Steve Andrews
The U.S. Environmental Protection Agency (EPA) and INDUS Corporation have developed an Oracle SDE database for the National Hydrography Dataset (NHD). The database is optimized to support dynamic segmentation operations, specifically addressing, storing, and displaying event data addressed to NHD reach networks. The NHD combined with monitoring, pollutant source, and lake and stream use data addressed to the NHD provide many analysis opportunities. The NHD supports many water network navigation tools, and these navigation tools, in turn, support modeling of lake and stream conditions. We’ll discuss implementing, tuning, and maintaining a national SDE database with over two million reaches and tens of millions of events for Map Objects, ArcView, and ArcInfo applications.
The National Hydrography Dataset (NHD) Reach Addressing Database (RAD) is an Oracle 8i, SDE 8.0.1 database designed to serve surface water features and water quality/water use entities ("events") to mapping and query applications. The surface water features are from the NHD and, at present, are initial release NHD data. The water quality/water use events will come from various sources (mostly EPA program system databases), and the NHD RAD manages only the spatial portion of these entities. The system databases are the source for most attribute data related to these events.
The National Hydrography Dataset (NHD) is a comprehensive set of digital spatial data that contains information about surface water features such as lakes, ponds, streams, rivers, springs and wells. Within the NHD, surface water features are combined to form "reaches," which provide the framework for linking water-related data to the NHD surface water drainage network. These linkages enable the analysis and display of these water-related data in upstream and downstream order.
The NHD is based upon the content of USGS Digital Line Graph (DLG) hydrography data integrated with reach-related information from the EPA Reach File Version 3 (RF3). The NHD supersedes DLG and RF3 by incorporating them, not by replacing them. Users of DLG or RF3 will find the National Hydrography Dataset both familiar and greatly expanded and refined.
While initially based on 1:100,000-scale data, the NHD is designed to incorporate and encourage the development of higher resolution data required by many users.
The NHD is a joint data product developed by USGS and US EPA. Further information regarding the NHD data and the data itself is available from the NHD web site (
http://nhd.usgs.gov).Events stored in the NHD RAD event tables and layers may be any attribute for a hydrologic feature. Some examples include point and non-point pollution, fish advisories, monitoring stations, designated uses, permit controls, and water quality standards data. Only three systems of event data will be loaded into the initial release of the NHD RAD; these are summarized below. As events from other systems become indexed to the NHD, they will become candidates for inclusion in the NHD RAD.
The NHD RAD has three primary purposes. The first is simply to serve the NHD spatial data to mapping applications (the base function of SDE). The second is to support display of the event tables through dynamic segmentation. The third is to provide a database structure relating the various components of the NHD data structure as well as the various event tables. These relationships provide a framework for holistic analysis of basins and watersheds, incorporating the natural hydrologic features with data regarding the status and uses of these watersheds. From this framework, information about upstream and downstream conditions can be assessed, and better analyses produced.
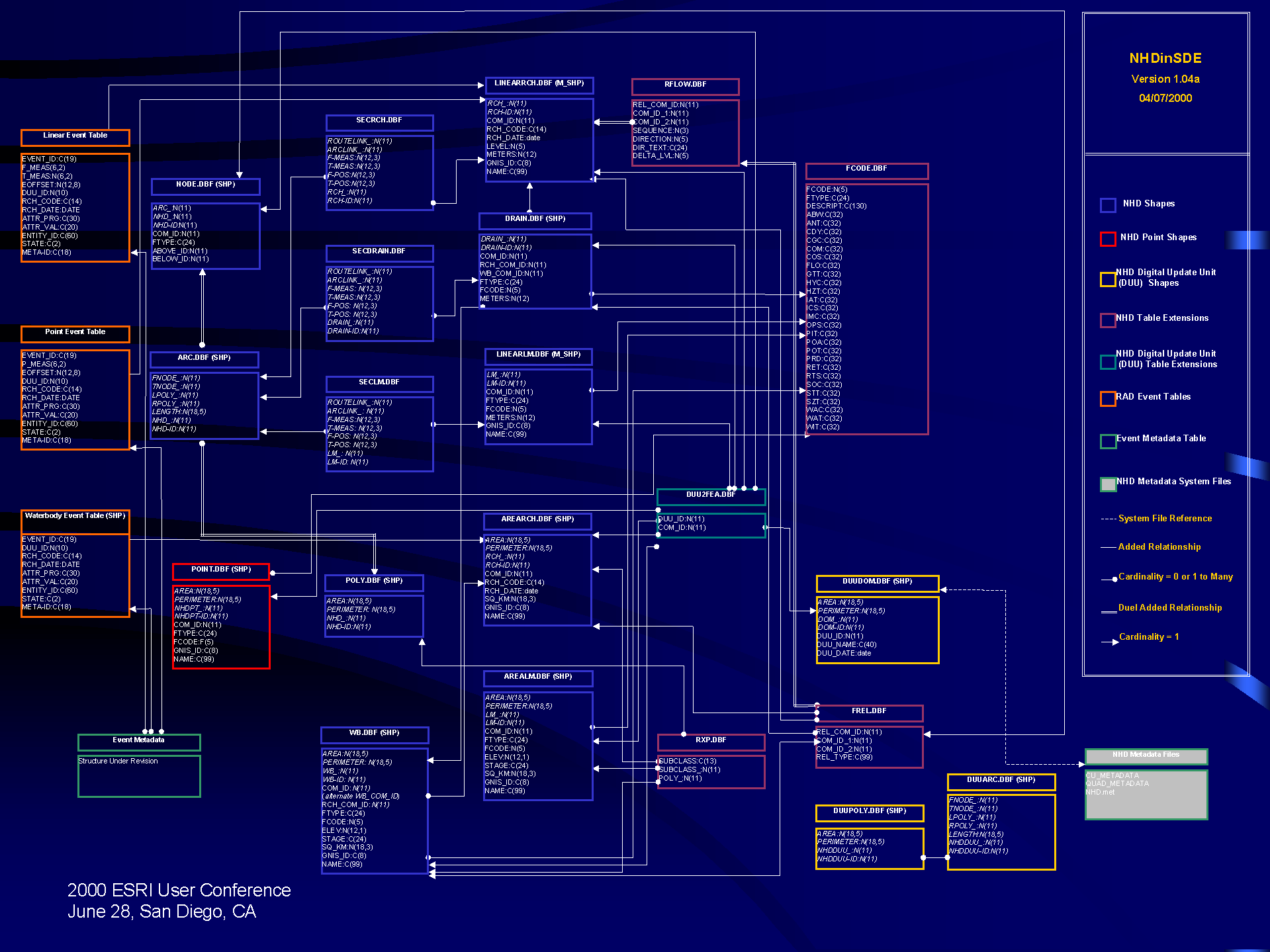
The NHD portion of the NHD RAD database consists of 13 Oracle SDE layers, 8 Oracle attribute tables, and metadata that are stored outside of Oracle. The database stores several million reaches, several hundred thousand landmark features, and several million attribute records.
The event portion of the NHD RAD database consists of two event tables and one SDE layer for each "system" of events. The two event tables hold point events and linear events, respectively, while the layer holds area events. The area events are stored as an SDE layer since dynamic segmentation over polygons is not supported. Presently, only the three systems of event data listed above (see the Event Table Data section) are loaded into the NHD RAD, however, events from other systems will be added to the NHD RAD as their database entities are indexed and submitted.
Figure 1 shows the various NHD RAD business, attribute tables, and metadata and the relationships between them.
The physical design of the NHD RAD includes industry standard physical disk usage designs for indexes. The indexes for the Oracle tables are stored in a different tablespace from the attribute data itself, and these tablespaces are stored on different physical disks (and disk controllers, where possible). This optimizes retrieval of the data by spreading data retrieval over multiple disks/controllers. This concept is expanded to include the SDE spatial indexes (as recommended by Esri), where the business tables are stored in separate tablespaces from the spatial indexes. In addition, the frequent concurrent retrieval of event table data and the linear reach layer motivated the separation of the event tables from this layer. These industry standard physical design concepts optimize the retrieval of these data.
The selection of an SDE grid cell size is not as precise a science as the distribution of tablespaces. Several factors must be weighed together to determine the best cell size including:
In general, if the geographic extent retrieved from the layer is well known, then selecting a cell size one-half to one-third this size is preferable. However, if the average number of spatial index records per business table record becomes too large (greater than four or so), then the grid cell should probably be increased. Remember that the selection of an optimal grid cell size is an inexact science, so individual testing is suggested.
There are several options for loading an SDE database. Since the source data was in ArcInfo coverage format, ArcInfo AML was selected to load the NHD RAD. The source NHD data are tiled by watershed. Each watershed was loaded first into temporary layers and tables and then evaluated. The NHD has several inherent data structures that should hold for any single watershed and for the entire database. These structures as well as the records loaded for each layer and table were checked before each watershed was appended to the production RAD layers and tables. For any SDE layers loaded from multiple source coverages or shape files, this type of error checking is recommended to avoid any possible corruption of the production layers. After each watershed is loaded into the production tables, the production data structures are again checked as are the number of records loaded into the production layers and tables.
The loading of this SDE database illustrates several issues. First, unless the database must be made available during the load process, load the SDE database in load only IO mode. When the layer is in load only IO mode, no process can access the layer, but the layer does not rebuild its spatial index until the layer is set back to normal IO mode. This significantly increases throughput to the load process, but only if the layers can be kept off-line for significant periods of time. Changing the layer's IO mode back to normal forces the creation of the spatial index for the layers, and for layers with large numbers of records, this process can take considerable time. Similarly, as with any database load process, disable all foreign key constraints while the database is being loaded. With an Oracle table, this will almost always increase performance at load time.
Also, there are several parameters that can be set in the giomgr.defs file that can increase the performance of the data load. The MINBUFSIZE and MAXBUFSIZE should be increased in the giomgr.defs file to a much larger value for data loading (the NHD RAD parameters were increased to 409,600 and 819,200 from 16,384 and 65,536, respectively). Take care to set these parameters back to their smaller size, unless your SDE server machine has unlimited resources! And, if the database must be on-line during the load process and the number of connections cannot be limited, your server may not be able to support a very large increase in these parameters. Also take care to estimate MAXINITIALFEATS appropriately so the underlying DBMS uses appropriate initial extents for the creation of the business tables.
The NHD RAD will be accessible in production via several methods. The primary access and the access method with the largest number of connections will be through an Esri map objects application, EnviroMapper. The EnviroMapper application is designed to provide basic display and query of the NHD RAD data. However, its primary function is the display of the system event data. In order to display the event data efficiently, the relationship between the event tables and the measured shapes the events are addressed to, e.g., reaches, must be optimized. In addition, restricting the geographic extent of the display of the events, if possible, is also recommended. Dynamic segmentation requires significant processing time under ideal situations.
The NHD RAD must also support the ad hoc user community accessing the NHD RAD through other SDE clients such as ArcView and ArcInfo. However, these applications generally require very similar access methods to EnviroMapper. The significant additional support the NHD RAD must provide to these ad hoc clients is navigation of the NHD hydrologic network to allow analyses of upstream and downstream conditions of the network.
The NHD RAD will be evaluated for the first several months it is in production. Few database implementations are perfect from their inception, and each should be evaluated while in production to determine areas where the performance is less than optimal or unanticipated access paths are being used. An SDE implementation of a large dataset can provide a considerable performance increase.
National Hydrography Dataset Web Page (URL: http://nhd.usgs.gov/index.html). U.S. Geological Survey. June, 2000.
{kind=link}