Normally, the analysis of geographical health variation involves the ideas of both space and place. Space indicates the extent in which events or phenomena are distributed. Space can be referred to as both the medium and outcome of social relations. Thus, suggesting social significance and is socially constructed. According to Kearns and Joseph (1993), groups in society, which are most socially separate, are, in most cases, spatially isolated in their residential distribution. Space can also be implicated in social exclusion.
A place may be referred to as a location. For instance, in geometric
space it may be identified by means of grid coordinates denoting a certain
position. It may also be positioned in a system of spatial organization,
such as a district situated in the administrative geography of a county.
Conceptually, a place may include the idea of a locale, a specific setting
in which social relations are constituted. More importantly, a sense
of place, which refers to the meaning, intention, felt value and significance
that individuals or groups give to particular places, should be considered.
Curtis and Jones (1998) points out that this perspective is often emphasized
in cultural and humanistic approaches in geography. The relationship
between space, place and time is also important. Geographic perspectives
view human interaction in time space.
Compositional and Contextual effects
Spatial variations in health may be interpreted in different ways and it is suggested that we distinguish both conceptually and empirically between compositional effects and contextual effects. Compositional effects arise from the varying distribution of types of people whose individual characteristics influence their health. A purely compositional interpretation of geographical health variation might imply that similar types of people will have similar health experience, no matter where they live. The problem of this kind of interpretation is the emphasis of ecological fallacy, whereby characteristics of aggregated regional populations might be used to generate inaccurate assumptions about individuals in the population. Curtis and Jones (1998) points out that researchers have given less value to ecological studies than to studies based on individual data due to this problem. On the other hand, an overemphasis on individuals as the most useful unit of analysis may result in problems associated with the atomistic fallacy, whereby one may overlook or misinterpret effects, which can better be understood at the level of house-hold, neighborhoods or regions. Schwartz (1994) indicates that research needs to consider ecological variables in order to understand the structural, contextual and sociological effects on public health.
The contextual effects operate where the health experience of an individual depends partly on the social and physical environment in the area where they live. This type of effect would cause people with similar individual attributes to have different health status from one part of the country to another. Consequently, the debate about compositional and contextual effect does suggest that ecological information is important to our understanding of health variation, not merely as a substitute for individual data, but also as a means of testing for the combined effects of compositional and contextual influences.
Contextual Variation in Health
The contextual variation in health can be explained in terms of the ecological landscape and its importance for varying exposure to health risks due to factors such as environmental pollution, climate, risk of accidental injury or death, or housing quality which may invoke community-level measurements.
The notion of community-level measurement is established on the premise
that factors operating at the level of communities may affect individual-level
health outcomes. For instance, certain geographic factors operating
at the level of communities may profoundly affect infant health quite independently
from maternal factors. Such factors may include environmental pollution,
geographical distance to a health care facility, etc. It is also
known that low birth weight, high infant mortality and other infant health
problems tend to be concentrated in certain geographical areas, like towns
or neighborhoods. For example, the study conducted by Roberts (1997)
to examine the neighborhood social environments and the distribution of
low birthweight in Chicago suggested that several community characteristics
associated with poverty are negatively associated with low birthweight.
The neighborhoods or communities that people live have structural differences, which can significantly influence health outcome. This structural difference is believed to have come about as a result of the de-industrialization of the U.S. economy, the shift of jobs from cities to suburbs, and the flight of minority middle-class families from the inner cities that led to severe social dislocations in some urban neighborhoods (Wilson, 1987). This phenomenon left some communities lacking the institutions, resources, and role models necessary for success in a post-industrial society. During the past several decades, poverty in the United States has become spatially concentrated in certain neighborhoods especially those in the urban area, and clustered with other indicators of disadvantage.
Neighborhoods as Spatial Units of Analysis
Conceptually, neighborhoods and communities are the immediate social
context in which individuals and families interact and engage with the
institutions and societal agents that regulate and control access to community
opportunity structures and resources. Neighborhoods are spatial units,
associational networks, and perceived environments. A key issue in
research on neighborhoods and communities as contexts for development is
how to conceptualize and measure the geographic and/or social units used
to define and circumscribe them. Insofar as neighborhood has a geographical
referent, its meaning depends on context and function. The relevant
units vary by behavior and domain, and they depend on the outcome or process
or interest (Furstenberg 1993). For some purposes, the relevant neighborhood
is the block on which an individual or family resides; for other purposes,
it is the group of blocks immediately surrounding the residence; for still
others, it encompasses a wide physical area that includes shopping areas,
schools, and community facilities. The boundaries of neighborhoods
and communities as social areas defined by interaction patterns also vary,
depending on the object of interest. Despite the elusiveness
and geographical imprecision of the neighborhoods concept, research indicates
that neighborhoods operate as significant constraints on parents approaches
to and strategies of family management (Furstenberg 1993) and on childrenÆs
and adolscentsÆ economic and social paths.
According to Brooks-Gunn et al (1997), research on neighborhood and community influences on child development has been hampered by the absence of data combining information at the individual, family, and neighborhood/community levels. The measures that are typically available in studies of neighborhood contextual effects, such as tract-level census data, are relatively remote from perception and action, and therefore make strong linkages between neighborhood characteristics and outcomes of the inner-city poor unlikely. More proximal characteristics of the neighborhood, at the level of its social organization (Sampson and Groves 1989) and institutional functioning (Health and McLaughlin 1993), are more difficult to obtain and often require community study or ethnographic observation, but they are likely to yield more powerful linkages. The strongest linkages between neighborhoods and individual outcomes should logically include not only measures of the objective characteristics of neighborhoods but also characterizations of the perceived neighborhood - its norms, opportunities, barriers, dangers, models, controls, pressures, and supports as seen by its residents (Brooks-Gunn et al 1997). More conceptual work is needed to identify the optimal units for study in a longer-term research agenda, as well as the structural, demographic, social, and cultural processes that need to be assessed.
At present, researchers often must use administrative units for which data are readily available to examine variations for a large number of areas. Although administrative units, such as census tracts and block groups, are imperfect proxies for the concept of local community (Brooks-Gunn et al 1997), they generally possess more ecological integrity than cities or SMSAs, and they are more closely linked to the causal processes assumed to underlie the outcomes of interest. Support for the use of block groups and census tracts as measures of neighborhoods is provided by research undertaken by the Denver Neighborhood Study to evaluate the construct validity of various approaches to identifying appropriate neighborhood units for the analysis of neighborhood effects (Brooks-Gunn et al 1997).
An important measurement issue in research on community and neighborhood influences is whether to use measures of single neighborhood characteristics or construct multivariate indices of underlying dimensions of neighborhood organization. The case for using single variables as predictors has been based on the greater ease of interpreting the results and on the presumed greater ease of identifying policy-manipulable conditions (Jencks and Mayer 1990). The neighborhood characteristics available in census data, however, may be distal markers or indicators for the processes that would need to be targeted through policy interventions. Moreover, the high intercorrelations among neighborhood characteristics suggest that the interpretation of analyses employing single neighborhood variables may be misleading. At least two approaches to the use of multivariate indices of neighborhood disadvantage exist. The approach of developing an index of cumulative risk is consistent with some research on risk and resilience suggesting that the number of risk factors may be more important for development than the precise nature of the risk factors (Sameroff et al 1993). The approach of examining the effects of particular neighborhood risk factors is consistent with social disorganization research, which has shown that communitiesÆ specific structural and compositional characteristics differentially affect community-level social processes and outcomes (Sampson and Groves 1989). According to Brooks-Gunn, Duncan, and Aber (1997), the neighborhood characteristics that might have association with child health outcomes include: income, human capital, ethnic integration, social capital, social disorganization, and safety.
Neighborhood Socioeconomic Factors
It is true that the place where a person lives is an important part of his/her environment. It is also true that individuals that share a particular characteristic (especially a socioeconomic one) that relates to infant health tend to cluster in some areas. Things like transportation availability, street safety, or access to health care affect all people living in a particular neighborhood independently of their, say, educational attainment or income. Furthermore, living in a particular neighborhood can shape people's expectations, their self-perceived effectiveness to change their lives and their view of the world.
Several researches have shown that neighborhood social economic status (SES) is one of the most important characteristics associated with infant health outcomes. Previous studies confirmed that socio economic factors such as income, poverty level, housing value and age of housing are associated with low birth weight and lead poisoning among infants. Neighborhood income is, typically assessed in terms of neighborhood poverty and neighborhood affluence using census-tract data. Neighborhood poverty is perhaps one of the most widely investigated dimensions of neighborhoods because residence in an impoverished neighborhood has implications for child-care settings (Brooks-Gunn and et al, 1997). Research suggests that the concentrations of poor and affluent neighbors have differential effects on child health outcome and development. Public health research related to community-level factors, have shown that adverse birth outcomes such as low birth weight, fetal growth ratio, and gestational age are also differentially distributed by neighborhood.
The neighborhood socio-economic factors that are associated and shared
with both Low birth weight and lead poisoning among infants, particularly
those that will be addressed in the analysis, are income, poverty level,
and housing value. The study conducted by Roberts (1997) to examine the
socioeconomic precursors of disparities in maternal health by measuring
the association of nine neighborhood-level indicators of social phenomena
with low infant birthweight indicates that socioeconomic status and economic
hardship were positively associated with low birth weight. The study
conducted by Lanphear et al (1998) to identify community characteristics
associated with children having elevated blood lead levels ( 10 mug/dL)
shows that lower housing value, housing built before 1950, higher population
density, higher rates of poverty, lower percent of high school graduates,
and lower rates of owner-occupied housing were associated with increased
risk of elevated blood lead levels in children. The other neighborhood
socioeconomic factors that are associated either to low birthweight or
lead poisoning among infant are age of housing which is directly associated
with lead poisoning, and location of health care providers (access to health
care) which is directly associated with low birthweight. The study
conducted by Recknor et al (1997), interstingly, indicates that Less than
adequate use of prenatal care may reflect an increase in risk factors contributing
to not only low birth weight but also to lead exposure in infancy.
The study also revealed that low birth weight was related to high blood
lead levels. The other findings of this study point to the fact that intrauterine
lead exposure, which is known to reduce birth weight, may contribute to
measured blood lead levels at first screen. Alternatively, low birth
weight may increase lead absorption and retention in infancy or may increase
risk of lead exposure.
Although infant health and infant mortality are affected by characteristics of the mother, community-level characteristics also may indirectly or directly affect infant health and infant mortality. Some examples of both individual- and community -level characteristics are discussed below.
The individual-level characteristics could be genetic, behavioral, socio-demographic or socio-economic. For example, a mother can transmit genes that predispose a child to diabetes. Although fetal growth is primarily determined by the availability of, delivery to, and utilization of nutrients by the fetus, multiple etiologic processes involving genetic and epigenetic factors, such as maternal nutrition, uteroplacental hemodynamics, endocrine alterations, and placental pathophysiology, may lead to fetal growth disorders (Feldman 2000). Researchers have suggested that responses of the neuroendocrine axis to psychosocial factors during pregnancy may affect one or more of these processes and thereby contribute to fetal growth restriction and low birth weight. The major maternal characteristics associated with low birthweight are cigarettes, alcohol, poverty, poor nutrition, poor psychosocial support, and inadequate prenatal care, which often are associated with drug use. Maladaptive health behaviors such as smoking, substance abuse, and poor weight gain during pregnancy are associated with increased rates of prematurity and low birth weight LBW, and it has been reported that these behaviors are more prevalent among stressed women (Copper and et al 1996). Smoking or cocaine use during pregnancy is a behavior that increases the frequency of low birth weight (defined as weight <2500 g). Cigarette smoking and cocaine use by pregnant women continues to be a significant public health problem especially among the urban poor. The majority of fetuses exposed to cocaine are also exposed to other toxins, including maternal cigarette smoke (Dempsey and et al 2000). Reported maternal and fetal effects of maternal cigarette smoking and of maternal cocaine use are very similar and include fetal growth retardation, spontaneous abortions, premature labor and delivery, placenta previa, placental abruption, sudden infant death syndrome, and cognitive and behavioral deficits in children (Forman R, Klein J, Meta D, Barks J, Greenwald M, and Koren G 1993). Compared with fetal cocaine exposure, the deleterious effects of maternal cigarette smoking on the fetus are unequivocal, because the associations have been found repeatedly in large epidemiologic studies (Fried PA and et al 1997, Richardson GA and et al 1996, Weitzman M 1992). Hypertonia has been cited as the most common reason for referral of cocaine-exposed infants to a pediatric neurologist (Chiriboga and et al, 1995). Previous reports also have found an increased incidence of hypertonia among infants of smokers (Chiriboga et al, 1995). In the 1980s maternal smoking contributed to between 17% and 26% of LBW in the United States (James M. Lightwood; Ciaran S. Phibbs; Stanton A. Glantz). LBW infants are admitted to neonatal intensive care units (NICUs) at a higher rate than normal birth weight infants, and are more susceptible to illnesses, such as lower respiratory tract infections. As a result, LBW infants, on average, require more expensive care than normal birth weight infants. Existing estimates of the mean excess direct medical cost per live birth because of a maternal smoking vary widely, from $200 to $1000 per live birth (in 1995 dollars) to a pregnant woman who smokes (Aligne, 1997). The race and age of the mother can affect infant health mostly through social and economic conditions. The economic and social conditions of the mother such as education, income, and poverty level may make access to needed services more difficult. Prior studies indicate that limited access to prenatal care or to inadequate prenatal care is related to poor birth outcome. Adequate prenatal care and improved maternal nutrition through balanced caloric or protein supplementation have been shown to lead to an overall increase in infant birth weight and to decrease the rate of low-birth-weight (LBW) deliveries in populations at risk (Brown and et al, 1996). Psychosocial factors such as stress, anxiety, depression, mastery, and self-esteem have been associated with increased rates of prematurity and low birth weight (LBW). The findings of the study conducted by Feldman and et al (2000) suggest that women with more years of education and married women have greater access to social and dispositional (eg, mastery, optimism, and self-esteem) resources during pregnancy and in turn have better birth outcomes. These are only examples of different ways in which innate or acquired characteristics of the mother can affect the child from an individual level.
Over the past few years, several researchers have suggested that community-level variables may provide information that is not captured by individual-level variables. Some of the individual level characteristics such as education, income, poverty level, access to health care, housing value, and age of housing when aggregated at census tract level can be used as community level characteristics. Community-level measures of socioeconomic characteristics (education, income, poverty level, and housing value) or of neighborhood deprivation have been used increasingly in the investigation of social inequalities in health and have been found to be related to mortality and other health outcomes (Diez-Roux, Nieto, Muntaner, Tyroler, Comstock, Sharhar, Cooper, Watson, and Szklo 1997). The findings of the study conducted by Dempsey et al (2000) revealed that the effects of in utero cocaine exposure and maternal smoking (which are individual characteristics) were overshadowed by the poverty and other environmental conditions (an example of community level factors) in which many of the exposed children live. The study conducted by Roberts (1997) reveals that community economic hardship and housing costs were positively associated with low birthweight, while community socioeconomic status, crowded housing, and high percentages of young and African-American residents were negatively associated with low birthweight. Another example of a community factor that have been associated with low birthweight is social support. Study conducted by Feldman (2000) shows that several types of social support (ie, family support, baby's father support, and general functional support) together predicted infant birth weight. Women with multiple types of support from different sources during pregnancy had higher-birth weight infants. Moreover, the relation between social support and birth weight held after controlling for length of gestation, suggesting that support is related to low birth weight through fetal growth processes rather than the timing of labor and delivery. Social support as an important predictor of birth weight is emphasized by the finding that it predicts birth weight independently but to the same extent as the well-known medical determinants of birth weight (i.e. availability of, delivery to, and utilization of nutrients by the fetus, substance abuse, smoking, alcohol consumption, etc) (Feldman et al 2000). Another most important community level characteristic that is related to infant health is age of housing. The age of housing is one of the most significant risk factors for lead exposure among infants. The older the house, the more likely it is to contain lead-based paint and a higher concentration of lead in the paint and children living in such housing may likely have elevated blood lead level.
The individual-level data ¢ low birth weight - are drawn from the Infant
Birth Files for 1992 to 1994 for Allegheny County by the National Center
for Health Statistics, and lead blood level data by zip codes for 1994
- 1999 from the Childhood Lead Poisoning Prevention Program.
For the Infant Birth Files, attributes were calculated for each individual
child and then aggregated to census tract level. The proportions
of low birth weight (LBW), low fetal growth ratio (FGR), and premature
infants have been calculated and aggregated to census tract level.
The community level ¢ socioeconomic data are drawn from the population
census of 1990 and the location for health care provider data was drawn
from various community directories such as the ōWhere to turn to,ō Physicians
directories from the local hospitals and HMOs and other health insurance
companies.
The estimation of the first model was based on the observations for 499 contiguous census tracts and the estimation of the second model was based on the observation of contiguous zipcodes within Allegheny County, Pennsylvania.
Spatial regression analysis was performed for two major reasons. One was to find a good match or fit between the predicted values Xb (sum of the values of the explanatory variables, each multiplied with their regression coefficient) and observed values of the dependent variable y. The other objective was to determine which of the explanatory variables contributed significantly to the linear relationship. The spatial regression analysis included measures of fit, the coefficient estimates, standard errors, t-test values and associated probability of the estimated spatial models. Three major classes of test were applied to test the models. These three major specification tests are relevant particularly in terms of model validation. The first class was applied to test the presence of spatial effects, i.e., tests for spatial dependence and spatial heterogeneity. The second class of test was applied to test the extent of spatial effects, in particular, the extent of spatial dependence as reflected in the lag length included in spatial process models. The third class of test was applied to determine the structure of spatial dependence, as reflected in the choice of a spatial weight matrix. According to Anslen (1996), tests on non-nested hypotheses are particularly appropriate in this context. The three types of tests can be illustrated by means of the following general specification Y= g(y,r) + Xb + Î. Î= h(Î,l) + m. Where y is a N by 1 vector of values for a dependent variable, observed across spatial units, g(y,r) is a function which expresses the spatial dependence among the y, with parameters r, X is a set of exogenous explanatory variables with associated parameters b, and Î is a disturbance term. The disturbance term itself is potentially structured as well, formalized in the function h(Î,l), with parameters l. Typically, both functions g and h are linear weighted sums, obtained from the multiplication of a spatial weight matrix W with the vector of observations on y (or Î). The goal of the first type of specification test, on the existence of spatial effects, was to determine whether the g(y,r) or h(Î,l) are relevant. The goal of the second type of test, on common factors, was to address the length of the spatial lag, i.e., the spatial extent of the dependencies encompassed in g(y,r) or h(Î,l). More specifically, this test was an attempt to find how many powers of W should be included in the functional specification. The goal of the third type of test, on non-nested hypotheses, is to investigate the structure of spatial dependence incorporated in g(y,r) or h(Î,l), i.e., the structure of the W itself.
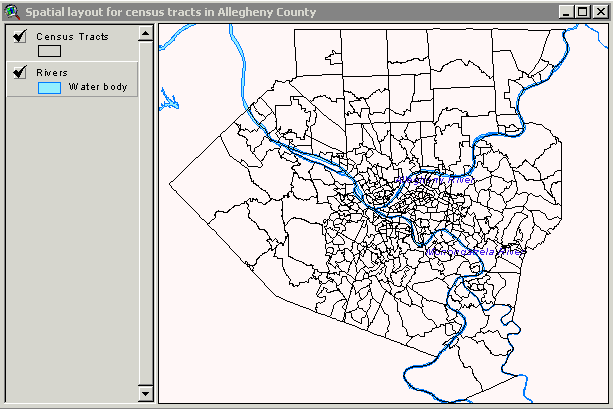
Map 1 Spatial Layout for Census Tacts in Allegheny County
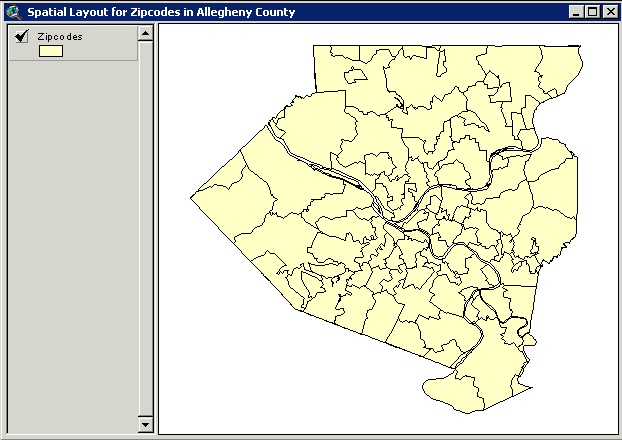
Map 2 Spatial Layout for Zipcodes in Allegheny County
Regression analysis was performed on several models to identify a model
with the best fit, based on ordinary least squares estimation. The model
shown on table 1 had the highest adjusted Ra2
of 0.5712 and did not increase when additional variables were added . The
other alternative set of measures of fit computed for this model, the Akaike
Information Criterion and Schwartz Criterion, had the lowest value indicating
that this is the best model. This result shows a strong linear relationship
between the dependent variable (low birth weight) and the explanatory variables
(pre-term, unemployment, poverty level, alcohol consumption, and smoking
during pregnancy). This result also shows the extent to which the predicted
values match the observed. The estimated coefficients for this model also
are significant at p = 0.05 (see table 1). Test for the presence of spatial
autocorrelation in the error term based on the Moran' I statistics, Lagrange
Multiplier, and Robust LM computed for the residuals are significant at
p = 0.05. With regard to the test of multicollinearity of this model, the
multicollinearity condition number of 5.665 is very low which indicates
a very low correlation between the observations for the explanatory variables
included in the regression specification. The test for normal error distribution
is very significant at p = 0.05 for this model.
Table 1 Estimated Coefficients for Model 1 (Dependent variable:
Low birth weight)
| VARIABLE | COEFF | S.D. | t-value | Prob |
| Preterm | 0.526186 | 0.0342963 | 15.342362 | 0.000000 |
| Unemployment | 0.00593166 | 0.00278549 | 2.129489 | 0.033709 |
| PC Below Poverty | 0.0289343 | 0.0128118 | 2.258415 | 0.024356 |
| Per. Alcohol | 0.115069 | 0.0559043 | 2.058315 | 0.040085 |
| Per. Smoke | 0.0638328 | 0.0137121 | 4.655210 | 0.000004 |
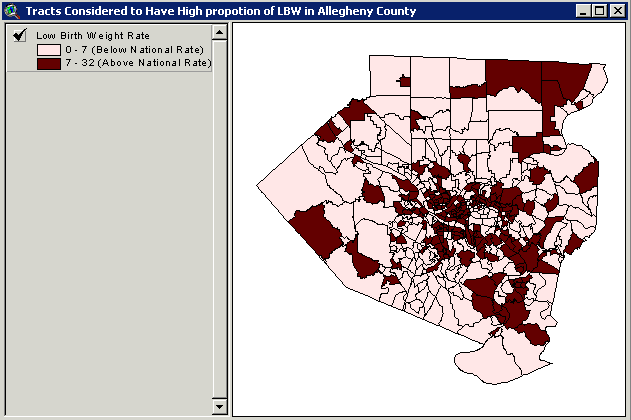
Maps
3 and 4 show census tracts within Allegheny County that are considered
to have high proportion of low birth weight both observed and predicted
values, respectively.
Map 3 Census tracts within Allegheny County that are considered to have high proportion of low birth weight
Map 4 Census tracts within Allegheny County that are considered to have predicted high proportion of low birth weight
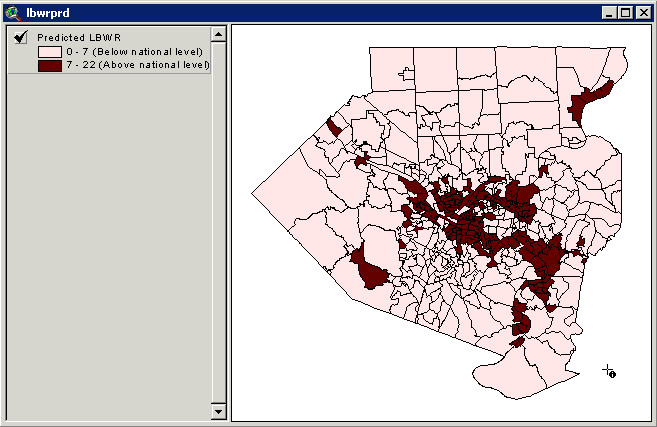
The second model predicts areas with high rate of elevated blood lead level >= 10 ug/dl as defined by family median income, housing median value, families below poverty level, education level, and age of housing variables.The final model showed strong linear relationship between the dependent variable (elevated blood lead level) and the explanatory variables (families below poverty level, education level, and age of housing). The adjusted Ra2of 0.5262 is an indication of best fit.The estimated coefficients for the model are significant at p = 0.05 as shown on table 2.
Table 2 Estimated Coefficients for Model 2 (Dependent variable:
Blood lead level >= 10 ug/dl )
| VARIABLE | COEFF. | t-value | Prob |
| Poverty level | 0.563 | 3.911935 | 0.000207 |
| Education | 0.0047 | 2.952381 | 0.004272 |
| Year House Built | 0.2058 | 3.235403 | 0.001846 |
Test for the spatial dependence or presence of spatial autocorrelation
in the error term based on the MoranÆ I statistics is significant at p
= 0.05 as shown below.
| Test | MI/DF | Value | Prob |
| Moran's I | 0.1791 | 2.539173 | 0.011111 |
| Lagrange Multiplier | 1 | 4.926813 | 0.026443 |
| Robust LM | 1 | 4.418659 | 0.035548 |
The multicollinearity condition number of 6.04 which is less than the
cut-point of 30 shows very low correlation between the observations for
the explanatory variables included in the regression specification
The test for normal error distribution is very significant at p=0.05
for this model
| Test | MI/DF | Value | Prob |
| Jarque-Bera | 2 | 10.9185 | 0.004557 |
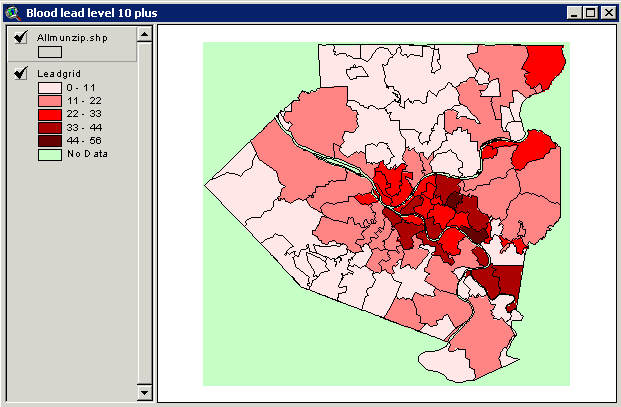
Map 4 Areas Considered to Have High Rates of Blood Lead Level >= 10 ug/dl by Zipcodes within Allegheny County
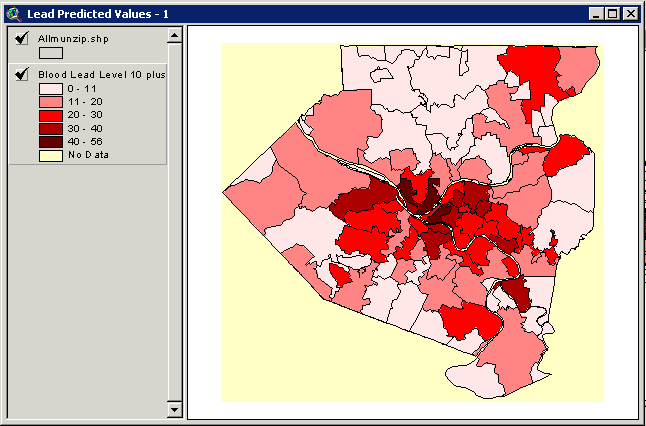
Map 6 Predicted Areas Considered to Have High Rates of Blood Lead Level >= 10 ug/dl by Zipcodes within Allegheny County
Agresti, Alan. (1996) An Introduction to Categorical Data Analysis. New York: A Wiley-Interscience Publication.
Bailey, Trevor C., and Catrell, Anthony C. (1995) Interactive Spatial Data Analysis. New York: Longman Group Limited.
Brooks-Gunn, J., Duncan, Greg J., Leventhal, T., and Aber, Lawrence J. 1997. Lessons Learned and Future Directions for Research on the Neighborhood Liveö Neighborhood Poverty New York: Russell Sage Foundation
Haywood L. Brown ; Kevin Watkins; A. Kinney Hiett; ōThe impact of the Women, Infants and Children Food Supplement Program on birth outcomeöAmerican Journal of Obstetrics and Gynecology Volume 174 Ģ Number 4 Ģ April 1996
Chiriboga CA, Vibbert M, Malouf R, et al. ōNeurological correlates of fetal cocaine exposure: transient hypertonia of infancy and early childhoodöPediatrics 1995;96:1070-1077
Cressie, Noel A. C. (1993) Statistics for Spatial Data. Rev. Editon. New York: A Wiley-Interscience Publication
Cressie, Noel A. C. (1991) Statistics for Spatial Data. New York: A Wiley-Interscience Publication
Connor, S J., Thomson, M C., and Williams, J B.ōThe use of low-cost remote sensing and GIS for identifying and monitoring the environmental factors associated with vector-borne disease transmissionöGIS for Health and the Environment Proceedings of an International Workshop held in Colombo, Sri Lanka, 5¢10 September 1994
Rachel L. Copper; Robert L. Goldenberg; Anita Das; Nancy Elder; Melissa Swain; Gwendolyn Norman; Risa Ramsey; Peggy Cotroneo; Beth A. Collins; Francee Johnson; Phyllis Jones; Arlene Meier;ōThe preterm prediction study: Maternal stress is associated with spontaneous preterm birth at less than thirty-five weeks' gestationöAmerican Journal of Obstetrics and GynecologyVolume 175 Ģ Number 5 Ģ November 1996
*Dempsey, Delia A., Hajna, Beatrice H., Latal l, J. Colin Partridge, Sarah N. Jacobson, William Good, Reese T. Jones, Donna M. Ferriero, ōTone Abnormalities Are Associated With Maternal Cigarette Smoking During Pregnancy in In Utero Cocaine-Exposed Infantsö Pediatrics Volume 106 Ģ Number 1 Ģ July 2000
Diez-Roux, Ana V., Nieto, Javier F., Muntaner, C., Tyroler, Herman A., Comstock, George W., Sharhar, E., Cooper, Lawton S., Watson, Robert L., and Szklo, M.ōNeighborhood Environments and Coronary Heart Diseases: A Multilevel Analysisö American Journal of Epidemiology Vol.146, No.1, 1997: 48 - 63.
Duncan, Greg J., Connell, James P., and Klebanov, Pamela K., 1997 ōConceptual and Methodological Issues in Estimating Causal Effects of Neighborhoods and Family Conditions on Individual Developmentö Neighborhood PovertyNew York: Russell Sage Foundation.
Feldman, Pamela J. PhD; Dunkel-Schetter, Christine PhD; Sandman, Curt A. PhD,
and; Wadhwa, Pathik D. MD, PhD ōMaternal Social Support Predicts Birth Weight and Fetal Growth in Human Pregnancyö Psychosom Med, Volume 62(5).September/October 2000.715-725
Frisbie, Parker W., Douglas, F., and Pullum, Starling G.ōCompromised Birth Outcomes and Infant Mortality Among Racial and Ethnic Groupsö Demography, Vol.33-No.4, November, 1996: 469-481.
ōGreenhouse effect: a trigger for new epidemics of disease?ö World Health Organization press briefing released at the Earth Summit, June 1992.
Guest, Avery M., Almgren, G., and Hussey Jon M.ōThe Ecology of Race and Socioeconomic Distress: Infant and Working-Age Mortality in Chicagoö Demography Vol.35, No.1, February, 1998: 23 - 34.
Kitron U., Michael J., Swanson J., Haramis L.ōSpatial analysis of the distribution of LaCrosse encephalitis in Illinois, using a geographic information system and local and global spatial statisticsö American Journal of Tropical Medicine & Hygiene.v.57(4):469-75, October 1997.
Krautheim K R., and Aldrich T E.ōGeographic information system (GIS) studies of cancer around NPL sites.Toxicology & Industrial Health.v.13(2-3): 357-62, March-June 1997.
Lanphear,
Bruce P.; Robert, Byrd S.; Auinger, Peggy; Stanley, Schaffer J.ōCommunity
Characteristics Associated With Elevated Blood Lead Levels in Childrenö
Pediatrics
Volume 101 Ģ Number 2 Ģ February 1998
Loevinsohn, M.E.(1994) ōClimatic warming and increased malaria incidence in Rwandaö, The Lacent, v.343, p.714-718, 19 March 1994.
Lovett A A., Parfitt J P., and Brainard J S.ōUsing GIS in risk analysis: a case study of hazardous waste transportö Risk Analysis: v.17(5): 625-33, October 1997.
ōOur Planet, Our Health,ö Report by the World Health Organization Commission on Health and the Environment, April 1992.
Pearce, F.(1992) ōA plague on global warming,ö New Scientist, 19 December 1992.
Ranta J., Pitkaniemi J., Karvonen M., Virtala E.Rusanen J., Colpaert A., Naukkarinen A., and Tuomilehto J.ōDetection of overall space-time clustering in a non-uniformly distributed populationö Statistics in Medicine v.15(23): p.2561-72, December 15, 1996.
Recknor , Julie C.; Reigart, Routt J.; Darden, Paul M.; Goyer, Robert A.; Olden, Kenneth;Richardson ,Marlene C.ōPrenatal care and infant lead exposureöJournal of Pediatrics Volume 130 Ģ Number 1 Ģ January 1997
Roberts, Eric M.ōNeighborhood Social Environments and the Distribution of Low Birth weight in Chicagoö American Journal of Public Health Vol.87, No.4, April, 1997: 597 - 603.
Sampson, Robert J., Raudenbush, Stephen W., and Earls, F.ōNeighborhoods and Violent Crime: A Multilevel Study of Collective Efficacyö Science Vol.277, August 15, 1997: 918 - 924.
Selvin, S., Merrill, D.W., Schulman, J. et. al. (1988). "Transformations of maps to investigate clusters of disease." Social Science Medicine (26):215-21
Spath, Helmuth (1980) Cluster Analysis Algorithms for Data Reduction and Classification of Objects. New York: Ellis Horwood Limited
ōThe
deadly hitch-hikers,ö The Economist, 31 October 1992.