
Figure 1: DTED data used in 30-arc second DEM
Lisa Mai Olsen and Norman B. Bliss
GIS Solution: Because there were large discrepancies between data sources and types, it was necessary to be extremely selective about which data were used as input to ANUDEM. Problems invariably arose in areas of overlapping data sources, areas where different data sources came together, areas of little relief, and areas with very little data coverage. Tools using Arc Macro Language (AML) were developed to aid in creating plots, including or excluding data, and editing problem areas. Processing in the Amazon basin posed a unique set of problems. The Amazon river system is quite large and has little elevation change over long distances. To further complicate matters, very few elevation data were available for the basin. Special techniques were developed to interpolate elevation values in the Amazon basin. These interpolated river elevations were then used to constrain the interpolation of the surrounding topography using ANUDEM. Various artifacts in the data may be introduced through processing, including the creation of spurious hills and valleys and a stair-step procession in areas of gradually sloping topography. When it was possible, generation of anomalous features was minimized by selecting or excluding input data and editing the results. In these cases, it was necessary to run small patches of data through ANUDEM and to develop GIS-based tools to help merge several gridded elevation patches into the final output grid.
Software: ArcInfo and GRID 7.0.3 and ANUDEM
A 30-arc-second digital elevation model (DEM) of South America was recently developed forming part of a 1-kilometer global elevation data set entitled "GTOPO30." The result is a raster data product. A graphic representation of the data is based upon shading elevations by color and blending a shaded-relief view. This data set has 10 times more points along each line of latitude and longitude than the best continental data set previously available to the public (ETOPO5), representing a 100-fold increase of resolution on an areal basis. The 30-arc-second spacing results in 120 data points per degree of latitude and longitude. The cell size on the ground is variable, but it is roughly 1 square kilometer near the Equator and decreases toward higher latitudes. The data used to create the South American DEM include Digital Terrain Elevation Data (DTED), which were generalized from a 3-arc-second resolution to a 30-arc-second resolution through systematic sampling; Digital Chart of the World (DCW) contours, point elevations, and drainage network; International Map of the World (IMW) contours and points; Army Map Service contours digitized by Geomatics, Inc.; and point elevations estimated from a river network derived from both the DCW and the IMW.(fig. 1)(fig. 2)(fig. 3)
Figure 1: DTED data used in 30-arc second DEM

Figure 2: DCW data used as input to ANUDEM

Figure 3: Other data used as input to ANUDEM
While the resampled DTED data were used directly in the final data set where available, the remaining data were processed using Australian National University's digital elevation model (ANUDEM) software (Hutchinson, 1989). This software iteratively applies a spline interpolation algorithm to the elevation data, resulting in a gridded surface. Additionally, this algorithm allows for the incorporation of stream network data without elevation values, to maintain hydrologic consistency in the resulting elevation grid. For this reason it was necessary to have a clean, connected stream network available as input. In areas where DTED are adjacent to other sources, a 40-percent sample of the DTED was included in the ANUDEM run. The inclusion of DTED in ANUDEM helped to make the transition zones between interpolated areas and the DTED more continuous. The results of ANUDEM were reviewed in a series of small areas, and several runs of large areas were made to cover the continent.
Each of the five data sources had a different scheme for data organization. For this project, each set of source data was kept in its original structure. The boundaries of the tiles in these schemes, however, did not coincide. Although the Librarian capabilities in ArcInfo were considered, they were not available for the grid data structure. As a result, methods were developed using Arc Macro Language (AML) programs to select geographic areas using an index coverage and then loop through the appropriate sets of coverages or grids. The geographic selection sets were named and stored as an item in the polygon attribute table of the index coverage, enabling several steps to be run without having to respecify the geographic area.
Because there were rather large discrepancies between data sources and types, it was necessary to be extremely selective about which data were included as input to ANUDEM. Problems invariably arose in areas of overlapping data sources, areas where different data sources came together, areas of little relief, and areas with very little data coverage. Where conflicts arose, unreliable data were excluded as input to ANUDEM (fig. 4).

Figure 4: Data excluded from ANUDEM
The first challenge, therefore, was identifying problem areas in the data. Sophisticated plotting programs were developed using AML to automate the processes of data selection, drawing, and printing. First, individual data sets were scrutinized at a variety of scales both on screen and in hardcopy plots to identify potential conflicts. Tile boundaries within a data set were identified as potential areas of conflict where the connectivity of contours and stream networks was not maintained. Serious conflicts between stream network data and contour data also posed problems for ANUDEM. Even within a single data set, it was not uncommon to see streams crossing contours in unusual places, traversing over hills and across valleys. As mentioned earlier, ANUDEM uses stream networks without elevation to help constrain the interpolation process and maintain hydrologic consistency. It was, therefore, necessary to use a clean, connected stream network consistent with contour data as input. Another commonly encountered problem was the miscoding or mislocation of elevation points between conflicting contours. If not rectified,these points would misrepresent the data in the output grid as fictional mounds and sinks.
In addition to conflicts within a given data set, many difficulties were encountered when viewing multiple data sets covering the same or adjacent areas. Data were plotted at varying scales to identify areas of conflict. Due to the relative paucity of data in parts of South America, it was necessary to consider all data as potential input to ANUDEM. For this reason, any reasonable data within a conflicting data set needed to be salvaged as input to ANUDEM. The approach taken is one of data selection and exclusion, not of data editing. An item titled "USE" was added to every attribute table of point and vector data being considered as input to ANUDEM. This item was given an initial value of "T" for true and then could be flagged with either an "F" for false or an "S" for split. Programs and menus were developed for ARCPLOT to help automate the time-consuming tasks of plotting multiple data sets at large scales and selecting individual arcs and points to be flagged for inclusion to or exclusion from ANUDEM. Coding arcs with an "S" for split was particularly useful in minimizing areas of conflict while retaining as much data as possible. The "S" flag was heavily utilized at tile boundaries and in areas where two data sets met with some overlap. In areas of intense overlap, the most consistent data type or the data type covering the larger continuous area was selected at the expense of others. To maintain a continuous data surface as input for ANUDEM, however, required splitting arcs of adjoining or overlapping data sets and then fanning them together in the cleanest possible way. The processes of plotting and flagging records could all be done in ARCPLOT, but the actual splitting of arcs needed to be done in ARCEDIT. Accordingly, similar menus and AML's were developed in ARCEDIT to allow the semiautomated, user-guided selection, plotting, and editing of data.
Processing in the Amazon basin posed an additional challenge to the project and offered a unique set of problems. The Amazon river system is very large and has very little elevation change over long distances. To further complicate matters, very few elevation data were available for the basin. Special techniques were developed to interpolate elevation values in the Amazon basin. These interpolated river elevations were then used to constrain the interpolation of the surrounding topography using ANUDEM. The necessity of a clean, hydrologically sound stream network cannot be overemphasized because the interpolation process must traverse the network to assign elevation values. The main reaches of the Amazon River system are very complex, represented by double-line streams with many islands. It was, therefore, necessary to digitize a simplified stream network from the DCW as a starting point for the interpolation. Through trial and error it was discovered that the benefits of this process would be amplified if the network used for interpolation was extended beyond the nearest contour in all directions. The DCW network was simplified using the selection techniques described in the previous section and then appended to the newly digitized network. An AML program was used to "flip" network arcs so as to maintain hydrologic consistency, ensuring uniform flow direction and that no breaks in the river system were present. Network ends were identified, flagged, and tagged with elevation values derived from contour data. In areas where the network crossed multiple contours, these nodes were also tagged with an elevation. The more elevation constraints given for the interpolation, the more reasonable the results. Once elevations had been specified for nodes where data were available, elevations were interpolated for other nodes using the distance along the arcs (stream reaches). The Arc Network command CALIBRATEROUTES did not function as expected for this purpose, as river arcs are oriented downstream while elevations increase upstream, so the functionality was coded in AML. Once the network was prepared, an EVENT table was formed containing the interpolated elevations for desired network locations. The EVENTPOINT command created a point coverage of elevations along the stream network, and this provided sufficient control in the ANUDEM runs to create a reasonable grid of elevations for the area.
Due to processing constraints, the continent was divided into three parts for final ANUDEM processing. Remaining problem areas were rerun through ANUDEM and reviewed in a series of small areas (patches). Programs were developed in GRID and ARCPLOT to aid in viewing and merging the patches into the final output grid. Even though the data withstood a rigorous selection process, problem areas were still evident in the output grid. In addition to the use of "bad" data as input to ANUDEM, various artifacts in the data may be introduced through processing, such as the creation of spurious hills and valleys and a stair-step procession in areas of gradually sloping topography. Once problem areas or anomalous features were located, the cause needed to be identified. The actual data used as input to ANUDEM were plotted on top of the elevation grid to determine whether the problem was a result of the input data selected or a result of the processing. Corresponding linesets, lookup tables, remap tables, and shadesets were incorporated into sophisticated plotting programs to help detect mismatched data. If a direct relationship was found, the input data were reevaluated and the patch, or a part of the patch, was rerun through ANUDEM. Problems often arose not as a direct result of the data used as input but from edge effects of running one patch at a time. Difficulties were also encountered in areas of gradually sloping topography or areas with few data that were adjacent to areas of steeply sloping topography. One remedy in these areas was to mask the steeply sloping area and rerun the flatter area through ANUDEM. Without the influence of the adjacent topography, anomalous features were minimized. An example of this problem was encountered near the Andes Mountains in Bolivia, where spurious hills and valleys not supported by the input data were apparent in an area of flat terrain. To remedy the problem, operators excluded contour data for the mountains, reran ANUDEM, and then used a part of the resulting grid as input to another ANUDEM run that included all of the area data. The result was more representative of the landscape, maintaining the integrity of flat and steeply sloping terrain. The interpolation methods described earlier for the Amazon basin greatly reduced the stair-stepping effect common to gently sloping areas.
Once correction patches had been created and deemed satisfactory, problems with merging the correction patches into larger grids became evident. The goal was a relatively seamless final product, which was a challenge considering all of the small pieces that had to fit together. A program was developed in GRID which, utilizing several steps, could blend a correction patch back into the larger grid with minimal artifacts at the edge. First, a difference grid was created from a comparison of the original output from ANUDEM and the correction grid. The difference grid was used to identify areas of minimal difference, which could then be used as guidelines for "clipping" the correction patches and merging the grids. Three boundaries were delineated using the difference grid; these included an outer boundary, a secondary or middle boundary, and an inner boundary. The first step was to identify the outer boundary of the correction patch on the output grid. The next step was the delineation of a secondary, or middle, boundary within the correction grid. Within the zone between the outer and secondary boundaries, data from the original output were retained for use in the output grid. Following identification of this outer zone, the next step was to identify an inner boundary that would isolate the area of greatest difference or the correction area. Within the inner boundary, data from the correction patch would be used directly over the output grid. Finally, the zone between the secondary (middle) and inner boundaries would be merged, resulting in a smooth transition from the pure output grid to the pure correction grid. These user-guided methods are extremely flexible and were used wherever possible to minimize the presence of seams on the output grid.
Although the final output grid is an improvement over previous versions, its accuracy is limited by the accuracy of the source materials used to create it. The typical contour interval in the DCW data is 1,000 feet (305 meters). The stated limits of accuracy for the DCW, as defined by the National Imagery and Mapping Agency (formerly Defense Mapping Agency), are 2,000-meters circular error (horizontal) and plus-or-minus 650-meters linear error (vertical) at 90-percent confidence. The accuracy for the result has not been measured or calculated, although it is probably better than the stated accuracy for large areas. Ideally, the accuracy of the interpolation should approach one-half of the contour interval of the source data. However, various artifacts are introduced by the processing. For example, if point data occur in an area with little other control, a mound is created around the elevation point. If these points were coded at peaks, the result may be realistic. However, if the points were in a relatively level area, then the mounds provide a misleading representation of the topography, and the elevation of the surrounding area is underestimated. There is a stair-step effect at contour lines in areas with gradual elevation change. A tradeoff exists between horizontal accuracy in matching the contours and vertical realism in expected topographic profiles. The maintenance of horizontal accuracy at the expense of vertical realism was chosen for this project.
This data set (fig. 5)is expected to be useful for geometric registration of satellite images of the Earth and for studies in the fields of geology, hydrology, ecology, and agronomy. The South American DEM has already been used to aid in land cover classification of advanced very high resolution radiometer (AVHRR) data in South America (Loveland and others, 1996). As a part of the 1-km global data set GTOPO30, (http://gtopo30/) the South American DEM provides a greater level of detail than previous versions and has wide-ranging applicability in Earth systems research and management.
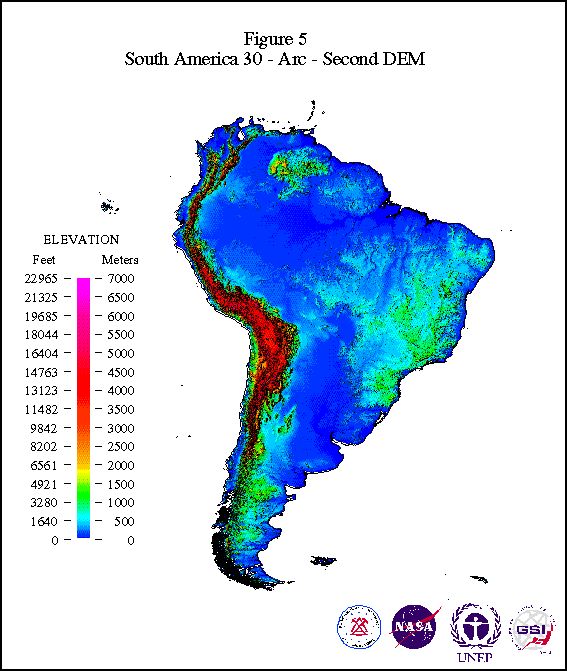
Figure 5: 30-Arc-Second DEM of South America
Hutchinson, M.F., 1989, A new method for gridding elevation and stream line data with automatic removal of pits: J. Hydrol, 106, 211-232 p.
Loveland, T.R., Ohlen, D.O., Brown, J.F., Reed, B.C., Zhu, Z., Yang, L., and Merchant, J.W., in press, Western Hemisphere land cover: Progress toward a global land cover characteristics data base: In Pecora 13 Conference, Proceedings, Sioux Falls, SD, August 20-22, 1996.
Any use of trade, product, or firm names in this publication is for descriptive purposes only and does not imply endorsement by the U.S. Government.
Hughes STX Corporation. Work performed under U.S. Geological Survey contract 1434- CR-97-CN-40274.
Lisa Mai Olsen
Hughes STX Corporation
EROS Data Center
Sioux Falls, SD 57198
Telephone: (605) 594-6052
Fax: (605) 594-6529
olsenl@edcmail.cr.usgs.gov
Norman B. Bliss
Hughes STX Corporation
EROS Data Center
Sioux Falls, SD 57198
Telephone: (605) 594-6034
Fax: (605) 594-6529
bliss@edcmail.cr.usgs.gov