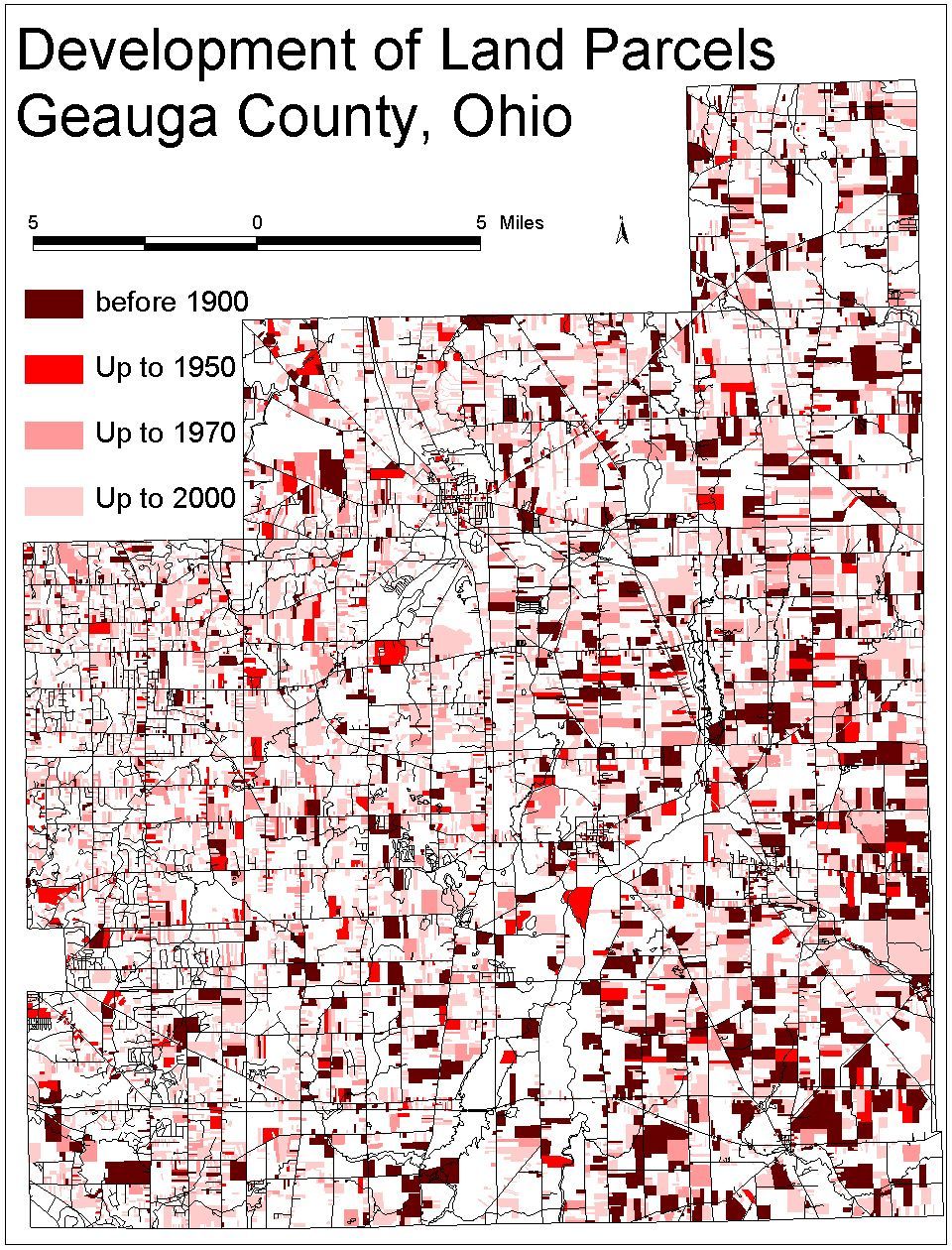
As shown in the above map, Geauga County has seen much of its
lands been developed within just the last several decades. The sprawling of
developed parcel is certainly to a great extent being influence by the
Cleveland Metropolitan from the west. However, it is difficult to gain a
detailed understanding just by looking at this map. A quantitative measure
that describes the spatial pattern of the parcel development will allow us to
fully explore the trend of land development.
For Geauga County, we obtained from the county's Auditor's
Office a data set that contains boundaries of all parcels, their assessed land
values, the years parcels were built, land use, and many other administrative
attributes. For the purpose of this study, we used only the attribute that
contains the years these parcels were built. With this attribute, we are able
to construct, dating back to pre-1900 time, the spatial patterns of developed
lands for any year between 1800 and 2000, or any duration of time periods.
For this study, we applied a spatial statistics known as Joint Count
Statistics, the simplest form of spatial autocorrelation. The Joint Count
Statistic is not the most powerful spatial statistic but it is appropriate for
this study. It is appropriate for use if data are in binary
form and if data are about areas (polygons).
In the case of this study, we have structured the year-built attribute so that
at any given year, we distinguish parcels to be either developed or undeveloped
by that year. Furthermore, the parcel boundaries in the county's Auditor's file
define the polygons as areal unit of data.
In statistical concepts, autocorrelation is the relationship between
successive values of residuals along a regression line. In most cases, a strong
autocorrelation indicates successive values are strongly related. In other
words, data values being regressed may have a systematic trend existing among
them.
Spatial autocorrealtion is a simple extension of the autocorrelation
discussed above into two dimensions:
- A strong, positive spatial autocorrelation means that the
characteristics of geographic objects are very similar to those of nearby
objects. This is normally referred to as a clustered
pattern.
- Alternatively, a strong negative spatial autocorrelation, in turn,
suggests that geographic objects may have very distinctive properties
between adjacent objects. This is known as a dispersed
or uniform pattern.
- When there is no measurable spatial autocorrelation, the
geographic objects are said to be in a random
pattern.
The three patterns (clustered, random, and disperse) serve as three mile
posts along a spectrum along which many other possibilities exist between
clustered and random patterns or between random and disperse patterns. Because
of this, a value of spatial autocorrelation coefficient by itself is not useful
unless it is tested for its statistical significance of how different it is from
a coefficient value indicating a particular pattern. For example, a spatial
autocorrelation coefficient measured from an observed pattern will need to be
tested to see if it is statistically significantly different from the
coefficient value of a random pattern.
For this study, we selected Joint Count Statistics due to the polygonal form
of land parcels and due to the built/unbuilt bindary form of attribute data.
What we were measuring was, in any given year, if the built-unbuilt pattern was
statistically significantly different from a random pattern; if so, by how much.
For this, we have calculated Joint Count Statistics for each township in each
decade.
There are a total of 22 townships and villages. Built/unbuilt data are
available from 1800 to 2000. For reasons of annexation and simple data
processing, 23 townships/villages were integrated into 21 areal units. Along the
temporal axis, yearly data were integrated to every 10th year (pre-1900, 1910,
1920, ..., 1990, and 2000).
The spatial statistic, Joint Count Statistics, was implemented in Avenue
scripts as parts of the accompanying package in our book, Statistical Analysis
with ArcView GIS (Lee and Wong, 2000) as a menu item. A total of two steps are
needed to run the procedure for any data set. The first step is to calculate the
distance matrix. In this step each parcel was examined in turn. All its
neighbors were found and recorded into the distance matrix which takes a binary
form of 1 (indicating neighboring relationship between column parcel and row
parcel) and 0 (no neighbor relationship).
The second step calculates Joint Count Statistic based on A (built parcels)
and B (un-built parcels) as given in Lee and Wong (2000). As discussed in our
book, the testing of statistical significance can be based on either a free
sampling or a non-free sampling hypothesis.
The free-sampling hypothesis assumes that the probability of a parcel being
built or un-built is known without reference to the study region. In other
words, the built/un-built division is not based on local condition but rather
the trend from a much larger geographic unit that contains the study region.
The non-free sampling hypothesis assumes that the numbers of built parcels and
un-built parcels remain the same but their arrangement can be different in the
study region. This hypothesis is based on local condition. The statistical
testing based on this hypothesis allows analyst to assume that the observed
pattern is only one of many possible arrangements using the same number of
built parcels and un-built parcels, without making any reference to outside
factors.
Specifically, we are performing the following steps when using Joint Count
Statistics:
- Count the actual number of shared boundaries (joins) between built and
un-built polygons that are neighbors, (OBU).
- Calculate expected number of built-unbuilt joins for a random pattern,
(EBU).
- Calculate the standard deviation of the number of built-unbuilt joins,
(SBU).
- Calculate Z-score using the observed number of joins, expected number
of joins and the standard deviation of joins, (Z=[(OBU-EBU)/SBU].
In this fashion, the value of Z is an indication of:
If Z approximates 0, it means the the observed pattern is no difference
with a random pattern.
If Z > 0, it means that the observed pattern has more built-unbuilt
joins than a random pattern - the observed pattern is more likely a dispersed
pattern. For our study, this means urban sprawl because the newly built
parcels are not adjacent to existing built parcels.
If Z < 0, it means that the observed pattern has less built-unbuilt
joins than a random pattern - the observed pattern is likely a clustered
pattern. To our purpose, the built-out pattern may be more compact expansion
where newly built parcels are adjacent to existing built parcels.
To the issue of statistical significance of an observed pattern being
different from a random pattern, let's adopt the conventional alpha=0.05
confidence level. That level can be translated to:
Expansion development: If Z < -1.96, it means that the observed pattern
is a more clustered pattern than a random pattern. Typically, a more
contagious expansion of parcel development will yield such Z values. The more
negative the Z value is, the more clustered the observed pattern is.
Sprawling development: if Z > 1.96, it means that the observed pattern
is a more dispersed pattern than a random pattern. Similarly, a more
leap-frogging development will yield such Z values. The larger the positive Z
value is, the more severe sprawling the observed pattern has.
Spatial Pattern of Residential Development
The townships in Geauga County have been consolidated into 22 areal units.
The following map shows the relative position of these townships/villages.
Note that Geauga County is located east of Cleveland. Therefore, influence by
Cleveland should come from the west (left) side of the map.

With Geauga County divided into 22 areal units and year-built attribute
information integrated to every 10th year, we have compiled the following
tables that shows the Z-scores for testing the significance level of computed.
In the cases when Z values are greater than +1.96, they are listed in blue
while Z values that are less than -1.95 are listed in red.
|
Pre1900 |
Upto1910 |
Upto1920 |
Upto1930 |
Upto1940 |
Upto1950 |
Upto1960 |
Upto1970 |
Upto1980 |
Upto1990 |
Upto2000 |
| Thompson
Twp. |
-0.07 |
0.42 |
0.30 |
0.29 |
0.01 |
-0.23 |
-1.29 |
-3.07 |
-3.13 |
-4.08 |
-3.20 |
| Montville
Twp. |
2.55 |
2.76 |
2.65 |
1.69 |
0.87 |
-0.43 |
-2.40 |
-3.93 |
-5.05 |
-5.67 |
-0.69 |
| Hambden
Twp. |
2.81 |
2.36 |
2.26 |
1.69 |
0.82 |
-1.19 |
-5.20 |
-7.82 |
-10.50 |
-9.32 |
-4.90 |
| Chardon
Twp. |
1.23 |
1.06 |
1.04 |
-0.01 |
0.05 |
-1.64 |
-12.10 |
-16.83 |
-18.51 |
-15.12 |
-5.65 |
| Chardon
Village |
-5.83 |
-9.84 |
-11.53 |
-14.86 |
-15.79 |
-18.23 |
-25.03 |
-28.72 |
-32.50 |
-29.85 |
-10.18 |
| Huntsburg
Twp. |
2.39 |
2.71 |
3.21 |
3.40 |
2.98 |
3.00 |
0.04 |
-1.68 |
-4.13 |
-5.61 |
-3.09 |
| Claridon
Twp. |
0.67 |
0.53 |
0.67 |
-1.10 |
-1.24 |
-2.15 |
-5.10 |
-6.04 |
-7.21 |
-6.00 |
-3.48 |
| Munson
Twp. |
-0.65 |
-0.89 |
-0.44 |
-0.74 |
-1.35 |
-2.46 |
-7.99 |
-13.43 |
-17.66 |
-19.76 |
-10.37 |
| Chester
Twp. |
0.76 |
0.22 |
0.00 |
-0.20 |
-0.76 |
-3.45 |
-21.03 |
-34.64 |
-22.04 |
-14.78 |
-9.14 |
| Aquilla
Village |
0.67 |
0.53 |
0.67 |
-1.10 |
-1.24 |
-2.15 |
-5.10 |
-6.04 |
-7.21 |
-6.00 |
-3.48 |
| Middlefield
Twp. |
4.12 |
2.69 |
2.63 |
5.11 |
4.68 |
1.13 |
-0.75 |
-3.54 |
-5.60 |
-3.86 |
-1.36 |
| Burton
Twp. |
-0.08 |
-0.19 |
-0.19 |
-0.97 |
-0.93 |
-2.04 |
-7.69 |
-10.03 |
-15.35 |
-15.20 |
-15.44 |
| Newbury
Twp. |
0.38 |
-0.06 |
-0.31 |
-1.49 |
-1.71 |
-2.43 |
-9.01 |
-9.41 |
-17.44 |
-19.54 |
-22.87 |
| Russell
Twp. |
-0.06 |
-0.36 |
-0.38 |
-0.56 |
-1.38 |
-4.95 |
-15.14 |
-22.03 |
-16.72 |
-9.90 |
-6.40 |
| Hunting
Valley Village |
-1.15 |
-1.45 |
-0.98 |
-1.03 |
-1.26 |
-1.94 |
-0.99 |
-2.36 |
-2.63 |
-1.71 |
-1.65 |
| Burton
Village |
-4.82 |
-5.77 |
-6.95 |
-8.91 |
-10.14 |
-9.50 |
-9.82 |
-9.67 |
-8.18 |
-7.18 |
-4.57 |
| Middlefield
Village |
-1.33 |
-2.71 |
-3.41 |
-9.28 |
-9.83 |
-11.74 |
-14.70 |
-15.36 |
-17.60 |
-18.55 |
-16.84 |
| South
Russell Village |
0.78 |
0.13 |
0.14 |
-0.54 |
-0.80 |
-1.46 |
-8.73 |
-27.74 |
-30.27 |
-16.51 |
-0.80 |
| Parkman
Twp. |
1.85 |
1.63 |
1.41 |
1.51 |
1.15 |
-0.88 |
-2.78 |
-3.58 |
-5.72 |
-5.94 |
0.13 |
| Troy
Twp. |
3.22 |
2.65 |
2.81 |
1.90 |
2.02 |
-0.10 |
-2.83 |
-4.38 |
-5.75 |
-5.96 |
-6.00 |
| Auburn
Twp. |
-0.03 |
0.07 |
-0.01 |
-0.53 |
-1.45 |
-3.86 |
-6.68 |
-7.77 |
-14.93 |
-22.78 |
-17.12 |
| Bainbridge
Twp. |
-0.65 |
-0.89 |
-1.14 |
-1.49 |
-1.74 |
-3.15 |
-11.62 |
-20.95 |
-37.35 |
-47.49 |
-35.90 |
Among the 22 areal units, it can be seen that they display different
spatial patterns of parcel development as well as changes over time. To
simplify the description, the townships are grouped to the following
categories:
Old, intensely developed areas:
This group includes Chardon Village, Burton Village, and Middlefield Village.
The three villages were developed the earliest in the county and were
urbanized the earliest. Their Z values are statistically significant dating
back to pre-1900 era. This indicates that these villages are matured urbanized
areas with few un-built parcels for new development.
Mature developed areas: This
group includes Montville Township, Humbden Township, Huntsburg Township,
Middlefield Township, and Troy Township. They are mostly in the eastern part
of the county. These areas were sparsely developed in the earlier part of the
century but began to develop since 1950 with influence from the old, intensely
developed areas.
Young developing areas: This
group includes the rest of the townships. As can be seen in the above table
and the maps below, these townships did not display any significant spatial
pattern until 1950's when they began receiving influences from Cleveland
Metropolitan region. Due to space limit, the rate of growth has slowed down
somewhat but the dramatic growth experienced in the county is apparent as the
Z values indicated in the above table.
If using trend lines, these values can be translated to the following
diagram:

In graphic form, the following maps show a temporal account of the changes
in Z values by the townships and villages in the county. It can be seen that
the earlier development in the county was mostly generated from within the
county but the recent development was clearly influenced by Cleveland which is
in the next county to the west (left).





