Using Satellite Imagery to Map Irrigated Land
ABSTRACT
This paper presents the techniques used to map irrigated lands in the 174,000-square-mile High Plains area using Landsat 5 imagery. Eighty scenes from summer and early spring (nominal date 1992) were used. The study area was subdivided into nine regions based on similar environmental characteristics. To remove spectral overlap, only the agricultural areas that were defined by the National Land Cover data set were used for processing. The scenes were processed using a band-ratio method to create a brightness theme that enhanced the vegetation signature. A brightness value was selected as the threshold between representing irrigated and nonirrigated land. Overall, the weighted percentage of pixels that were classified correctly when compared to approximately 1,000 square miles of ground-reference data ranged from 77.5 to 79.8 percent. Comparisons were made with 1980 Landsat irrigated-lands data to produce change maps.
INTRODUCTION
In 1998, the High Plains Regional Ground-Water (HPGW) study began a water-quality study of the High Plains aquifer as part of the U.S. Geological Survey (USGS) National Water-Quality Assessment (NAWQA) Program (Gilliom and others, 1995). The HPGW study area encompasses 174,000 square miles (mi2) in the central United States and includes parts of Colorado, Kansas, Nebraska, New Mexico, Oklahoma, South Dakota, Texas, and Wyoming (figure 1).
 Figure 1. Location of the
High Plains Regional Ground-Water study.
Figure 1. Location of the
High Plains Regional Ground-Water study.
The principal geologic unit of the High Plains aquifer is the Ogallala Formation, which consists of a sequence of unconsolidated clays, silts, sands, and gravels of Miocene to Pliocene age. The HPGW study requires detailed and current information about the location of irrigated land for analyzing water-quality results with respect to land use, selecting new study sites, and modeling ground-water vulnerability. The only pre-existing information on irrigated land for the entire High Plains area is approximately 20 years old (Thelin and Heimes, 1987), and only provides the percentage of irrigated land in 4-square-kilometer (km2) grid cells across the High Plains, not the actual locations of irrigated fields.
To update the data on irrigated land, 40 summer and 40 spring Landsat Thematic Mapper (TM) images (nominal date 1992) were acquired from the National Land Cover Data (NLCD) set (U.S. Geological Survey and U.S. Environmental Protection Agency, 2002) and processed using a band-ratio method (band 4 divided by band 3) to enhance the vegetation signature. The study area was divided into nine subregions on the basis of similar environmental characteristics, and a band-ratio threshold was selected from imagery in each subregion that classified irrigated and nonirrigated land. The classified images for each subregion were mosaicked to produce an irrigated-land map for the study area. This paper presents the methodology and results to classify and map irrigated land in the High Plains using satellite data acquired for a nominal date of 1992. Additionally, a comparison was made between the amount and location of irrigated land determined in the early 1980's (Thelin and Heimes, 1987) with estimates made from the 1992 data to determine changes in the amount and location of irrigated land. To process and classify irrigated land in the HPGW study area, a combination of ERDAS Imagine and Esri ArcGIS software was used.1
1 The use of trade names is for descriptive purposes only and does not imply endorsement by the U.S. Government.
METHODOLOGY
File Conversion
The imagery data were received from EROS Data Center as a band sequential (BSQ) generic binary format containing 4 bands (3, 4, 5, and 7). Two files were associated with each image: The compressed image data file (.IMG file; not to be confused with the .IMG format for ERDAS Imagine) and the georeferencing information file (.PRT file). The data were imported into ERDAS Imagine and converted to an Imagine .IMG format using the Import menu and information about number of rows and columns in the data set from the .PRT file. To import the bands in the order required for the band-ratio method of classification, the bands were reordered during the import process to 7, 5, 3, and 4. The imported .IMG file was then georeferenced using information from the associated .PRT file that came with each image.
Subsetting the Data
Because the satellite sensor can record differences in soil moisture, plant health, atmospheric conditions, and many other factors (Goddard Space Flight Center, 2002), the imagery was divided into nine subregions (figure 2).
 Figure 2. Location of subregion boundaries.
Figure 2. Location of subregion boundaries.
The extent of the subregions was based on a visual inspection of several overlays of environmental data sets such as crop patterns, precipitation, and ecoregions and also to limit file size for processing purposes. Subsetting the data would help ensure that the data being processed in a given subregion would have similar spectral signatures and that the selected threshold to distinguish irrigated from nonirrigated land would be appropriate within that subregion. ArcGIS was used for the overlay process and for creating the polygon boundaries for the nine subregions. The polygon boundaries were then opened in Imagine to subset the imagery for processing.
Applying the Agricultural Mask
In addition to the unclassified raw TM data, the classified NLCD data for the same scenes were retrieved. Because the Multi-Resolution Land Characteristics consortium had already spent a great amount of time classifying the TM data into land-cover classes with the use of extensive ancillary data, it was decided that the NLCD agricultural classes would be used to mask out pixels in the imagery that were not considered agricultural land and could interfere with the results of the ratio (such as the spectral overlap between riparian pixels and irrigated agriculture pixels). Not all rangeland or riparian pixels were masked out completely, however, due to classification errors in the NLCD. The masking procedure produced image files containing mainly agricultural pixels--the subject of the study (figure 3).
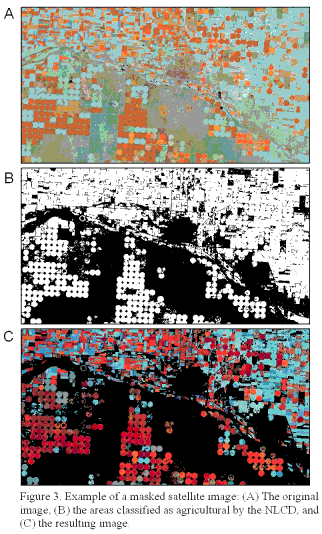 Figure 3. Example of a masked image: (A) The original image, (B) the areas classified as agricultural
by the NLCD, and (C) the resulting image.
Figure 3. Example of a masked image: (A) The original image, (B) the areas classified as agricultural
by the NLCD, and (C) the resulting image.
Calculating the Band Ratio
Multispectral data can be transformed, or enhanced, to generate new sets of image components or bands. The new band or bands represent an alternative description of the original data that may enhance certain features not formerly visible. Image arithmetic, such as a ratio of pixel brightness values (digital numbers [DN]), can reduce effects of topography, create a vegetation index, or enhance differences in the spectral characteristics of rocks and soils (Richards, 1993). A band ratio was used in this study and was defined as the TM near-infrared band (band 4) divided by the visible-red band (band 3), which created a vegetation index. Each image in the nine subregions was processed using this ratio.
The resulting files were composed of a single grayscale band with irrigated agriculture pixels indicated as bright white pixels and all other variations of vegetation a range of gray (figure 4).
 Figure 4. Example of a ratio-classified image.
Figure 4. Example of a ratio-classified image.
However, pixels representing riparian areas or other wet, green vegetation that were not masked out also appeared bright white. The next step was to determine the best threshold to apply to the ratio-classified image to classify irrigated land.
Signature Collection
Applying a threshold to an image is another method of categorizing an image. In this case, the reason for choosing a threshold for the image was to create a binary file containing values of 1 to represent irrigated agriculture and 0 to represent nonirrigated agriculture. This file could then be input into a formula to calculate the number of irrigated pixels per unit area.
The pixel brightness values (DN value) for each of the ratio-classified images generally ranged from 0.031 to 24.793. The higher the number, the brighter/whiter the pixel and the more likely the pixel represented irrigated agriculture. Brightness values for nonirrigated land ranged from an average minimum of 1.426 to an average maximum of 2.873. Brightness values for irrigated land ranged from an average minimum of 2.386 to an average maximum of 7.767. The ideal threshold value would separate the riparian and nonirrigated agriculture pixels from irrigated agriculture pixels.
To determine the best threshold, several samples of DN values were collected from areas that the analyst thought to be irrigated (center-pivot irrigation systems) and areas thought to be nonirrigated (Conservation Reserve Program (CRP) land or fallow fields). The samples were collected using a seed tool to select a pixel in the area of interest, and the tool then selected surrounding contiguous pixels that were within a specified geographic distance and/or a specified spectral distance (similar brightness). The analyst then used the minimums, maximums, means, and ranges of the various samples of DN values to determine the best threshold value that would separate brighter, irrigated agriculture pixels from darker, nonirrigated agriculture pixels.
The statistics (minimum, maximum, mean, and range of DN values) were gathered solely from the ratio-classified image. There are certain guidelines to consider when using statistics to threshold or create classes in an image. Generally, 50 samples per class (land-cover type) is a good balance between statistical validity and practicality (Congalton and Green, 1999).
The statistics were used to determine how to group the pixels in the ratio-classified image into their respective land-cover types. The brightness ranges for each sample were plotted on a graph to determine where along the brightness scale the various samples would group for each of the classes (irrigated and nonirrigated) (figure 5).
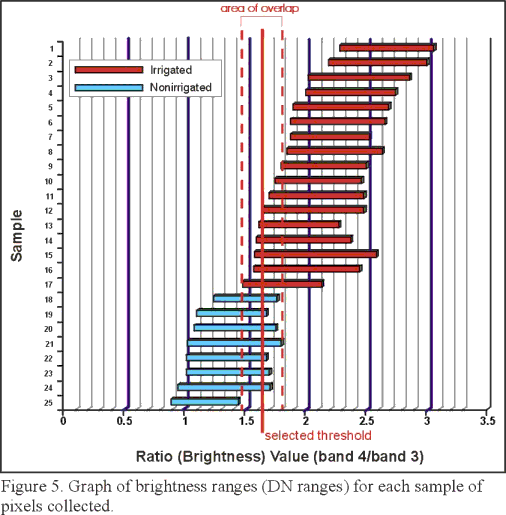 Figure 5. Graph of brightness ranges (DN ranges) for each sample of pixels collected.
Figure 5. Graph of brightness ranges (DN ranges) for each sample of pixels collected.
Samples from the brighter pixels, considered irrigated agriculture, have different minimums, maximums, and ranges but generally overlap each other in the graph. Samples of darker pixels, considered nonirrigated agriculture, also grouped together and have noticeably lower ranges of DN values but still overlap slightly with the brighter pixel samples. The ideal DN ranges would not overlap, but in this study this never occurred. Any threshold value chosen would always misclassify some nonirrigated pixels as irrigated and some irrigated pixels as nonirrigated; therefore, the threshold was chosen that achieved the best balance between misclassified irrigated and nonirrigated pixels.
Selection of Threshold Value
Thresholds will be different for different image dates because a pixel's DN value changes temporally due to changing soil conditions, vegetation health, leaf area, soil moisture, and atmospheric effects. The goal for selecting the best threshold is to work towards achieving 100 percent of the pixels that are irrigated agriculture represented by a single value and 100 percent of nonirrigated pixels represented by a second single value (no spectral overlap between irrigated and nonirrigated signatures). This goal is usually not possible in reality; therefore, a threshold was selected that was in the middle of the overlap area between the minimum value of the brighter group of samples (irrigated) and the maximum value of the darker group of samples (nonirrigated) (figure 5). This threshold value would misclassify some nonirrigated pixels as irrigated (overestimate error) and some irrigated pixels as nonirrigated (underestimate error); however, the threshold was chosen that would best balance the overestimate and underestimate errors.
The minimum and maximum DN values of the irrigated pixels and those of the nonirrigated pixels were used in a conditional statement model to threshold all the irrigated agriculture into one class and all other nonirrigated agriculture into a separate class. An Imagine model was created to apply a conditional statement to the ratio-classified image. Here is an example of the type of conditional statement used in the threshold process: CONDITIONAL { ( image GE 0 AND image LE 0.767) 0, (image GE 0.768 AND image LE 1.98) 1)}. This statement resulted in an image where all the DN values greater than or equal to 0 and less than or equal to 0.767 are recoded as "0" and all the DN values greater than or equal to 0.768 and less than or equal to 1.98 as "1". The recoded image has values that are either 0, representing nonirrigated pixels, or 1, representing irrigated pixels (figure 6).
 Figure 6. An example of a classified image. The white areas represent irrigated land and the black areas
represent nonirrigated land.
Figure 6. An example of a classified image. The white areas represent irrigated land and the black areas
represent nonirrigated land.
The resulting recoded image was visually compared to the original composite-band image to determine what errors in classification may have occurred. It was not uncommon for an analyst to reclassify an image several times using different thresholds (mean of all minimums, mean of all maximums, mean of means, and so forth) to attempt to balance the occurrence of irrigated and nonirrigated errors (overestimate errors and underestimate errors).
Ground-Reference Information
Ground-reference information is required to calibrate the irrigated-land classification methodology and to assist in the identification of systematic errors such as classifying riparian zones as irrigated agriculture. Ground-reference information obtained for this study included crop type and irrigation status for individual fields in the requested areas. Ground-reference information was obtained for the same year as the imagery. Because scene-collection dates varied across the study area, a date index based on the year the scene was collected was created by identifying scene boundaries within the imagery. Where TM scenes overlapped, the more recent scene was chosen or the scene that appeared to have more irrigated acreage was chosen. Ground-reference information then was collected for the appropriate date. The ground-reference information was requested from the Farm Service Agency (FSA). The FSA is the branch of the U.S. Department of Agriculture (USDA) that is responsible for various farm assistance programs. As part of a farm's participation in these programs they must record on an aerial photograph of their farm what crops were grown on the fields, how many acres, and the irrigation status (irrigated or nonirrigated dryland conditions). Written and photographic information were requested from 154 counties across the High Plains. The counties were selected if they contained more than 50 percent agricultural land (based on the NLCD classification) to ensure that enough irrigated land would be included in the random selection because there is substantially more dryland farming than irrigated farming in the study area (U.S. Bureau of the Census, 1994). Additionally, it was decided that querying all 256 counties in the study area would not be possible because of time constraints. One to 10 one-square-mile sections were randomly selected in each county, depending on how much agricultural land was in the county, for the request to the FSA. Ninety percent of the data requested from the 154 counties were returned (139 counties). Each request that was returned was digitized into polygons in Imagine and ArcGIS by using the original composite-band satellite imagery as a background, and each plot of land was attributed as to the irrigation status and crop type (figure 7).
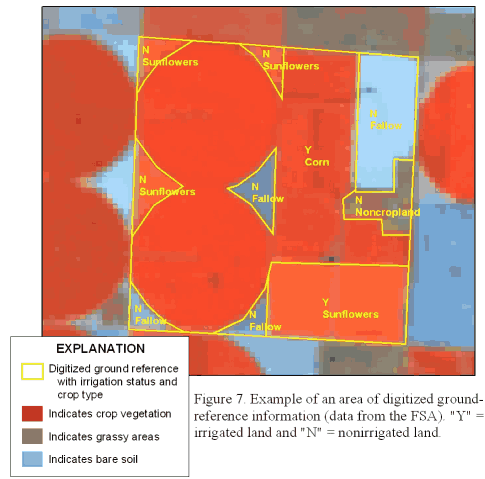 Figure 7. Example of an area of digitized ground-reference information (data from the FSA). "Y"
= irrigated land and "N" = nonirrigated land.
Figure 7. Example of an area of digitized ground-reference information (data from the FSA). "Y"
= irrigated land and "N" = nonirrigated land.
In total, approximately 11,000 polygons equal to 966 square miles were digitized for the ground reference (figure 8), or approximately 1.3 percent of all agricultural land.
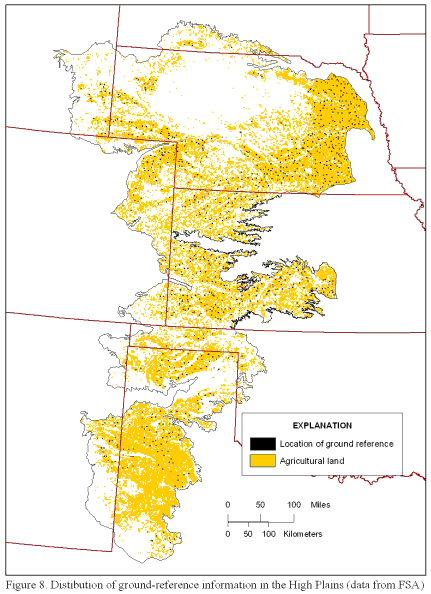 Figure 8. Distribution of ground-reference information in the High Plains (data from the FSA).
Figure 8. Distribution of ground-reference information in the High Plains (data from the FSA).
Refinement of Irrigated Land Estimates (Thresholds)
Once the initial classification was completed, the estimates of irrigated land classified by the TM imagery were refined using ground-reference information to adjust threshold values. The ground-reference information on irrigation status was used to determine the initial error estimates for the land-cover classification. The polygons in the ground-reference data set were classified as being either irrigated or nonirrigated, and this information was overlaid with the classified TM imagery to determine the initial accuracy of the classification for each scene. The error estimates were done in ArcGIS by converting the ground-reference polygons into a raster data set where irrigated areas were assigned a value of "20" and nonirrigated a value of "10". The classified image also was converted from an Imagine .IMG file to an ArcGIS raster data set where irrigated land had an assigned value of "1" and nonirrigated land a value of "0". The data sets were then added together to create an error data set with the following values: no ground reference available = 0; nonirrigated, correctly identified = 10; nonirrigated, incorrectly identified (underestimated irrigated land) = 20; irrigated, correctly identified = 21; and irrigated, incorrectly identified (overestimated irrigated land) = 11. The cell counts for each of the values were compared to the total cell count for each data set to calculate the percentage of correctly classified pixels and incorrectly classified pixels (table 1). Generally, if the initial error estimate was above 90-percent correctly classified pixels for a data set, the refinement process was not performed.
Table 1. Example of Excel table used to calculate percentage of pixels
correctly and incorrectly identified.
To refine the threshold values, 50 percent of the ground-reference polygons were randomly selected to produce a calibration data set and the remaining polygons were used to produce a verification data set. The calibration data set was used to refine the thresholds to optimize the amount of irrigated land correctly classified (percentage correct) and the amount of irrigated land correctly located. The errors and the percentage correct were then verified using the verification data set (table 2).
Table 2. Errors and associated percentage of correctly classified pixels for each subregion after calibration and verification using the ground-reference information [N/A=no irrigated land in ground-reference data set]
|
Agricultural land in subregion represented by ground reference (percent) |
||||||||
|---|---|---|---|---|---|---|---|---|
1 Weighted percentage correct = Percentage correct x agricultural land in subregion.
2 Only one county reported ground-reference information in this subregion.
The percentage correct for each subregion was weighted on the basis of the percentage of the total agricultural land in each subregion. The overall weighted percentage of pixels correctly identified by the ratio-threshold process was 77.5 percent. This number increased to 79.8 percent when the effects of subregion 2 were removed. Subregion 2 encompassed eastern Nebraska and included imagery dates from the 1992 and 1993 growing seasons; The same time period when Midwest flooding occurred and extremely wet conditions existed for many Midwestern States.
Cleaning Up the Classified Data
Because irrigated fields are not perfectly homogeneous in terms of plant health, there were pixels within irrigated land that were below the brightness threshold and were left out of the irrigated classification and appeared as holes in many fields. Conversely, many small areas of pixels and individual pixels representing nonirrigated land were above the brightness threshold and were included in the irrigated classification. These misclassified pixels were cleaned up by using a series of eliminate and fill filter passes in Imagine. First, the eliminate filter was done using a minimum area of 10 to 15 acres (approximately 49 to 74 contiguous pixels)--smaller than almost any irrigated field. Second, the fill process was used to fill in gaps in otherwise contiguous irrigated fields. The fill process was generally done using a 5 by 5 neighborhood (group of pixels) with a majority function (each pixel would be classified on the basis of the majority value of a defined set of pixels within the neighborhood). The shape of the neighborhood was changed depending on the general pattern of irrigated land; densely irrigated areas that contained many section roads were processed using a "+"-shaped neighborhood so that the roads would be preserved; irrigated areas defined largely by circular center-pivot irrigation systems were processed using a more circular neighborhood (figure 9).
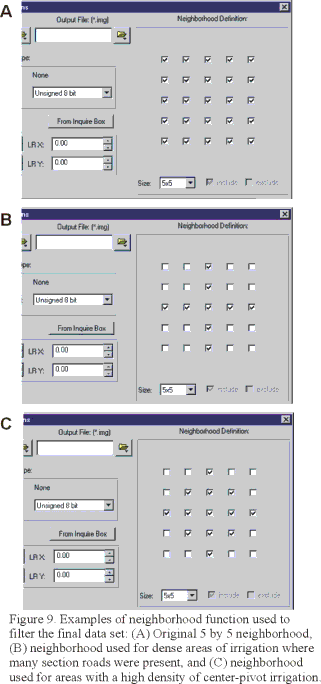 Figure 9. Examples of neighborhood functions used to filter the final data set: (A) Original 5x5
neighborhood, (B) neighborhood used for dense areas of irrigation where many section roads were present,
and (C) neighborhood used for areas with a high density of center-pivot irrigation.
Figure 9. Examples of neighborhood functions used to filter the final data set: (A) Original 5x5
neighborhood, (B) neighborhood used for dense areas of irrigation where many section roads were present,
and (C) neighborhood used for areas with a high density of center-pivot irrigation.
COMPARISON OF 1992 DATA SET TO 1980 DATA SET
To compare the present classification to the historical classification of irrigated land, the data from this study were aggregated in ArcGIS from the location of individual fields into a more coarse resolution of percentage of land irrigated in a grid cell. By overlaying a grid with 2-km by 2-km cells, a percentage of a cell that was irrigated or irrigation density was calculated for a nominal date of 1992 (figure 10).
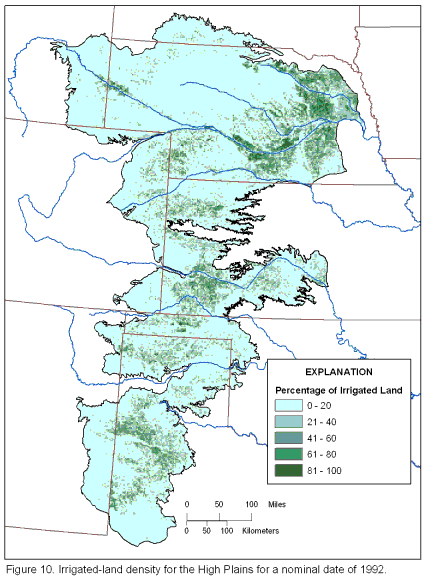 Figure 10. Irrigated-land density for the High Plains for a nominal date of 1992.
Figure 10. Irrigated-land density for the High Plains for a nominal date of 1992.
The density ranged from 0 percent irrigated land to 99 percent irrigated land. The total amount of irrigated land classified in the High Plains area was 13 million acres, which is approximately 30 percent of the total agricultural land or approximately 12 percent of the total High Plains area.
The ArcGIS grid of 2-km by 2-km cells used to represent the density of irrigated land for 1992 was then compared to a similar grid data set created by the USGS Regional Aquifer-System Analysis (RASA) for irrigated land in 1980 on a cell by cell basis. The total amount of irrigated land calculated from the 1980 RASA data was 13.7 million acres compared to the 13 million acres calculated from the 1992 imagery, a decrease of approximately 5 percent. However, 5 percent is within the precision of the 1992 estimate considering that the overall weighted percentage for correctly classified pixels was 80 percent. Although the amount of irrigated land and the general pattern of the density of irrigated land have not changed significantly, the data indicate that there are areas where the density appears to have been greater in 1980 than in 1992, as seen in the lightening of the darker green (greater density) colors (figure 11)
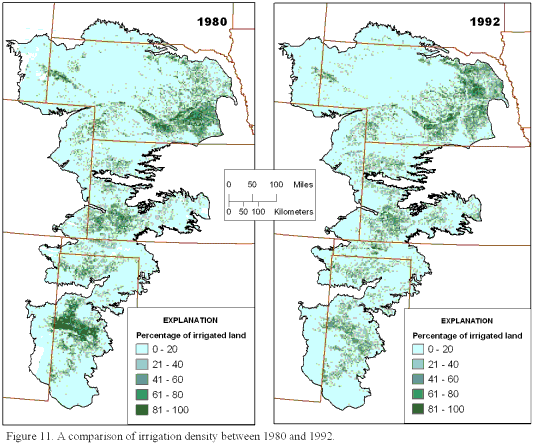 Figure 11. A comparison of irrigation density between 1980 and 1992.
Figure 11. A comparison of irrigation density between 1980 and 1992.
(for example, Panhandle of Texas). The exception is the area in eastern Nebraska where data anomalies due to flooded fields and very wet conditions have indicated artificial decreases and increases in the amount of irrigated land.
Because the grids for both data sets were exactly the same in terms of location and cell size, an ArcGIS grid representing the change in the percentage of irrigated land from the past to the present was created by subtracting the past values from the present values on a cell by cell basis. Ancillary data on water-level trends in the High Plains aquifer from 1980 to 1994 (V.L. McGuire, U.S. Geological Survey, written commun., 2002) indicate that in areas where the greatest water-level declines have taken place, the amount of irrigated land has generally decreased (figure 12).
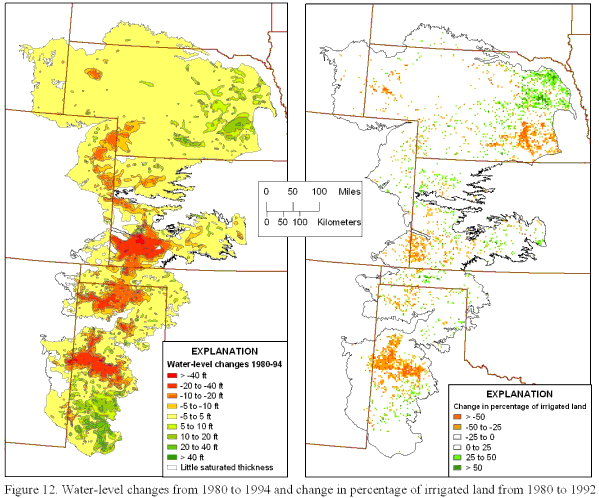 Figure 12. Water-level changes from 1980 to 1994 and change in percentage of irrigated land from
1980 to 1992.
Figure 12. Water-level changes from 1980 to 1994 and change in percentage of irrigated land from
1980 to 1992.
SUMMARY
Satellite imagery from the Landsat 5 TM sensor, nominal date 1992, was used to determine the amount and location of irrigated land in the High Plains study area. Forty scenes from the early spring months (leaf-off) and 40 scenes from the summer months (leaf-on) were obtained from the EROS data center and imported into Imagine. Each set of data was divided into nine subregions based on environmental factors and computer hardware capabilities. The extent of each subregion was defined on the basis of similar environmental factors such as precipitation, crop patterns, and ecoregions and also to limit file size for easier processing. Similar environmental factors in each subregion ensured that each subregion had similar spectral signatures. The data were further filtered using a mask of agricultural land as defined by the National Land Cover Data set so that only agricultural land was processed. This process helped eliminate any problems with spectral overlap such as a riparian zone's spectral similarity to irrigated fields. A band-ratio method of the near infrared band (band 4) divided by the visible red band (band 3) was used to enhance the signature of vegetation. The band-ratio process produced a brightness theme where healthy, green vegetation would be represented by brighter pixels and dryer, less vigorous vegetation and bare soil would be represented by darker pixels. Samples of brightness values for areas thought to be irrigated (center pivots) and areas thought to be nonirrigated (Conservation Reserve Program (CRP) land or fallow fields) were collected to determine a brightness threshold that would be the cutoff value between irrigated land (brighter pixels) and nonirrigated land (darker pixels). Ground-reference information from 139 counties equaling 966 square miles was digitized and overlain on the classified data in ArcGIS to determine initial error estimate and the percentage of correctly classified pixels. The overall weighted percentage correct for the study area was 77.5 to 79.8 percent, depending on inclusion of eastern Nebraska where there were data anomalies due to extremely wet conditions. The 1992 data set was then compared to the 1980 data set to determine the change in amount and location of irrigated land over time. The amount of irrigated land has not changed substantially from 1980 (13.7 million acres) to 1992 (13 million acres). However, the data indicate a decrease in the amount of irrigated land in areas of large water-level declines.
REFERENCES
Congalton, Russ, and Green, Cass, 1999, Assessing the accuracy of remotely sensed data--Principles and practices: Boca Raton, Fla., Lewis Publishers, 131 p.
Goddard Space Flight Center, 2002, Remote sensing tutorial, accessed June 7, 2002, at URL http://rst.gsfc.nasa.gov/Front/tofc.html.
Gilliom, R.J., Alley, W.M., and Gurtz, M.E., 1995, Design of the National Water-Quality Assessment Program--Occurrence and distribution of water-quality conditions: U.S. Geological Survey Circular 1112, 33 p.
Richards, John A., 1993, Remote sensing and digital image analysis--An introduction: New York, Springer-Verlag, 340 p.
Thelin, G.P., and Heimes, F.J., 1987, Mapping irrigated cropland from Landsat data for determination of water use from the High Plains aquifer in parts of Colorado, Kansas, Nebraska, New Mexico, Oklahoma, South Dakota, Texas, and Wyoming: U.S. Geological Survey Professional Paper 1400-C, p. C1-C38.
U.S. Geological Survey and U.S. Environmental Protection Agency, 2002, National land cover data set, accessed June 7, 2002, at URL http://www.epa.gov/mrlc/nlcd.html.