Technology
by: Henning Steen Hansen, National Environmental Research Institute
Abstract
The increasing availability of geographic data and the emergence of true desktop geographic information systems like ArcView, have created demands for new techniques for spatial data analysis. However, a total integration of GIS and spatial data analysis techniques is a prerequisite for widespread use by non-GIS specialists. In this paper we demonstrate how to use Avenue to develop a data analysis extension to ArcView.
Introduction
A map is an excellent medium, and a first impression of spatial variation can be picked up from a map. However, in order to identify significant patterns in data we have to go beyond the visual interpretation of data illustrated in form of maps. Therefore we expect that future GI systems will contain increased analytical capabilities that will take them beyond being efficient visualization tools.
Most statistical methods are non-spatial, and standard statistical packages are not designed to handle spatial data. Furthermore, the analysis tools which are usually integrated in commercial GIS products are often limited to simple spatial operations such as buffering and overlaying. This means that the users often have to write their own routines in order to use different spatial statistics. A lot of statistical techniques that seek to identify and quantify spatial relationships have been developed. Spatial autocorrelation tools include for example Moran's I (Moran, 1948) and Geary's c (Geary, 1954). These statistics indicate the degree of spatial association as reflected in the data set as a whole. Getis and Ord (1992) have suggested statistics to measure the degree of local spatial association for each observation in a data set. Several attempts have already been made to link existing analytical software to various GIS products, but a problem with all of these attempts is that the user is forced to switch back and forth between the GIS and the analytical software.
Our experiences show that scientists will not use techniques until they are readily available. Therefore we have developed some spatial statistical tools within the framwork of ArcView 3 (Esri, 1996a). Avenue (Esri, 1996b) is the customization and development environment for ArcView. Everything you work with in ArcView are objects which can be accessed through Avenue requests. Avenue contains a set of spatial selection requests, which seems very useful for developing spatial data analysis tools. Furthermore, the use of dynamic linked windows in ArcView provides a foundation for creating an interactive analysis environment. Finally, the extensible architecture enables developers to provide a flexible GIS computing environment. Extensions make it easy for developers and experienced users to enhance the functionality of ArcView.
The current paper will describe the above mentioned data analysis tools, and how to use Avenue as basis for developing these tools. Finally, the paper will demonstrate how population data can be analysed using the different spatial statistical methods.
Spatial analysis and GIS
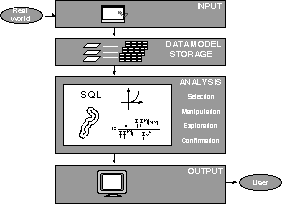
Traditionally, geographic information systems are considered to perform four basic functions: input, storage, analysis and output (FIG. 2). As mentioned above, the focus of the current paper is on the analysis module, which usually contain four important functions:
- Selection is a rather simple operation, but it is important because all subsequent work is based on the results of the selection process.
- Manipulation has to do with aggregation, buffering, overlaying and interpolation. Although, the manipulation functions are the tools usually called spatial analysis in most GIS software, they are not really spatial analysis tools.
- Exploration is the first step in discovering any kind of pattern or cluster in a data set. Explorative spatial data analysis (ESDA) use the data in an inductive way to get new insight about spatial patterns and relations - "we let the data speak for themselves" (Gould, 1981). Spatial statistics as Moran's I and the G statistics are important tools in explorative spatial data analysis.
- Confirmation can be seen as tools for estimation of process models, simulation and
- forecasting, but in fact nothing has been done in the field of including confirmatory functionality in GIS.
Figure 2. Functions of a GIS
The linkage between spatial statistical analysis and geographic information systems is an important step in providing additional spatial analytical capabilities to a GIS, and this linkage can basically be established in three different ways :
- GIS and spatial statistical analysis can be maintained as two separate packages and simply exchange data between the two systems.
- GIS functions can be embedded within spatial analysis or modelling systems.
- Spatial analysis can be fully integrated within the GIS software.
The first strategy to export spatial data from the GIS to standard statistical systems is not an adequate solution, because the nature of spatial data requires specific spatial analytical functions. On the other hand, Anselin et al. (1993) have combined SpaceStat, a program for the analysis of spatial data, with the ArcInfo GIS using this approach.
The second strategy, embedding GIS functions into a spatial statistical package seems to be an overwhelming exercise and not really realistic.
The third strategy, a full integration of spatial analysis tools into a GIS seems most promising (Hansen, 1996). Using this strategy you can utilize the interactivity between maps, charts and spatial statistics to get a good feeling of patterns and relationsships within the data.
Classical measures of spatial autocorrelation
Spatial autocorrelation tools test whether the observed value of a variable at one locality is independant of values of the variable at neighbouring localities. A positive spatial autocorrelation refers to a map pattern where geographic features of similar value tend to cluster on a map, whereas a negative spatial autocorrelation indicates a map pattern in which geographic units of similar values scatter throughout the map. When no statistically significant spatial autocorrelation exists, the pattern of spatial distribution is considered random (FIG. 3).

Figure 3. Concepts of spatial autocorrelation
To obtain the spatial autocorrelation coefficient of a variable we have to correlate the values of that variable for pairs of localities. However, not all pairs of localities will be correlated, only those that are considered neighbours. Moran's I statistic can be calculated according to the equation
![]() ,
,
where x is the observed value at location i, and n is the number of locations. The weighting function Wij is used to assign weigths to every pair of locations in the study area, and the spatial autocorrelation depends on these weights as well as the data for the locations. The simplest weighting function for areal data is a set of binary weights that have a value of 1 for areas that share a common boundary and 0 otherwise. These adjacency weights does neglect important spatial elements such as distance between the centers of the polygons.
The mean of Moran's I under either normality or randomization is given by
,
which approaches zero for large samples. Under the assumption of normality, the variance of Moran's I is defined as
.
Instead of interpreting the actual values of Morans I, a standardized z-value can be obtained by subtracting the expected value for the statistic, and dividing the result by the corresponding standard deviation. The resulting z-value can then be compared to a table of standard normal variates to assess significance. It can be shown that Moran's I are asymptotically normally distributed as n increases. In the current paper the Moran's I are assumed to be approximately normally distributed. If there are a large number of polygons under consideration then normal approximations are usually accurate and this is used in testing the significance of departures from the null hypothesis.
Implementation
Notice, that only the weighting function can really be considered spatial. However, for large data sets it seems to be a rather time consuming exercise to calculate the full weighting matrix. A vector-topological GIS is a very useful basis for the calculation of different spatial statistics ( Hansen, 1994), but in order to support the non-topological shape format, you have to use another approach. ArcView provides the ability to select the features of one or more themes using the features of another theme. Selecting features in this way is one of the spatial analysis methods you can use to resolve problems that involve issues of proximity, adjacency, and containment. The corresponding Avenue request SelectByTheme therefore seems useful in the calculation of Moran's I. Figure 4 illustrates how to find adjacent polygons using the SelectByTheme request.
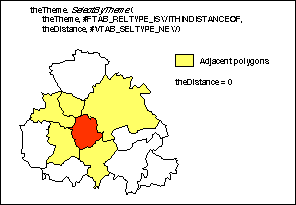
Figure 4. Selecting adjacent polygons.
For each polygon, all neighbouring polygons are found by the SelectByTheme request, which selects the features of a theme if they have the relationship #FTAB_RELTYPE_-ISWITHINDISTANCEOF with distance zero to the selected features of another theme.

Figure 5. Computational principles - Moran's I.
Local indicators of spatial association
The classic methods - Moran's I and Geary's c - summarize a complete spatial distribution into a single number. Although this can be useful in the analysis of small data sets, it may not be meaningful in the analysis of spatial association in thousands of spatial units. Due to the degree of non-stationarity in large data sets several regimes of spatial association might be present.
Getis and Ord (1992) introduced a technique which allows for a finer classification of the data. The Gi and Gi* statistics of Getis and Ord is a measure of spatial association for each individual spatial unit. The Gi stastic is a measure of clustering of like values around a location, irrespective of the value at that location. Unlike this, the Gi* statistic includes the value at the location within the measure of clustering.
For each unit, these statistics indicate the degree to which that location is surrounded by high or low values for the variable under consideration. In the current paper I will only use Gi, which seems more in accordance with our usual interpretation of spatial association. This statistic may be computed for many different distance bands using the following formular
,
where Wij(d) is a binary symmetric spatial weight matrix with Wijwhen i and j are within a distance d from each other and zero otherwise. Getis and Ord derive the moments for the Gi* under the assumption of normality. When d is small, normality is lost, and when d is large enough to encompass the whole area, normality is also lost. Note, that these conditions must be satisfied separately for each locality in order to use the normal approximation. The expected value and variance of Gi* for sample size n under the assumption of normality can be determined by
and
,
where
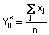
.
The significance of Gi* is assessed by means of a standardized z-value. The interpretation of the Gi* statistics differs from that of the other measures of spatial association (e.g. Moran's I) in that positive Zi means clustering of high values and negative Zi means clustering of low values.
Implementation
Again, only the weighting function can be considered spatial, but instead of selecting adjacent polygons we must find polygons with a certain distance. In order to do this we use the SelectByShapes request which selects the features of a theme that fall beneath a list of shapes (FIG. 6). For each polygon, all polygons within the search distance are found by the SelectByShapes request. The shape list contains a circle with center at the centroid of the polygon and radius equal to the user specified search distance. Next, all polygons whose centroids are within the search circle are selected. Finally, the Gi* and a standardized z-value is calculated for each polygon. The spatial distribution of the standardized z-values are visualized as a choropleth map where negative z-values are displayed in blue colours and positive z-values in yellow-red colours.
Examples
In order to demonstrate the type of output generated by the data analysis extension an example is shown below. The current example is concerned with the regional distribution of elderly people in Zealand, Denmark. The island of Zealand contains 548 parishes. Figure 8 shows the distribution of elderly people (i.e. age above 64), and this map indicates higher values in the Copenhagen metropolitan area and lower values in parishes surrounding this area.
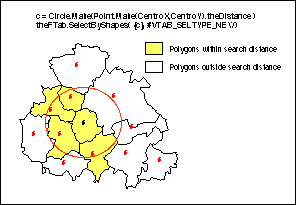
Figure 6. Selecting polygons within a search distance.
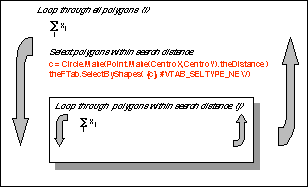
Figure 7. Computational principles - the G* statistics.
First, the spatial autocorrelation was determined using Moran's I. The calculated value for Moran's I is 0.4399 and the standard normal deviate is 16.88, which is much higher than 2.35 - the one-sided 99 % significance point of a normal distribution. This indicates that a high percentage in one parish is associated with high percentages in neighboring parishes and a low percentage in one parish is associated with low percentages in neighboring parishes.
Next, the Gi* statistic was applied. This statistic is particular useful in the detection of potential non-stationarities, which may occur when the spatial clustering of like values is concentrated in one sub-region of the data set. Using a search distance of 15 km the standard normal deviate of the Gi* stastic was calculated for each parish (FIG. 9). The Gi* statistic identified 293 of the 548 parishes of Zealand as significantly positively or negatively associated with their neighbouring parishes. The red and yellow areas corresponding to positive spatial association indicate spatial clusters of parishes with high percentage elderly people. The blue and cyan colours correspond to areas with negative spatial association, indicating clusters of parishes with low percentage elderly people.
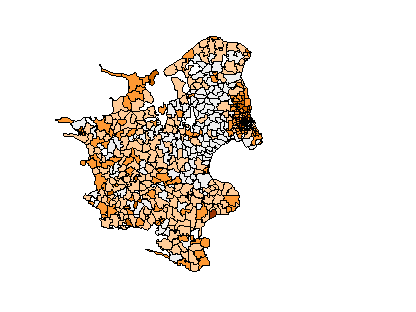
Figure 8. Percentage elderly people in Zealand parishes.
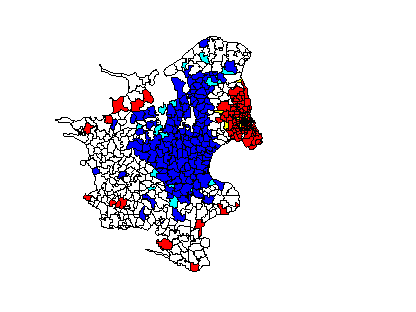
Figure 9. Spatial association of elder people in Zealand, Denmark.
Concluding remarks
During the last decades huge amounts of spatial data have been collected throughout Europe, not at least the Scandinavian countries. Therefore, the need for using spatial data analysis tools are obvious. However, spatial statistical tools are not available in todays commercial GIS software, but recently there seems to be a growing awareness of spatial data analysis. The current paper demonstrates that it is possible to develop complex spatial data analysis tools within a desktop GIS environment. Avenue is a powerful development environment for developing spatial analysis tools du to the spatial selection requests - particularly the SelectByTheme and the SelectByShapes requests. At NERI we have developed a spatial data analysis package containing Moran's I, Geary's c, the Moran scatterpolt and the G / G*-statistics. The future work includes the development of additional tools and a more intuitive user interface using the new Dialog Designer extension.
References
Anselin, L., Dodson, R.F. & Hudak, S. (1993). Linking GIS and Spatial Data Analysis in Practice. Geographical Systems, vol. 1, pp. 3-23.
Esri (1996 a). Introducing ArcView GIS version 3.0. Environmental Research Institute Inc., Redlands, California.
Esri (1996 b). Using Avenue. Environmental Research Institute Inc., Redlands, California.
Geary, R.C. (1954). The contiguity ratio and statistical mapping. The Incorporated tatistician, vol. 5, pp. 115 - 145.
Getis, A. and Ord, J.K. (1992). The analysis of spatial association by use of distance statistics. Geographical Analysis, vol. 24, pp. 189 - 206.
Gould, P. (1981). Letting the data speak for themselves. Ann. Assoc. Am. Geogr., vol. 71, pp. 166 - 176
Hansen, H.S. (1994 ). Spatial autocorrelation in vector-topological geographical Information Systems. Proceedings of the Fifth European Conference and Exhibition on Geographical Information Systems, Paris, pp. 1252 - 1261.
Hansen, H.S. (1996). Interactive analysis of spatial data using a desktop GIS. In Kraak, M.J. & Molenaar, M: (ed.) Advances in GIS Research. Proceedings of the 7th International Symposium on Spatial Data Handling. Delft. The Netherlands, 1996. Pp. 13B25 - 13B35.
Moran, P.A.P. (1948). The interpretation of statistical maps. Journal of the Royal Statistical Society, Series B, vol. 37, pp. 243- 251.

Author information
Henning Sten Hansen
National Environmental Research Institute
Frederiksborgvej 399
DK-4000 Roskilde
Phone: + 45 46 30 18 07
Fax: +45 46 30 12 12
E-mail: HSH @DMU.DK