When the features in an address-geocoded database are being spatially upgraded, conflation, or the process of transferring information associated with one digital representation to another representation of the same features, is essential for maintaining links to related databases. During recent months, an improved spatial representation of the National Hydrography Dataset (NHD) has been under development. The new dataset is being developed from vector data collected at a higher resolution than the existing 1:100,000-scale NHD. Each section, or reach, of surface drainage on the NHD is assigned a unique address known as a reach code. This paper describes automated approaches being used by the USGS to conflate areal and linear reach codes to the higher resolution dataset.
Any use of trade, product, or firm names is for descriptive purposes only and does not imply endorsement by the U.S. Government.
The design and compilation of the National Hydrography Dataset (NHD) has been an ongoing effort between the U.S. Geological Survey (USGS), the U.S. Environmental Protection Agency (USEPA), and various other cooperating organizations. The NHD is a comprehensive set of geospatial vector data representing surface-water features in the United States. It includes a set of reach features delineated from the vector hydrographic data. Each reach consists of a significant segment of surface water having similar hydrologic characteristics, such as a stretch of river between two confluences, a lake, or a pond (USGS, 2000). A unique 14-digit numeric address, called a reach code, is permanently assigned to each reach delineated on the vector dataset. The Reach File database associated with the NHD was created in the 1970s and 1980s by the USEPA for performing water-quality modeling on whole river basins (Horn et al., 1994).
As intended by the USEPA, the standard reach addressing scheme has promoted data integration with the NHD. Reach delineations are stored using a route system on the linear hydrographic features depicted in the NHD. Using Arc Info's dynamic segmentation capabilities, we can link ancillary datasets permanently to the reach route system. For instance, the waterbodies assessed 305(b) and impaired 303(d) can be easily identified by delineating the parts of reaches associated with each waterbody in the USEPA Water Quality Standards (USEPA, 2000). Similarly, habitat delineations, or field sample locations, can be quickly determined through point or linear event mapping on the reach route system. Any changes to the reach system without some tracking of the modifications can destroy links to ancillary data. Thus, the stability of the reach route system directly affects the data integration capabilities and overall value of the NHD.
The currently (2002) complete version of the NHD comprises 1:100,000-scale USGS digital line graph data. Although the level of detail provided at this scale is well suited for regional studies, it does not provide the detail required for larger scale hydrographic studies. During recent months, a more detailed version of the NHD has been in development. This improved version is being compiled from 1:24,000 or larger scale vector data. Development of the higher resolution NHD includes conflation with the existing 1:100,000-scale reaches to maintain relations with ancillary datasets that are linked to reaches of the NHD.
Generally, conflation is the process of merging two or more datasets to generate a superior dataset (Saalfeld, 1993). Defined here, conflation is the process of transferring information associated with one digital representation to another representation for the same features. Specifically, reach attribution is transferred to the appropriate vectors of the higher resolution dataset. However, the higher resolution vectors do not always match with the more generalized representations depicted in the 1:100,000-scale data. Consequently, some reaches are not conflated and maintained in the NHD, and in other cases reaches are conflated but redelineated on the higher resolution linework because of incompatible feature types.
The fate of reaches that are not maintained in the higher resolution linework is tracked in a reach cross-reference table. This table identifies the new reaches, if any, that replace the old reaches. The integrity of the reach cross-reference table depends entirely on the accuracy of reach conflation.
Essentially, proper reach conflation maintains the links between the NHD and other databases. Therefore, reach conflation affects the ability to permanently integrate the NHD with other datasets. The remainder of this paper summarizes the conflation process that is implemented with the NHDCreate system. Through Arc Macro Language, Avenue, and C++ programming, NHDCreate uses the built-in geoprocessing functions of Esri's ArcInfo Workstation and ArcView 3.2 to produce high-resolution NHD from available vector hydrography data. This design, along with the widespread use of Esri software at cooperating agencies, provides an easily distributable mechanism for producing a high-resolution NHD.
Reach Delineation
To understand the conflation process, it is necessary to have a general understanding of the way reaches are delineated. For a thorough description of features included in the NHD and reach delineation rules see "The National Hydrography Dataset: Contents and Concepts" (USGS, 2000). Features in the NHD are divided into subbasins (formerly known as Cataloging Units) that generally follow drainage-area boundaries. Each subbasin contains a set of waterbodies and a drainage network. Waterbodies include areal features, such as canal/ditch, lake/pond, reservoir, stream/river, and swamp. The drainage network includes linear features having the following feature types: artificial path, canal/ditch, connector, pipeline, and stream/river. Artificial paths identify flow connections where waterbody features interrupt the drainage network (figure 1), and connectors are used to fill gaps where flow is known to exist but is not delineated in the digital lines of the source data.
This paper only addresses two of the three types of reaches that are used in the NHD: waterbody reaches and transport reaches. Waterbody reaches are composed of areal waterbody features. An individual waterbody reach is composed of all contiguous waterbodies that have the same feature type and that are not separated by some feature representing a physical barrier, such as a dam or nonearthen shore. Presently, only lake/pond and reservoir features can compose waterbody reaches in the high-resolution NHD.
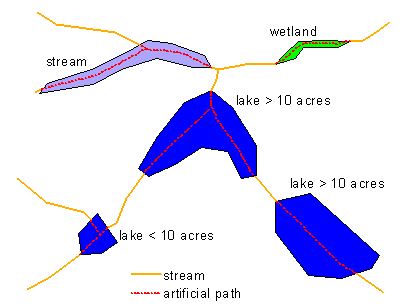
Figure 1. Sample of surface-water features.
Transport reaches are composed of linear features in the drainage network. The delineation of transport reaches follows fairly specific rules. Generally, a transport reach must have the same underlying feature type, and it must start and end at confluences in the drainage network. The term underlying is a specification used to identify a feature type for artificial paths. The underlying feature type of an artificial path is the feature type of the waterbody through which the artificial path passes. Thus, an artificial path adopts the feature type of its underlying waterbody for the purpose of reach delineation (figures 1 and 2), and transport reaches are subsequently delineated from confluence to confluence. However, a size criterion is applied to underlying feature types of lake/pond or reservoir. Where a lake/pond or reservoir waterbody is 10 acres or larger, the artificial paths in the waterbody, if any, are combined into a single reach. In many cases, this generates a branched path reach. Where a lake/pond or reservoir waterbody is smaller than 10 acres, the artificial paths in the waterbody adopt the feature type of the connected drainage features. As a result, small lake/pond or reservoir features do not affect transport reach delineation, and reaches are delineated between confluences as if the small waterbodies did not exist (figure 3).
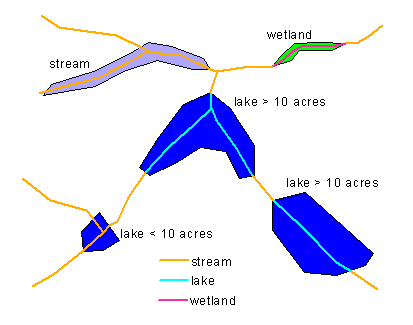
Figure 2. Underlying features identified for artificial paths.
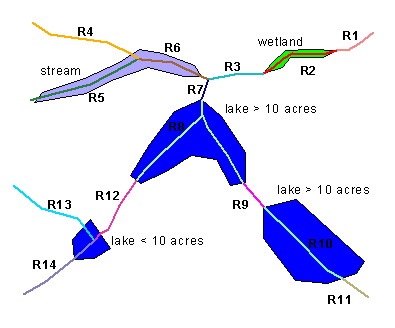
Figure 3. Transport reach delineation by confluence-to-confluence and underlying feature type.
The third type of reach used in the NHD, which is not discussed in this paper, is the coastline reach. This is a linear reach, which is not presently processed by NHDCreate but will be handled by the processing software in a similar manner to transport reaches. During the creation of higher resolution NHD, reach delineation is performed after conflation of the 1:100,000-scale reach data. Since additional features are represented in the higher resolution data, many of the conflated reaches in the higher resolution dataset do not follow delineation rules defined for the 1:100,000-scale data. However, newly created reaches on the higher resolution dataset are divided according to the delineation rules.
Conflation
Conflation of reach data consists of transferring reach codes, dates, and geographic names from waterbody and transport reaches existing on the 1:100,000-scale NHD to the higher resolution vector data. To perform this task, it is necessary to identify the vector representations in the higher resolution data that correspond with each of the reaches represented on the smaller scale data. With NHDCreate, this is a highly automated process whereby waterbody reaches and any transport reaches passing through the waterbody reaches are conflated first, and transport reaches are conflated second. To simplify discussion, the source 1:100,000-scale NHD data are referred to as the source data or dataset, and the target, higher resolution vector data are referred to as the target data or dataset.
Although conflation research suggests that some form of rubber sheeting is required to spatially match the source and target datasets (Saalfeld, 1993), to date, no rubber sheeting procedures have been applied with NHDCreate to enhance the spatial matching between the source and target datasets. The fact that the source 1:100,000-scale datasets originally were compiled as a generalization of the target 1:24,000-scale data directly affects this situation (USGS National Mapping Division, 1994).
Waterbody reach conflation. Automated conflation of waterbody reaches and the transport reaches passing through them is performed with NHDCreate through the following steps:
Upon completion of this process, two queues are set up for automating the review and interactive update of reach data that were not conflated or possibly conflated improperly. The queue for reviewing possibly improper transfers consists of those source reaches that had multiple target polygon matches but were then reduced to the largest polygon.
Transport reach conflation. Automated conflation of transport reaches is performed through the following steps:
Automatic Conflation Summary
Reach conflation results completed with NHDCreate were compiled to identify the percentage of successful automatic reach transfers. A successful automatic transfer is a transfer that was completed properly before any interactive review. Conflation errors are classed into three types: omission, commission, and mismatch. An omission error is where a target arc does not receive a reach code in the automated process but receives one in the subsequent review process. A commission error is where an arc receives a reach code in the automated process, but the reach code is removed in the review process. A mismatch error occurs when an arc receives a reach code in the automated process, but a different reach code is assigned in the review process. Automated conflation results for 12 subbasins in Arkansas, Kansas, Kentucky, Virginia, and Vermont are summarized in figure 4.
Waterbody reach conflation. The 12 high-resolution subbasins that were reviewed contain 1,739 polygons that either automatically received or should have received a reach transfer. These are the polygons involved in the conflation process, and they represent a small subset (less than 5 percent) of all the polygons in the 12 high-resolution datasets. Of the 1,739 polygons involved in conflation, 20 omission, 19 commission, and 1 mismatch errors were identified through the interactive review process. This results in about 98-percent successful automatic transfers.
The number of polygons involved in conflation by subbasin ranges from 1 to 519. The percentage of successful automatic transfers by subbasin ranges from 64 to 100 percent.
Transport reach conflation. The 12 target subbasins that were reviewed contain 48,909 arcs that either automatically received or should have received a reach transfer. This is about 60 percent of all arcs in the 12 high-resolution datasets. Of the 48,909 high-resolution arcs involved in conflation, 173 omission, 6,720 commission, and 374 mismatch errors were identified through the interactive review process. This provides a successful automatic reach transfer rate of about 85 percent. As shown in figure 4, about 92 percent of the errors are commission errors, which suggests that the automatic conflation process is much more likely to transfer a reach where it doesn't belong (commission error) than to not transfer a reach where it does belong (omission error), or to transfer the wrong reach (mismatch). This result suggests that automated transfers that produce a branched reach where it does not belong could represent the majority of the errors. Identifying and circumventing this occurrence in the automated processing could greatly improve the conflation approach.
The numbers of arcs involved in transport reach conflation for the 12 target subbasins ranges from 909 to 8,497. The percentage of successful automatic reach transfers by subbasin ranges from 76 to 94 percent.
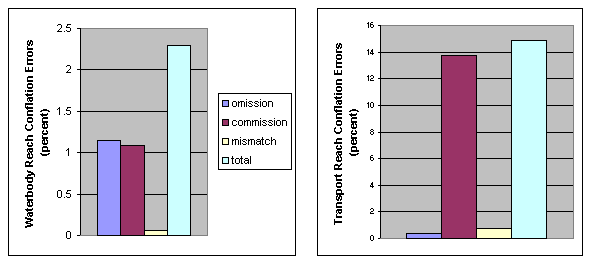
Figure 4. Percentages of waterbody and transport reach conflation errors summarized for 12 subbasins.
Comparison of Transport Reach Conflation Approaches
Two approaches other than the NHDCreate midpoint approach are being applied to perform transport reach conflation in the production of a high-resolution NHD. The first approach, referred to as the buffer approach, is similar to the NHDCreate process in that it applies an automated process along with an interactive review process. However, the automated process generates a buffer around the source reaches and identifies which high-resolution arcs fall substantially within the buffer and thereby receive the reach transfer. A series of rules are applied to complete the automated process, and then an interactive review process is completed. The second approach being used to perform conflation is the manual approach. It consists of interactively viewing each of the source reaches and manually selecting the target arcs that receive the reach transfer.
To get a general idea of the relative success of each of these approaches, we summarized transport reach conflation results for a set of 46, 9, and 6 subbasins for the midpoint, buffer, and manual approaches, respectively. The number of reaches conflated properly and the number of reaches placed in the cross-reference table are summarized for each approach. The disparity in the samples sizes is because of the fact that not many subbasins have been completed using the manual approach.
For the NHDCreate software that uses the midpoint approach, conflation results are tabulated for 46 subbasins that are spatially well distributed over the contiguous United States, residing within 24 States of the 48 contiguous States. There are 63,217 source transport reaches in these 46 subbasins. When the NHDCreate conflation procedures are used, about 92 percent of the reaches are maintained in the high-resolution subbasins and the rest of the reaches are cross referenced (figure 5, MIDPOINT approach). Based on individual subbasins, the percentage of reaches maintained in the high-resolution datasets ranges from 76 to 99.
Conflation results for software that applies the buffer approach are summarized for 9 subbasins located in 8 States of the contiguous 48 States. A total of 12,635 transport reaches exist in these 9 source subbasins. When the buffer approach is used, about 88 percent of the reaches are maintained in the nine target high-resolution datasets, and the remaining are cross referenced (figure 5). Based on individual subbasins, the percentage of reaches maintained in the target datasets ranges from 74 to 95.
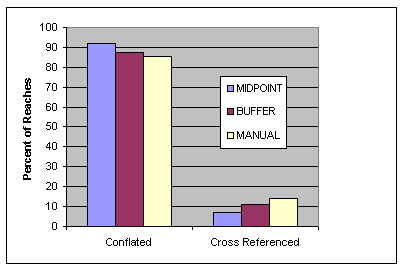
Figure 5. Comparison of different approaches for transport reach conflation.
Lastly, conflation results for six source subbasins located in Georgia, Idaho, Montana, and Washington are summarized for the manual approach. These 6 source datasets contain 15,298 transport reaches. About 86 percent of the reaches are maintained in the target datasets using the manual approach, and the remaining 14 percent are cross referenced (figure 5). Percentages of transport reaches maintained in the individual subbasins range from 82 to 91.
There are about 2.7 million reaches in the 1:100,000-scale NHD. Various organizations have been integrating data with the NHD through the reach address coding system. Functionally, the NHD provides a national framework for integrating environmental data and performing studies related to surface drainage. Proper maintenance of the reach system is essential to the data integration capabilities and overall value of the NHD.
NHDCreate provides a means to generate a higher resolution NHD and maintain as many existing reaches as possible. In comparison with the buffer and manual approaches, the midpoint conflation approach applied with NHDCreate seems to minimize the number of reaches that are cross referenced, which should minimize the effort required to reestablish links with integrated data. However, further research is required to substantiate this observation. Also, variations in the reach transfer rules that are applied during the review process of each of the approaches very likely have an impact on this observation.
In this analysis, the NHDCreate midpoint conflation approach provides successful automatic reach transfers by subbasin ranging from 64 to 100 percent, with averages of 98 percent and 85 percent for waterbody and transport reaches, respectively. If, for each incorrect transfer, there also was a correct transfer that was reviewed, then it can be surmised that, in a worst case scenario, NHDCreate may require about two-thirds of the reaches to be interactively reviewed, but on average a review of only about 15 to 20 percent of the reaches is required. This represents a substantial time savings in comparison with the manual approach, which requires 100-percent review.
About 92 percent of the transport reach conflation errors appear as commission errors suggesting that improper branched transfers may be generating most of the errors in the automated midpoint conflation approach. Further review is required to validate this hypothesis. But if this is true, it may be possible to implement a strategy to eliminate these improper transfers in the automated process and thereby substantially improve the midpoint approach.
Finally, the midpoint conflation approach applied in NHDCreate is an innovative strategy that is tailored to the reach route system of the NHD. It has proved to be at least as effective if not better than other conflation strategies, and it requires far less effort than a manual transfer approach. This approach should continue to be a valuable process for maintaining and improving the NHD for years to come. In addition, this same approach may prove useful in conflating other types of vector data.
Acknowledgments:
Special thanks to all persons in the NHD section of the USGS Mid-Continent Mapping Center, Robbyn Abbitt of the Missouri Resource Assessment Partnership, and Cheryl Rose of the New York State Department of Environmental Conservation for their patient and vigilant software testing during the development of NHDCreate. Thank you also to Keven Roth for her courteous oversight and review of this research, and to Tim Hines, John Walter, and Pat Emmett for assisting with data collection for this paper.
Horn, R.C., L. McKay, and S.A. Hanson. 1994. History of the U.S. EPA's River Reach File: A National Hydrographic Database available for ArcInfo applications, in Proceedings of the Fourteenth Annual Esri User Conference. Environmental Systems Research Institute, Redlands, CA.
Saalfeld, Alan. 1993. Conflation: automated map compilation. Center for Automation Research, CAR-TR-670, (CS-TR-3066). University of Maryland, College Park.
U.S. Environmental Protection Agency. 2000. Georeferencing surface water databases. Accessed June 14, 2002, at URL http://www.epa.gov/owow/monitoring/georef/index.html.
U.S. Geological Survey. 2000. The National Hydrography Dataset: Concepts and Contents. Accessed June 15, 2002, at URL http://nhd.usgs.gov/chapter1/index.html.
U.S. Geological Survey National Mapping Division. 1994. National Mapping Program technical instructions: standards for 1:100,000-scale quadrangle maps. 143 p.
Carl Nelson, Cartographer
USGS Mid-Continent Mapping Center
1400 Independence Road, Rolla MO, 65401
573-308-3838 Fax: 573-308-3652
e-mail: cwnelson@usgs.gov
Martin Hamann, GIS Developer
SAIC Geo-Spatial Data Development Division
2224 Sarno Road, Melbourne, FL 32935
321-751-3272 Fax: 321-757-7870
e-mail: hamannm@saic.com