ArcInfo GIS and S-PLUS statistical package were used to map the current
and potential future distributions of 104 tree species in the eastern U.S
under two climate change scenarios. Regression Tree Analysis (RTA) in S-PLUS was
used to model and predict the distributions. The modelling effort
involved a dynamic exchange of information between the ArcInfo GIS and
S-PLUS statistical environments.
Data:
Forest inventory data for over 180 tree species occuring on
over 100,000 plots and consisting of nearly three millon trees east of
the 100th meridan were aggregated to a county level. Species importance
values (IV) for over 2100 counties were estimated using the basal area
and the number of stems of both the understory and the overstory and could
reach a maximum of 200 for monotypic stands. These tree IVs (response variable)
were combined with county-level data of over 60 predictor variables that
fell into five main categories - climate, soil, elevation, disturbance
and landscape-metrics. Various Unix tools (eg., shell scripts, perl and
awk) as well as ArcInfo's AML and Splus functions were used to construct
the database and automate various processes. Data flow between ArcInfo
and S-PLUS was accomplished either manually, or through the S+GIS Link.
The geographic nature of the database was maintained through the State-County
FIPS variable.
Data collected, manipulated and aggregated to the county-level included:
1. Tree ranges and importance values, as calculated from over 100,000 forest inventory and analysis (FIA) plots assessed by the USDA Forest Service (Hansen et al. 1992);
2. Climatic variables, as obtained from the USEPA (1993);
3. Soil variables from the State Soil Geographic Data Base (STATSGO) by Soil Conservation Service (1991);
4. Elevation, derived from 1:250,000 USGS 3 arc-second data (US Geological Survey, 1987);
5. Land use/land cover, from the GEOECOLOGY data base of Oak Ridge National Laboratory (Olson et al. 1980) and AVHRR-derived forest vegetation classes from the USDA Forest Service (1993);
6. Socioeconomic factors, from ArcData (Environmental Systems Research Institute, 1992); and
7. Landscape pattern, as calculated on the AVHRR forest cover map using Fragstats (McGarigal and Marks 1994).
Modelling Effort:
Environmental factors, as modified by disturbance processes,
generally control the overall range of distribution and importance of tree
species. Within a region, species respond to regional climatic factors,
whereas variations in terrain, soil, and land-use history control local
distributions. Since we are primarily interested in explaining the range-wide
spatial variation at a macro-scale, we recognize that different variables
may drive the importance of the species at different portions of their
range. Thus it is preferable to use an analytical technique that is not
bound by restrictive assumptions of linear statistical models. Regression
tree analysis (RTA) seemed especially suited for our purpose since it is
based on repeated resampling of the data to form prediction rules (Breiman
et al., 1984).
RTA Model:
In RTA, binary recursive partitioning is used to split a dataset
into increasingly homogeneous subsets until another split is infeasible.
The decision rules for splitting the dataset are determined from the data.
Each rule contains only a subset of the predictor variables and some variables
may never be used (Chambers & Hastie, 1993). Each individual split
is based on a single predictor variable and is chosen to minimize the variability
in the response variable in each of the resulting subsets, thus creating
nodes or clusters of data with similar characteristics. The variance of
the data within each node is relatively small, since the characteristics
of the contained data are similar. The output from RTA, called a tree (not
to be confused with the photosynthetic variety), begins with the full data
set and ends with a series of terminal nodes. At each terminal node the
mean of the response variable is taken as the prediction for future observations
(Michaelsen et al., 1994).
Compared with linear statistical models, RTA better captures non-additive and non-linear relationships in the data . RTA was especially appropriate to our dataset because of the many surrogate variables and probable interactions and nested heirarchical relationships. RTA captures interactions by splitting the data into subsets based on the first predictor and then identifying entirely different relationships with other predictors in the two resulting subsets. For example, the relationship between species abundance (response) and aspect might depend on elevation in mountainous terrain, where species importance values vary more by aspect at higher elevations than they do at lower elevations (Michaelsen et al., 1994).
RTA, therefore, is highly suited for distributional mapping wherein different variables operate in different geographic regions. The variables that operate at large scales are used for splitting criteria early in the model, while variables that influence the response variable locally are used in decision rules near the terminal nodes (Moore et al., 1991). We could therefore expect that broad climatic patterns are captured higher up on the tree while more micro effects (like soil, disturbance, etc.,) determine more local distributional variations. It should, however, be recognized that since our dataset is aggregated to a county level scale, RTA will not be able to capture the environmental drivers which operate on species at a very fine scale (e.g., individual slopes or valley bottoms).
Results:
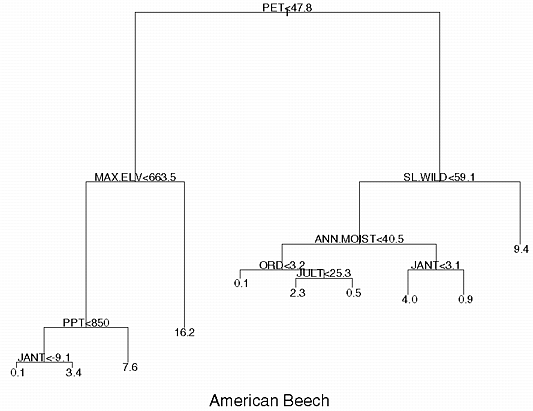
We can associate the splits of the regression tree diagram of
a species to a map wherein the counties that fall along particular branches
of the RTA tree are depicted. Variables most responsible for the predicted
importance values are thus shown geographically. The RTA tree diagram for
American beech (Fagus grandifolia), a common mesophytic species
with wide ecological tolerances, are shown in Fig.1.
Note that the more important the parent split, the further the children
node pairs are spaced from their parents. Thus we can gauge the relative
importance of the split by the length of the line separating the splits.
The primary split occurs with potential evapotranspiration (PET), with
generally higher IVs where conditions are more moist (low PET). The associated
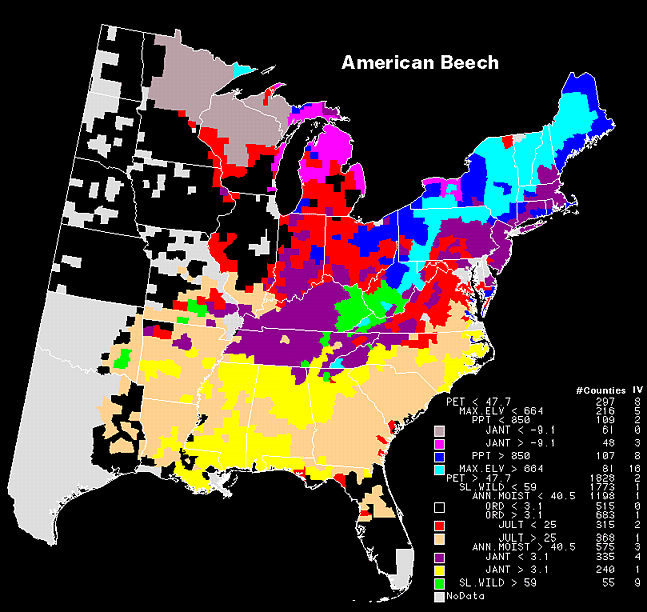
map for the RTA tree structure is in Fig.2. Though
the species is general in requirements and not high in importance anywhere,
it tends to be more prominent in the northern Appalachians, and in the
higher elevations of the southern Appalachians (cool and moist conditions).
Click here to see the legend abbreviations explained.
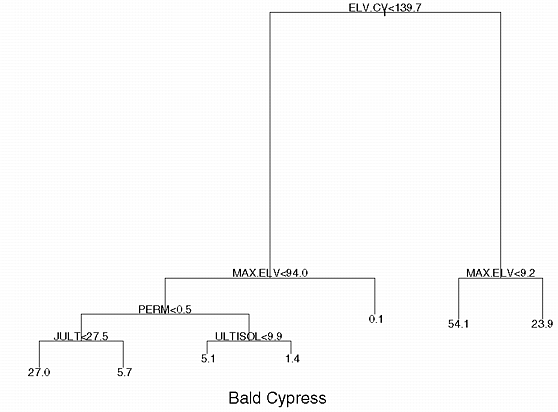
The tree diagram for bald cypress (Taxodium distichum) (Fig.3),
a bottom-land species found mainly in low-lying, swampy, water logged areas,
shows that elevation is indeed driving the distribution. Highest IV values
occur in counties of low mean elevation and consequently high coefficient
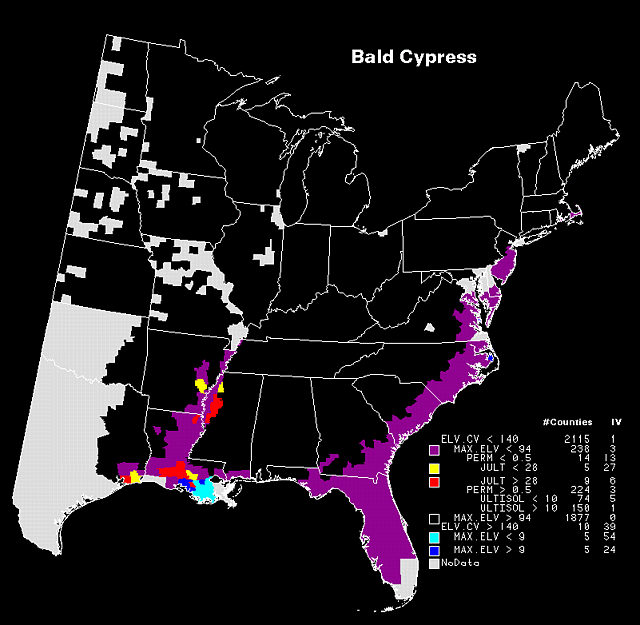
of variation (% standard deviation/mean). The associated map (Fig.4)
shows the regions where the IV of bald cypress is high, corresponding primarily
to the coastal Mississippi delta, with some presence also on the Atlantic
Coastal Plain. Also notice that if maximum elevation is greater than 94
m, (MAX.ELV > 94) the IV is zero.
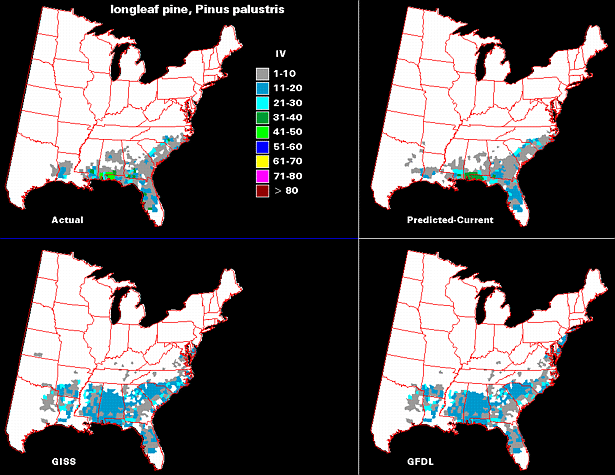
Once the regression trees are generated, they can be used to not only to generate predictive maps of current distributions, but also potential future distributions under scenarios of changed climate. Two global circulation model (GCM) scenarios of climate with 2xCO2 were used for predictions of potential species distributions: the GFDL (Wetherald and Manabe 1988), and GISS (Hansen et al., 1988). We swapped predicted future climate variables, according to the GFDL and GISS models, for the current county estimates of the climatic variables and reran the models to see how the distribution and IVs changed. The maps of actual, predicted-current and the two GCM model predicted future distributions are shown for paper birch (Betula papyrifera) (Fig.5) and longleaf pine (Pinus palustris) (Fig.6). RTA models show that paper birch is essentially extirpated from the US according to the two GCM model predictions while longleaf pine shifts northward in its range with decreased IV in its original strongholds.
Current/Future Efforts:
While RTA explains a large portion of the distribution for some
species, there are many other factors driving the distribution that are
either omitted from the model and/or are in a scale unsuitable for RTA.
These spatial trends could be explained using spatial regression modelling.
We are currently investigating the use of the S-PLUS's SpatialStats module
to compare RTA with a spatial regression model which incorporates possible
large scale trends (through a trend-surface model), with possible small-scale
spatial correlation (through an autoregressive neighbor-weight structure)
in addition to a linear predictor model.
Conclusions:
The nature of tree species plays a very important role in the
predictive mapping ability of the RTA. Some species are generalists (eg.,
American beech, red maple, loblolly pine, etc.) while others are more specific
in their demands (eg., bald cypress, river birch (Betula nigra),
etc.). RTA captures the broad trends quite well, but the scale of our data
makes more micro-scale requirements of a species hard to capture. Since
broad-scale patterns are our goal, RTA does provide adequate predictive
ability at a continental scale. We show that some species are projected
to increase their importance and expand northward while other species are
indicated to decrease in importance and disappear from the US. It
should be noted that we are just mapping the potential envelope of the
species distribution under changed climate and are not considering fragmentation
of the landscape, competition, speed of maturation and reproduction, and
water-use efficiency as such (except for what may be accounted for by surrogate
predictor variables).
Acknowledgments:
Sincere thanks are due all the people that provided data for
this effort, and to the USDA Forest Service, Northern Global Change Program
(R. Birdsey, Program Manager) for their support.
Breiman, L., Friedman, J., Olshen, R. and Stone, C. 1984. Classification and Regression Trees. Wadsworth, Belmont, California.
Chambers, J.M., Hastie, T.J. 1993. Statistical Models in S. Chapman and Hall, London.
Environmental Systems Research Institute. 1992. ArcUSA 1:2M, User's guide and data reference. Environmental Systems Research Institute, Redlands, California.
Hansen, J., Fung, I., Lacis, A., Rind, D., Lebedeff, S., and Ruedy, R. 1988. Global climate changes as forecast by Goddard Insitute for Space Studies three-dimensional model. Journal of Geophysical Research 93:9341-9364.
Hansen, M.H., Frieswyk, T., Glover, J.F. and Kelly J.F. 1992. The eastwide forest inventory data base: users manual. General Technical Report NC-151. USDA Forest Service, North Central Forest Experiment Station. St. Paul, Minnesota.
McGarigal, K. and Marks, B., 1994. Fragstats. Version 2.0. Forest Science Department, Oregon State University, Corvallis, Oregon.
Michaelsen, J., Schimel, D.S., Friedl, M.A., Davis, F.W. and Dubayah, R.C. 1994. Regression Tree Analysis of satellite and terrain data to guide vegetation sampling and surveys. Journal of Vegetation Science 5: 673-686.
Moore, DM., Lees, B.G. and Davey, S.M. 1991. A new method for predicting vegetation distributions using decision tree analysis in a geographic information system. Environmental Management 15:59-71.
Olson, R. J., Emerson, C.J., and Nungesser, M.K. 1980. Geoecology: a county-level environmental data base for the conterminous United States. Oak Ridge National Laboratory Environmental Sciences Division Publication No. 1537, Oak Ridge, Tennessee.
Soil Conservation Service. 1991. State soil geographic data base (STATSGO) data users guide. Miscellaneous Publication 1492, USDA Soil Conservation Service. Washington, D.C. 88 pp.
USDA Forest Service. 1993. Forest type groups of the United States. Map produced by Zhu Z., Evans D.L. and Winterberger K. Southern Forest Experiment Station, Starkville, Mississippi.
USEPA. 1993. EPA-Corvallis model-derived climate database and 2xCO2 predictions for long-term mean monthly temperature, vapor pressure, wind velocity and potential evapotranspiration from the Regional Water Balance Model and precipitation from the PRISM model, for the conterminous United States. Digital raster data on a 10 x 10 km, 470x295 Albers Equal Area grid, in "Image Processing Workbench" format. USEPA Environmental Research Laboratory, Corvallis, Oregon.
US Geological Survey. 1987. Digital elevation models: U.S. Geological Survey Data Users Guide 5. US Geological Survey, Reston, Virginia.
Wetherald, R.T., and Manabe, S. 1988. Cloud feedback processes in a general circulation model. Journal of Atmospheric Science 45:1397-1415.
Authors:
Anantha M. Prasad (prasad@neusfs4153.gov)
Louis R. Iverson (iverson@neusfs4153.gov)
USDA Forest Service
359 Main Rd.
Delaware, OH 43015
WebSite: http://www.nena.org/Delaware
Click on NE-4153 & Global Change
Don't Miss the Java Migration Applet!
Ph: 614-368-0103
Fax: 614-368-0152
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}