Serving the American FactFinder with TIGER Data
Authors
Ricardo J. RuizAbstract
As part of the Census Bureau's efforts to quickly disseminate census data, the Bureau developed the American FactFinder web-based application. This application uses TIGER data to provide users an easy way to select the area for which they want census data and view the data.
The Geography division is responsible for the creation and maintenance of the TIGER database. We developed the DADS System to extract the geographic data from our proprietary database and create shapefiles plus other data products. These products are being delivered to the Data Access Dissemination System staff to support the American FactFinder web-based application and the creation of census data products.
This paper describes our DADS System and provides helpful information on techniques we used to successfully develop a fully automated system.
I. Introduction
To facilitate the dissemination of data to the public, the U.S. Census Bureau built the web-based application: the American FactFinder (AFF). AFF allows users to search for products or datasets. Datasets can be correlated or tabulated. Users can build queries or select pre-defined queries to produce results to view in tables or a thematic map.
The Geography division, as guardian of the TIGER database, provides all the geographic data to support AFF. We provide geographic data for all entities or entity parts for which the U.S. Census Bureau tabulates data. This tabulation scheme is known as the Summary Levels.
II. Summary Levels
A summary level type exists for each geography entity type for which data have been tabulated. The summary level types are defined by listing entity codes in a specific order. When these entity codes are concatenated for a given record, they form a unique identifier named the Geoheader.
A record within a summary level could be for a "whole" geographic entity (e.g., SL050 County), or for a combination of entity types that can result in a partial geographic entity (e.g., SL155 County part of Place). Some of these summary levels can be ordered to provide data for a whole entity followed by data for smaller areas within the whole entity. For example, see the following summary levels:
040 State
050 State-County
060 State-County-County Subdivision
Summary level 040 provides data for a state. Summary level 050 provides data for each county within the state and summary level 060 provides data for each county subdivision within each county within the state. If you aggregate the area measurements for all the 060 records for a given county, the results should match the area measurements for the county.
This example works well because states are 100% covered by counties or county equivalents and counties are 100% covered by county subdivisions. But, how do you deal with less than 100% coverage? This is where remainder records are used.
A remainder record serves as a place holder for an area not covered by the geographic entity of the summary level type in question. Not all summary level types require a remainder record. For example, see the following summary levels:
700 State-County-Voting District/Remainder
710 State-County-Voting District/Remainder -County Subdivision
720 State-County-Voting District/Remainder -County Subdivision-Place/Remainder
730 State-County-Voting District/Remainder -County Subdivision-Place/Remainder -Census Tract
Not all counties participated in the Voting District Delineation program. Those who did not, get a remainder record which covers the whole county. This is necessary to be able to create summary level 710 records for that county. Also for summary level 720, a remainder record is created for the area of a county subdivision within a voting district within a county that covers any area not covered by a valid place. The voting district and place remainder records allow us to provide data for all the census tracts in a county even if the county does not contain voting districts or it is not 100% covered by places.
III. Requirements
We were required to provide geographic data to support the AFF in the form of non-spatial and spatial products.
A. Non-Spatial Requirements
For non-spatial products, we provide text files consisting of attributes data for a number of summary levels. These products do not contain boundary information and may not be used to generate maps. Data for state based summary levels are provided in state level files. Data for summary levels that contain data that may cross state boundaries are provided in a National file.
There are two types of non-spatial products:
1. Geobucket Files
Geobucket files consist of summary level records not sort for a number of summary levels. These records are used by the AFF as index information to the spatial data.
2. Data Public Product (DPP) Files
DPP files consist of summary level records for a number of summary levels sorted in a specific order. Summary levels are grouped and ordered to provide all summary levels records for geographic entities sequentially. That is, all relevant summary levels for one entity are listed before the same summary level types are repeated for the next entity. DPP files are the bases for all tabulated data public products.
B. Spatial Requirements
For each geographic entity tabulated during the census 2000, AFF requires the boundaries for those entities in a spatial data file. In addition, AFF requires spatial data for feature networks such as roads, streams, and parks.
AFF uses SDE Layers stored in an Oracle database. We had the option of providing spatial data in shapefile or SDE Layer format. GEO chose shapefile format for reasons explained later. The Data Access and Dissemination System (DADS) staff in turn converts these shapefiles into SDE Layers.
Specific AFF functionality making use of spatial files for Census 2000 geographies includes:
1. Coordinate Precision
Spatial data files were required with different coordinates precision. Depending on the level of detailed required to show the boundaries, AFF uses detailed or generalized data to display the boundaries.
a. Detailed Shapefiles
Detailed shapefiles offer the greatest coordinate resolution available in our TIGER database. National and statewide shapefiles for over 50 summary levels were requested.
b. Generalized Shapefiles
Generalized shapefiles describe shapes with fewer coordinates than a TIGER file so as to produce a more compact and faster drawing file. These shapefiles are more appropriate for a regional or large-area view where the difference in precision between a generalized and a detailed file is not visually noticeable.
2. Shape Types
All geographic boundaries are provided as polygon shapes. Some are also provided as line shapes. Polygon shapes facilitate area shading and names placement within an area. Line shapes are useful for display of complex line symbols (e.g. a dash-dot line) whose pattern would be obliterated if rendered twice on a shared line segment between two polygons. Line shapes are also useful for the selective display of boundary lines, such as the suppression of boundaries along the national coastline.
The feature network files contain point, line, or polygon shapes to match how they are stored in TIGER. AFF shows features on maps to provide orienting information for viewing the boundaries of geographic entities.
IV. DADS System
The Census Bureau is constantly facing the requirement to process a large amount of data in a short period of time. AFF requirements were no different. This was our main concern. Our DADS System had to process data for all fifty states, D.C., and Puerto Rico to produce hundreds of spatial data sets and text files within a three-month period. To accomplish this task, we needed to minimize human interaction with the system. In other words, automate the process as much as possible. This was our first design requirement.
Our second concern was late minute requirement changes. AFF is a fairly new application still evolving. Last minute requirement changes had a high probability. Therefore, our second design requirement was to make the system metadata driven. That is, develop the software so that requirement changes could be implemented immediately by simply updating configuration files that drive the system.
Our third major concern was future use. We expect more requests to produce non-spatial and spatial files for years to come. Although the requests will be similar, the system will need to adjust to variations on the requests.
We had about one year to design, develop, and test the DADS System. We had to decide which technology and tools to use. Our staff had plenty of experience developing C, Java, and perl applications. Our experience using relational databases was limited but we had a few Oracle contractors on-site available. The DPP and Geobucket files consist of many aggregate data. SQL queries against a relational database make calculations for aggregate attributes easy. After consulting with our Oracle contractors, we decided to use a relational database to produce the non-spatial products. Also, our staff’s desire to gain some experience working with Oracle made the decision easy.
On the spatial side, the decision was easier to make. The requirements called for SDE Layers or shapefiles. During the Census 2000 Dress Rehearsal, a Geography division team provided SDE Layers to support AFF. The team ran into a number of problems to produce SDE Layers for some areas of the country and was unable to determine the cause or find a workaround. The team was forced to produce shapefiles for the problematic areas. Since our staff had very limited experience with ArcSDE, we decided to develop AML scripts to produce shapefiles.
In summary, these are the tools and technologies used for different parts of the DADS System:
We have five teams working on the DADS System. Teams split the work as follows:
Because different developers are working on the Non-Spatial and Spatial systems, we are able to use the resulting products from one system to QA the products for the other system. The QA System also uses TIGER/Line® and Geographic Reference files created by the Geography division as source files.
The next diagrams describe the Non-Spatial and Spatial systems.
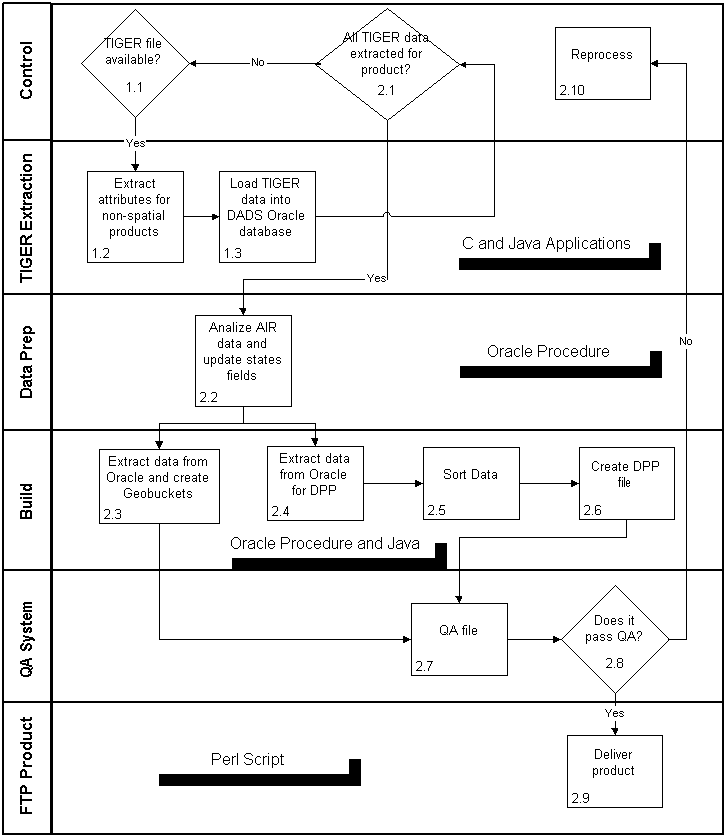
A. Non-Spatial System
B. Spatial System
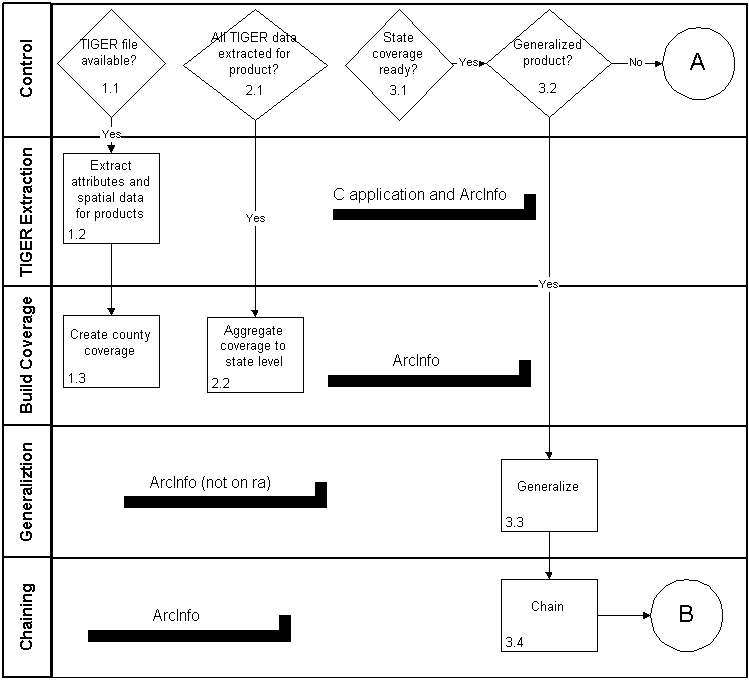
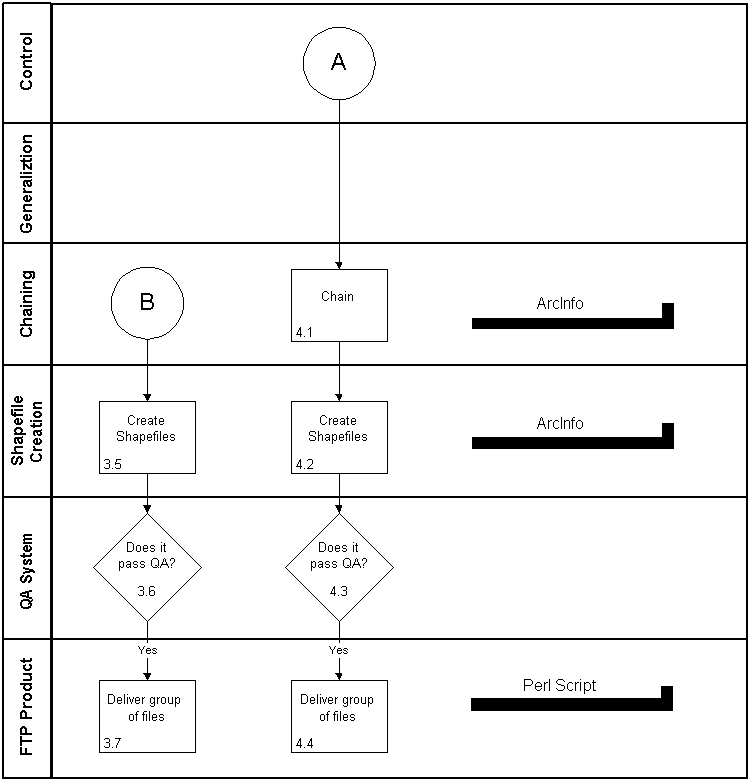
The data are extracted from our internal TIGER database into ASCII files using a metadata driven C application. The ASCII data are in turn loaded into ArcInfo coverages using the GENERATE command.
The coverages are then manipulated using various INFO commands such as REGIONQUERY, REGIONDISSOLVE, DISSOLVE, COPY, RESELECT to produce coverages with the desired summary level information. Finally, the ARCSHAPE command is used to create the shapefiles.
V. Issues
A. Non-Spatial
Performance was the main issue. Three factors that helped us reach the desired level of performance were:
B. Spatial
The development and testing of the Spatial System was not a straightforward process. During this process, we ran into various issues. Some of these issues are described below:
Unfortunately after successfully delivering national shapefiles for our first set of summary levels, we encountered the problem of exceeding the maximum number of temporary files again. There was no major difference in data size from the first set of summary levels and the second set. With the help of Esri Support, we tried various methods to solve the problem. First, we attempted to break the nation into regions, APPENDing and CLEANing each region and then APPENDing into a national file. This resulted in fewer temporary files created, but the files were huge and caused memory problems. Finally we attempted to use MAPJOIN. The MAPJOIN command had previously been dismissed as a way to aggregate the states because it caused similar errors in early testing. However, MAPJOIN was successful and we were able to deliver our second set of summary levels.
VI. Conclusion
The design and development of the DADS System took many hours of research, coding, and testing. We gained valuable experience in Oracle, ArcInfo, and system integration during this project. The DADS System was an unprecedented task for the U.S. Census Bureau’s Geography Division.
The DADS System consists of over 20 perl scripts, 10,000 lines of C code, 5,000 lines of Java code, and 7,000 lines of code in over forty AML scripts. This system will support AFF and other areas around the U.S. Census Bureau for, at least, the next five years.
VII. Acknowledgments
VIII. References
American FactFinder Spatial Files Specification – Census 2000 GeographiesIX. Author Information
Ricardo J. RuizKimberly K. Newkirk
Computer Specialist
U.S. Census Bureau
Geography Division
4710 Silver Hill Road
Mail Stop 7400
Washington, DC 20233-7400
(301) 457-1066
(301) 457-5710