Two issues facing ArcIMS developers are feature generalization and symbolization. The need for feature generalization is noted in the literature, but few guidelines are presented. What is the relationship between layer size and drawing speed? Are there size thresholds below which generalization is not beneficial? What does generalization do to feature quality? A related question involves symbology. Is it faster to draw multiple layers or use valuemap renderers on one larger layer? Does the answer vary with layer size and map scale? This paper presents the results of our efforts to develop generalization and symbolization guidelines using ArcIMS performance tests.
The Bureau of Information Systems in which we work supports almost 400 GIS users. While many of these users are very skilled and demand much functionality from our GIS software, most of our users need only "browse" access to our spatial data: they want to view the data and spatial relationships, they are not creating or editing data. As our spatial data library grows, and as the linkages between our Oracle data and spatial data improve, there is greater pressure for a "GIS view" of the data. Due to the cost of providing GIS tools such as ArcView and as a result of the significant training required to become proficient using these tools, the Bureau has been looking for an easy-to-use and cheap-to-deploy mechanism to allow browsing access to our GIS data.
At the same time, Florida government is involved in a concerted effort to make public information easily accessible to our citizens. The MyFlorida.com web portal is a manifestation of this effort. Since much, if not most, of what government does has a spatial dimension, it is only natural that GIS-type tools are needed to provide citizens spatially-enabled information. To fulfill this need, the Bureau is seeking a thin-client mechanism with which we can serve spatial information to our citizens.
We believe that ArcIMS can provide the mechanism to serve these two goals. As we began to explore ArcIMS and plan for large-scale deployment of ArcIMS, we learned that the literature and Esri user forum stressed the need to reduce the size of the GIS data served via ArcIMS and the Internet (Carnes, 2001). However, little concrete guidance, as how best to accomplish size reduction and what results might be achieved, was supplied.
To begin to tackle this issue, we decided to investigate three ArcIMS questions related to GIS dataset size and symbology. (1) What is the impact of feature generalization on ArcIMS speed? (2) What are the relative speeds of different approaches to feature rendering? Is the fastest method different for different viewing scales? (3) What is the impact of the data structure such as the number and size of attributes and the presence of spatial and attribute indices? This paper presents the discoveries we made in trying to answer these three sets of questions.
While there appears to be an almost limitless number of options in deploying ArcIMS leading to limitless research opportunities, we focused our efforts on factors affecting image creation in a tightly controlled and limited environment. Because of the many deployment options available, readers should carefully examine the configuration information presented below before extending our results to their environments. Further, we should note that we regard the results presented in the sections that follow as indications of relative performance, not absolute performance.
We ran the ArcIMS performance tests on a Dell Precision 410 Workstation sporting dual 450 MHz Pentium II processors, 1GB of RAM and 30GB of local disk space. The workstation was running MS Windows NT 4.0 SP4. The browser used was MS Internet Explorer (IE) 5.5.
The web-related software running was ArcIMS version 3.0, Apache Web Server v1.3.12, ApacheJServ v1.1, and JRE v1.2.2-004. We employed the default Servlet connector and used the stock HTML viewer (that we customized for testing purposes). We had two image virtual servers running on the workstation, both of which we used for the image services deployed in testing.
The workstation operated as the web server, the map server, the data server and the client viewer. The reason for the multiplicity of roles for the one workstation was to isolate the testing environment from network and resource contention, over which we had little control. We believed that this approach would yield the truest relative performance results.
Although we are running SDE 3.0.2 in production and ArcSDE 8.0.2 in testing and development mode, we opted to employ shapefiles in testing for several reasons. Firstly, we had no control over network traffic. Using ArcSDE as the data server would subject our results to the vagaries of network traffic that we could neither predict nor easily record. Secondly, since the ArcSDE server is being used for development purposes, using ArcSDE data would also subject our testing to unpredictable data access conflicts. Thirdly, although we have ArcSDE usage, we could not readily simulate our SDE 3.0.2 production environment. The literature states that ArcSDE data service performance is superior to shapefile performance in a multi-user environment, but we could not simulate or control that environment so it did not seem prudent to use that environment for testing. As noted earlier in this section, the results presented later should be used only as relative performance measures, not as absolute measures.
Although we serve a wide variety of data to our users and envision a similarly wide dissemination of data to the Internet public, we focused our tests on the line feature type. We made this testing decision for two reasons. Firstly, line features comprise much of our native data. Secondly, when considering "background" data displayed for user orientation purposes, we believe roads, hydrography and governmental boundary lines are most important; all of which are line-type features.
To measure the performance of the various tests, we used the information recorded by the image virtual server in the image server log file. The log file was captured and saved for each test, and then the salient timings entered into our performance comparison tables. Using the log file that included the request also helped insure we were capturing the correct log entries. For testing checks and testing procedure verification we also used JavaScript "alert" messages to display the AXL request being sent to the spatial server (similar to using the ArcIMS debugging feature that displays the AXL requests and responses in browser alert boxes). As stressed earlier, the timings presented here should be viewed closely with our configuration and regarded as relative metrics, not absolute measures that could be matched in any other environment.
Feature generalization has been a concern for cartographers since maps were first drawn. The challenge for cartographers is to present information that is understandable given the output format that drives the map scale. The basic elements of generalization include simplification, symbolization, classification and induction (Robinson and Sale 1969). Esri defines a set of generalization operators used by cartographers to render usable maps at particular scales that includes selection, elimination, simplification, aggregation, exaggeration, classification and displacement (Esri, 1996). These operators can be applied to yield maps for specific purposes at fixed production scales.
The challenge in the Internet mapping arena is significantly increased since the production scale is not fixed, but rather highly variable: we must produce maps based on undefined user-demand across a wide range of scales. To further compound the difficulty, in many instances we are blessed with an ever increasing and rapidly changing spatial database. In our environment we rebuild over 20 data layers on a nightly basis to reflect changes in our regulatory and permitting databases. Thus, the circumstances that allowed traditional cartographers to make the needed generalization decisions (i.e. a fixed production scale, largely static data and well-defined map purpose) are usually unavailable to their Internet mapping counterparts.
Our first question was simple. Are there thresholds below which feature generalization will make no difference to image creation speed? It seemed reasonable that for smaller feature sets (few lines with a small number of vertices) generalization might be unnecessary. To test for thresholds, we created a series of shapefiles with 500, 1000, 2000, 5000 and 10,000 lines composed of 100, 500, 1000 and 2000 vertices (yielding twenty shapefiles for testing). Each shapefile had only one attribute: an Id number. The lines of the shapefiles were evenly distributed over the extent of our State�s Albers projection. The vertices were evenly distributed over the lines.
We then created an AXL file that used an image service defining all of the twenty test shapefiles as layers, but with none of the shapefiles visible initially. Our procedure entailed making use of the stock functionality found in the default HTML viewer. We would check the checkbox to make the layer visible and then use the "Refresh Map" button to generate a view for the browser client. The ArcIMS operations and timings were recorded by default in the service log file (located at �\Esri\ArcIms3.0\Server\Log). The portion of the log file showing the test results was copied for results tracking and analysis. The image creation times (the Total Request Time noted in the log file) are shown below in Table 1. Sample text captured from a service log file can been seen at Appendix A.
Table 1. Threshold test results showing time to create an image (in seconds).|
THRESHOLD TESTING TIME TO CREATE IMAGE (Seconds) |
||||
|
Number of Vertices Per Line |
||||
|
Number of Lines |
100 |
500 |
1000 |
2000 |
|
500 |
0.562 |
1.344 |
2.406 |
4.234 |
|
1000 |
0.891 |
2.5 |
4.578 |
8.406 |
|
2000 |
1.578 |
4.859 |
8.797 |
16.328 |
|
5000 |
3.672 |
11.656 |
21.39 |
40.953 |
|
10000 |
7.89 |
23.062 |
47.656 |
91.375 |
As can be seen from Table 1, there appear to be no image creation thresholds evident. There is a smooth progression of time required for image creation as you add vertices and lines across the entire testing range, which is relatively large. Generally speaking, as you double the number of lines while holding the number of vertices per line constant, the image creation time doubles. As you double the number of vertices per line while holding the number of lines constant, the image creation time does not quite double, but the relationship of time to vertices appears to be linear over the test range. Further, the reader will note that there are no abrupt changes in creation time anywhere across the results matrix, indicating relatively smooth linear relationships as you increase the number of lines drawn and the number of vertices per line. Thus we are led to conclude that there indeed do not appear to be any image creation thresholds. This means that any work to generalize spatial data resulting in fewer lines and vertices should yield ArcIMS performance benefits. This result was contrary to our expectations, but very good to know.
To give readers a sense of scale, the sizes of the twenty shapefiles created for the threshold testing are shown below in Table 2. As can be seen from Table 2, the testing shapefile sizes range from 809KB up to 313MB, a fairly wide testing range. By way of comparison, the .shp file for all roads in Dade County (Florida�s largest county) is less than 9MB in size. A .shp file of that size falls in the middle of our testing range.
Table 2. Threshold testing shapefile size (in MB, *.shp files only).|
THRESHOLD TESTING SHAPEFILE SIZE (MB, *.shp Files) |
||||
|
Number of Vertices Per Line |
||||
|
Number of Lines |
100 |
500 |
1000 |
2000 |
|
500 |
0.809 |
3.934 |
7.84 |
15.653 |
|
1000 |
1.618 |
7.868 |
15.68 |
31.305 |
|
2000 |
3.235 |
15.753 |
31.36 |
62.61 |
|
5000 |
8.087 |
39.337 |
78.399 |
156.524 |
|
10000 |
16.172 |
78.672 |
156.797 |
313.047 |
Readers should remember that the results shown here should be regarded as relative performance measures based on our specific testing environment. While specific results in other environments may differ significantly, we would expect the relative performance in other environments to be similar to our test results.
Given that our test environment used shapefiles with virtually no attributes, and that therefore our test shapefiles were largely lists of points, we expected that the number of vertices in lines would have a greater impact on image creation speed than would the number of lines drawn. While this line of inquiry may seem a bit esoteric, it has some ramifications on the extent to which generalization should be pursued.
There is a very easy to use Esri-supplied generalization script and extension for ArcView. This extension removes unneeded vertices within a user-specified tolerance. It does not, however, join lines that share common nodes (the action of an UNSPLIT in ArcEdit). If points cost more to draw than lines, then one should run the ArcView generalize script and not worry about joining the lines. If lines cost more than vertices, then one should perform an UNSPLIT in ArcEdit and not degrade the data using a generalization routine. If both lines and nodes cost time, then one should perform both actions, which imposes the highest development cost.
To test this hypothesis, we created seven pairs of shapefiles. Each pair had the same number of vertices, but a different number of lines containing those vertices. We used the same testing methodology described in the preceding section: turning on layers, clicking the "Refresh Map" button and capturing the service log file information. The results of the tests are shown below in Table 3.
Table 3. Points versus lines test results showing time to create an image (in seconds).|
POINTS VERSUS LINES TESTING TIME TO CREATE IMAGE |
|||||||
|
(Seconds) |
|||||||
|
Number of Vertices |
|||||||
|
# Lines |
10K |
50K |
100K |
250K |
500K |
1M |
1.5M |
|
100 |
0.27 |
||||||
|
1,000 |
0.56 |
||||||
|
255 |
0.61 |
||||||
|
5,000 |
1.98 |
||||||
|
317 |
0.84 |
||||||
|
10,000 |
3.70 |
||||||
|
500 |
1.61 |
||||||
|
25,000 |
8.78 |
||||||
|
707 |
2.98 |
||||||
|
50,000 |
17.27 |
||||||
|
1,000 |
5.11 |
||||||
|
100,000 |
34.13 |
||||||
|
1,224 |
7.63 |
||||||
|
150,000 |
50.77 |
||||||
Had our hypothesis been correct, each pair of timings would be about the same. As can be clearly seen, they are not. Thus we can conclude that both the number of vertices and the number of lines have a significant impact on image creation time. The ramifications of this test are that ArcIMS performance benefits will be gained by both generalizing the data and by joining all the lines that share common nodes (applying the ArcEdit UNSPLIT command).
Once we established that generalization was important across the spectrum of shapefile sizes, we focused our attention on the impact of generalization. For the purposes of this paper, we explored two simply applied techniques for generalizing our data: the ArcView generalization extension and script and the ArcEdit UNSPLIT command.
We should mention, however, that Esri has been developing a wider array of ArcInfo tools to aid cartographers with the task of generalization and map-making over a wide range of scales. These new tools include the BENDSIMPLIFY, ORTHOGONAL, FINDCONFLICTS, CENTERLINE, and AREAAGGREGATE operators, and include enhancements to the GENERALIZE operator (Esri 2000).
One of our concerns about automated feature generalization was the impact of generalization on feature quality. In our case, that meant the shape, position and length of the lines being generalized. The ArcView generalize extension accepted a search tolerance from the user. The search tolerance is used as the filter to eliminate vertices. The script reports, but does not save, the number of vertices eliminated. We believed that additional measures of feature changes due to generalization would be prudent.
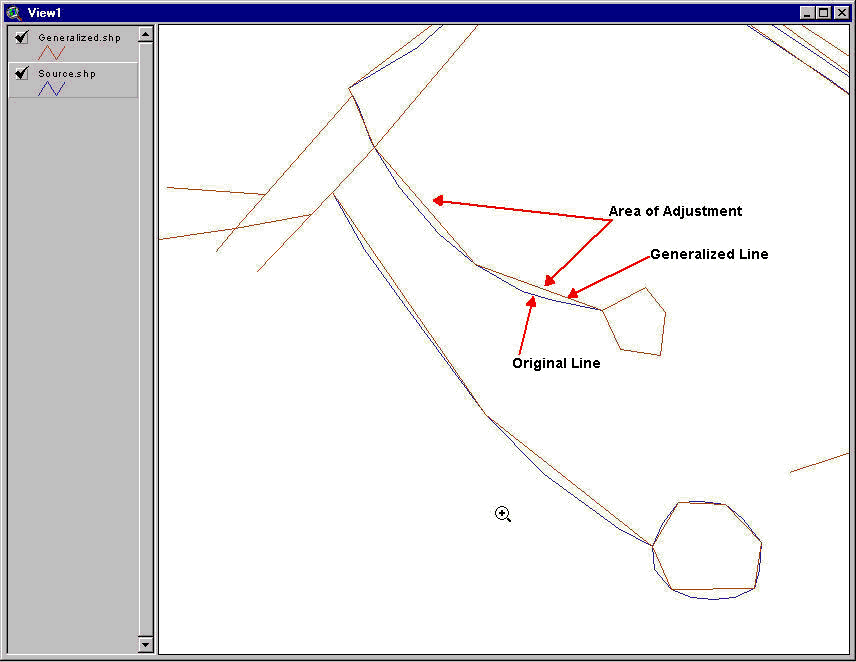
We made three changes to the generalization script: we logged the number of vertices eliminated, we calculated and logged the change in total line length, and we calculated and logged the sum of the "areas of adjustment." We also saved the input and output file names and execution time to the log file. Upon script completion, the log file is displayed to the user. The "area of adjustment" is a term we used to describe the small polygons that represent the difference between the original line and the adjusted line after vertices have been removed. These small polygons are formed by adding the original line segment to the generalized line segment, keeping the end points of the line segment constant. These areas make small polygons (usually triangles) where vertices are eliminated. We added code to the generalize program to calculate and sum the areas of theses small polygons. The ArcView screen dump shown in Appendix B illustrates the concept of the area of adjustment.
To get a feel for the impact of the application of the generalization extension and evaluate the usefulness of the impact measures, we used the statewide limited access highway layer (TIGER CFCC code A1x) extracted from the TIGER/Line files for 2000. We used the GISTools TRG2SHP utility to translate TIGER. We appended the 67 county shapefiles into one statewide shapefile. And, we projected the statewide shapefile into Albers. We used the projection to have a better unit for generalization and evaluation purposes. The resulting test shapefile had 6403 arcs with a total length of 3,110,852.592 meters.
We generalized the limited access highways shapefile across a broad spectrum of tolerances (ranging from 2 to 250 meters) and recorded the results. We then imported the shapefile into ArcInfo 8.0.2 using the SHAPEARC command, having set the PRECISION to DOUBLE DOUBLE. We then used the ArcEdit UNSPLIT NONE command to join lines sharing common endpoints. We then transformed the coverage back into a shapefile using the ARCSHAPE command. The resulting test shapefile had 265 arcs with the same length. We again ran the generalization script using tolerances ranging from 2 to 100 meters. The results of these tests can be seen below in table 4. The shapefile sizes (.shp file only) resulting from the tests can be seen in Table 5.
The table shows two important facts. Firstly, taking the time to bring the shapefile into ArcInfo and apply the ArcEdit UNSPLIT command had a significant impact. It doubled the number of vertices removed and reduced the number of arcs by more than an order of magnitude (from 6403 arcs to 265 arcs). Secondly, the point of diminishing returns is reached by a 10 to 20 meter tolerance. Additionally, at the 10 to 20 meter tolerances the length reduction is modest. It is also apparent that beyond the 10 to 20 meter range the length reduction and area adjustment values rise much more rapidly than the number of vertices removed.
Table 4. Generalization test results.|
GENERALIZATION TESTING RESULTS Florida Limited Access Highways (From TIGER 2000) |
||||||
|
Generalized Only |
Generalized & Unsplit |
|||||
|
Tolerance |
Vertices Removed |
Length Reduced (m) |
Area Adjusted (sq m) |
Vertices Removed |
Length Reduced (m) |
Area Adjusted (sq m) |
|
2 |
1644 |
29.70 |
209378 |
4445 |
29.55 |
418870 |
|
5 |
2920 |
350.07 |
961002 |
6326 |
342.33 |
2.07E+06 |
|
10 |
4374 |
1221.32 |
2.93E+06 |
8606 |
1384.23 |
6.08E+06 |
|
20 |
5084 |
2107.34 |
6.19E+06 |
9913 |
2667.92 |
1.40E+07 |
|
30 |
5352 |
2723.95 |
8.95E+06 |
10386 |
3448.70 |
2.09E+07 |
|
40 |
5472 |
3185.85 |
1.12E+07 |
10664 |
4182.43 |
2.82E+07 |
|
50 |
5556 |
3657.58 |
1.33E+07 |
10813 |
2667.92 |
3.36E+07 |
|
75 |
5689 |
4852.52 |
1.81E+07 |
|||
|
100 |
5753 |
5667.65 |
2.28E+07 |
|||
|
250 |
5900 |
9457.18 |
4.71E+07 |
|||
|
Vertices Before Generalization = |
18746 |
|||||
|
Length Before Generalization = |
3110852.592 |
|||||
Table 5. Shapefile sizes (.shp file only) resulting from the generalization tests.
|
SHAPEFILE SIZE (.shp only, KB) |
||
|
Tolerance |
Generalized Only |
Generalized & Unsplit |
|
Source |
644 |
212 |
|
2 |
618 |
143 |
|
5 |
598 |
113 |
|
10 |
575 |
78 |
|
20 |
564 |
57 |
|
30 |
560 |
50 |
|
40 |
558 |
45 |
|
50 |
557 |
43 |
Table 6 below shows the image creation times for selected test shapefiles. As can be seen from the table, large decreases in the number of lines, the number of vertices and the size of the shapefiles, resulted in significant (but not proportional) decreases in image creation times. The range from the slowest to the fastest was about a second and a half: from 1.9 seconds down to .3 seconds. You may also notice that the effects of system "noise" can be seen where the smaller shapefiles took slightly more time for image creation.
Table 6. Image creation times for selected generalization test shapefiles.|
IMAGE CREATION TIME Florida Limited Access Highways (Seconds) |
|||||
|
Tolerance |
Unedited |
Generalized Only # 1 |
Generalized Only # 2 |
Generalized & Unsplit # 1 |
Generalized & Unsplit # 2 |
|
Unedited |
1.890000 |
||||
|
10 |
1.937000 |
1.890000 |
0.296000 |
0.297000 |
|
|
20 |
1.938000 |
1.891000 |
0.297000 |
0.282000 |
|
These results met our expections. We had anticipated time savings given the large reduction in size and feature complexity, and we experienced significant time savings. However, we realized that the limited access highway shapefiles were relatively small. As a result, we decided to take an "average" Florida county and use the all-roads shapefile (also an "average-size" shapefile) for further testing of both generalization and image creation.
As our test case we used an all-roads layer extracted from TIGER 2000 for Alachua County. Alachua County is near the middle of the range found in Florida for the all-roads shapefile in terms of size. There are 26,561 arcs in the all TIGER-based shapefile. Only a few attributes were retained in these shapefiles: only those needed for labeling. Stripping out the unnecessary attributes resulted in a "narrow" attribute table. Tables 7 and 8 present the generalization statistics for the all-roads layer of Alachua County.
Table 7. Generalization results for the all-roads layer of Alachua County.|
GENERALIZATION TESTING RESULTS - ALACHUA COUNTY All Roads (From TIGER 2000) |
||||||
|
Generalized Only |
Generalized & Unsplit |
|||||
|
Tolerance |
Vertices Removed |
Length Reduced (m) |
Area Adjusted (sq m) |
Vertices Removed |
Length Reduced (m) |
Area Adjusted (sq m) |
|
10 |
13806 |
8722.96 |
3.80E+06 |
16298 |
8680.39 |
4.30E+06 |
|
20 |
17691 |
23958.86 |
8.93E+06 |
20346 |
24283.09 |
9.84E+06 |
|
30 |
19265 |
37294.06 |
1.31E+07 |
22018 |
38624.71 |
1.43E+07 |
|
40 |
20180 |
50373.26 |
1.70E+07 |
23048 |
53715.55 |
1.88E+07 |
|
50 |
20800 |
63339.36 |
2.06E+07 |
23776 |
69278.16 |
2.30E+07 |
|
Vertices Before Generalization = |
72060 |
|||||
|
Length Before Generalization = |
5332965.4 |
|||||
Table 8. Shapefile sizes (.shp file only) from Alachua County generalization tests.
|
ALACHUA COUNTY SHAPEFILE SIZES (.shp only, KB) |
||
|
Generalized Only |
Generalized & Unsplit |
|
|
Source |
2641 |
2361 |
|
10 |
2425 |
2107 |
|
20 |
2364 |
2042 |
|
30 |
2338 |
2016 |
|
40 |
2323 |
1999 |
|
50 |
2313 |
1987 |
|
# Arcs |
26561 |
22582 |
Table 9 shows the image creation times for different levels of generalization and for split and unsplit lines. Two facts become apparent from looking at the tables. Firstly, despite the fact that thousands of vertices were removed, the shapefile size was not reduced by much. Secondly, the image creation times are not very different: just over one second separating the fastest and the slowest times. Further, the reader may note that the twenty-meter generalized and unsplit time was actually slower than its 10-meter counterpart. We believe this is due to other system processes soaking up CPU resources. It does, however, emphasize what we believe to be the fact that generalization of the all-roads layer did not net significant results.
Table 9. Image creation times for Alachua County generalization tests (in seconds).|
IMAGE CREATION TIME All Roads / Alachua County (Seconds) |
|||
|
Tolerance |
Unedited |
Generalized Only |
Generalized & Unsplit |
|
Unedited |
7.579000 |
||
|
10 |
7.453000 |
6.531000 |
|
|
20 |
7.515000 |
6.562000 |
|
The fact that the results for the all-roads Alachua County tests did not seem to agree with the results of the limited access highway test for the state caused us consternation. What explains the apparent different results? We believe the apparent contradiction is caused by the nature of the two layers. The limited access layer was initially composed of many small lines sharing common endpoints. Generalizing and unsplitting greatly reduced the number of vertices and resulting shapefile sizes. The all-roads layer started out with many small segments and remained that way since the layer has many road intersections. There was not the opportunity to join the lines (using UNSPLIT) as there were few pseudo nodes. The shapefile size reduction was commensurately small. As a result, there were little gains to be had by generalizing the shapefile.
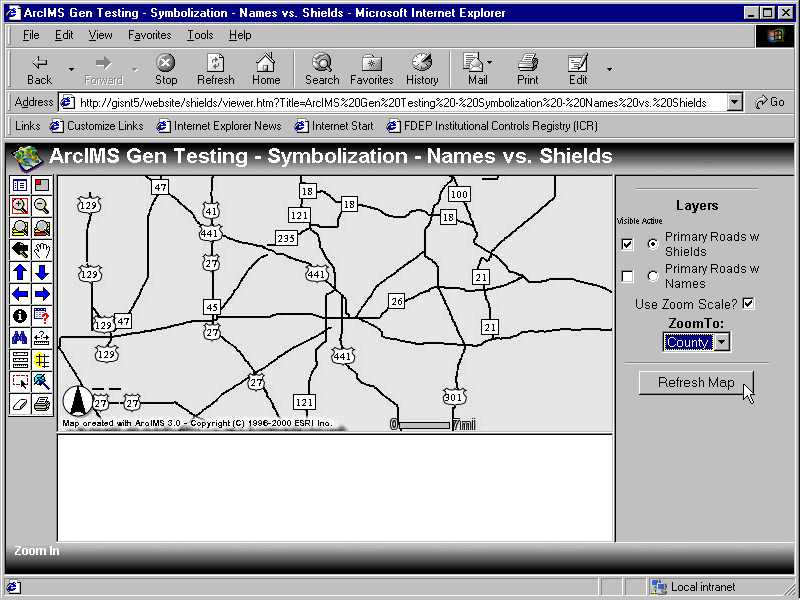
One question we had concerning attributes related to file size. Do more attributes (a "wide" attribute table) slow image creation times? Another question related to attributes deals with attribute indices. Are attribute indices used by the valuemap renderer? To help answer these two questions we created image map services to display shapefiles with and without attributes. We also created a service using a valuemap renderer on a shapefile with and without an index on the rendering field. We then altered the HTML viewer by adding JavaScript code that allowed us to zoom to five predefined scales: statewide, regional, county, city and quad. We recorded test results at these five scales to determine if the answers to the questions posed were scale-dependent. See Appendix C for a screen capture of the HTML viewer used in testing.
Table 10 shows the results of the many attributes versus few attributes test. The shapefile used for the testing was the all-roads layer for Florida. The many attribute version contained all 25 of the TIGER attributes. The few attributes version contained the four TIGER fields needed for labeling. Note the attribute file sizes in Table 10. As can be seen from the table, image creation time is decreased by reducing the size of the attribute table. However, the decrease is not proportional to the file size decrease.
Table 10. Image creation times for many attributes versus few attributes.|
IMAGE CREATION TIME AT SELECTED ZOOMS Many Attributes Vs Few Attributes |
|||||||
|
File Size (MB) |
Image Creation Time (Seconds) |
||||||
|
DBF |
SHP |
State |
Regional |
County |
City |
Quad |
|
|
Many Attributes |
240.714 |
135.352 |
855.046 |
115.453 |
20.765 |
5.031 |
1.406 |
|
Few Attributes |
60.197 |
135.352 |
679.812 |
107.359 |
17.797 |
4.407 |
0.797 |
The other question of interest was the effect of attribute indices on valuemap rendering. Table 11 shows the image creation times for the statewide all-roads layer using a valuemap renderer. In one case there was an index on the lookup field, in the other there was no index for the lookup field. As can be seen, there appeared to be no decrease in image creation speed achieved when a lookup field index was available.
Table 11. Image creation times using a valuemap renderer with and without an index.|
IMAGE CREATION TIME AT SELECTED ZOOMS Valuemap Renderer With And Without Index |
|||||||
|
File Size (MB) |
Image Creation Time (Seconds) |
||||||
|
DBF |
SHP |
State |
Regional |
County |
City |
Quad |
|
|
With Index |
60.197 |
135.352 |
- |
121.171 |
20.140 |
4.984 |
0.828 |
|
Without Index |
60.197 |
135.352 |
- |
120.594 |
20.297 |
4.906 |
0.813 |
The reader may note that timings for the State level are not shown above. The time required to create the image exceeded the browser�s default attention span: the browser never loaded the image. Interestingly however, the service log showed the image creation time, and in fact, the image had been created. Even more interestingly, we noted similar but more pronounced behavior when testing for the use of the spatial index. We found that in the absence of the spatial index, we could not retrieve an image larger than the quad zoom. The time to create the quad image without the spatial index exceeded 311 seconds (versus 0.813 seconds with the index). What�s more, at the zooms larger in area (smaller in scale), the image service hung.
ArcIMS provides many ways to render and symbolize. We were interested in learning if some methods were much more efficient than other methods. We had six questions in this regard. (1) Assuming you have a fixed number of features to render, is it faster to have them all in one layer or classified into separate layers that are all drawn? (2) A follow up to the first question is whether the answer is scale dependent. (3) What does labeling cost in terms of image creation? (4) What does the use of the special effects such as shadowing and glowing cost in terms of image creation? (5) Are labels or shields cheaper? (6) In applying scale-dependent rendering, is it better to use scale-dependent layers or scale-dependent valuemap rendering?
To answer the first and second questions posed, we broke the statewide all-roads layer extracted from TIGER 2000 into four classed layers based on the CFCC code (Axx � limited access, Bxx � primary roads, Cxx - connectors, and Dxx � local roads). We then created an image service with the all-roads composite layer and the four road type layers. The layers displayed and the display scale were controlled using the same customized TOC employed in the attribute testing. It included the normal layer check boxes, plus a customized dropdown box for scale selection. The "Refresh Map" button was used to trigger a redraw. The same features with the same attributes were being displayed using the same symbology (a simple renderer in this test) for all scale levels. Table 12 below shows the test results. As can be seen, it appears to make very little difference across the range of scales tested.
Table 12. Image creation times comparing one comprehensive layer to several component layers.|
IMAGE CREATION TIME AT SELECTED ZOOMS One Layer Vs Four Layers (Same Data & Symbology, Different Number of Layers, Seconds) |
|||||
|
State |
Region |
County |
City |
Quad |
|
|
Statewide All-roads |
Not tested |
114.906 |
20.703 |
5.016 |
1.000 |
|
Statewide Four Layers |
Not tested |
112.047 |
18.656 |
5.141 |
1.015 |
To answer the third and fourth questions posed above, we created three image services using the statewide connector roads (extracted from TIGER 2000, CFCC = Cxx, .shp file size of 4.07MB): one with no labels; one with labels; and one with labels, shadow and glow. We tested across a range of scales identical to those described in the preceding section. Table 13 shows the results of the testing.
Table 13. Image creation times comparing labeling and special effects.|
IMAGE CREATION TIME AT SELECTED ZOOMS Labeling And Special Effects (Statewide Connector Roads, Seconds) |
|||||
|
State |
Region |
County |
City |
Quad |
|
|
No Labels |
11.922 |
2.093 |
1.110 |
0.281 |
0.219 |
|
Labels |
19.531 |
3.328 |
1.812 |
0.375 |
0.250 |
|
Labels, Shadow & Glow |
19.860 |
3.453 |
2.032 |
0.422 |
0.250 |
As can be seen from the table, the use of labels costs a bit of time at the smaller scales, but is reduced as the scale increases (as area shown becomes smaller). When the image scale gets down to the quad view, the time penalty for labels is negligible. However, the results also show that if labels are to be used, the addition of special effects imposes essentially no penalty. The good news is if you are going to label (which is obviously very helpful to map readers), you might as well go all the way for visual effect!
The last question we had in the symbology realm was whether labeling or the use of highway shields was cheaper. We recognize that from a cartographic standpoint, the decision would ideally be dictated by the needs of the map. However, we felt it would be good to know if there was a particular time penalty involved with the use of shields, or if such use was preferable. To test the question, we created two image services using the statewide primary roads layer extracted from TIGER 2000 (CFCC = Bxx): one using labels and one using highway shields. Table 14 show the test results.
Table 14. Image creation times testing labels versus shields.|
IMAGE CREATION TIME AT SELECTED ZOOMS Labels Versus Shields (Statewide Primary Roads, Seconds) |
|||||
|
State |
Region |
County |
City |
Quad |
|
|
Labels |
29.563 |
6.609 |
2.062 |
0.844 |
0.250 |
|
Shields |
26.281 |
5.563 |
1.813 |
0.719 |
0.250 |
As can be seen from the table, shields are cheaper at the smaller scales. At the larger scales the time saving using shields reduces to 0.
The last symbology question dealt with scale-dependent rendering. Is it faster to use multiple layers with scale-based display thresholds (MINSCALE and MAXSCALE AXL tags)? Or will it be faster to employ the SCALEDEPENDENTRENDERER using a VALUEMAP renderer on a composite single layer?
To learn the answer to the question, we created a statewide image service for the four components of the all-roads layer described previously. To recap, the four layers included limited access highways, primary roads, connectors, and local roads. The display of these four layers was controlled using the MINSCALE and MAXSCALE layer tags. We added the all-roads layer to the image service using a valuemap renderer. To the all-roads valuemap renderer we added scale-dependent renderer tags.
The MINSCALE/MAXSCALE and SCALEDEPENDENTRENDERER tag values were set so that the limited access and primary roads layers would show at the regional zoom. The connectors layer would be added to the display at the county zoom. The local roads would be added to the display at the city and quad zooms. The state zoom was not tested as noted in Section 4.
To see if an attribute index on the lookup field of a valuemap renderer helped, we tested with and without an index on the lookup field. In this case, the lookup field was the CFCC2 field which contains the first two characters of the three-character CFCC code (defining the road classification). As with the previous testing, the symbology and total feature set at each scale displayed was identical for the all-roads layer and the four classed layers.
Table 15. Scale-dependent rendering tests.|
IMAGE CREATION TIME Scale-Dependent Rendering - Valuemap Vs. Multiple Layers with Display Thresholds (Seconds) |
|||||
|
State |
Region |
County |
City |
Quad |
|
|
All-roads, Scale-Dependent Valuemap No Index |
Not tested |
117.250 |
20.500 |
5.437 |
0.906 |
|
All-roads, Scale-Dependent Valuemap with Index |
Not tested |
124.890 |
22.578 |
6.188 |
1.390 |
|
Four Layers, Min/Max Display Scale |
Not tested |
5.000 |
2.469 |
4.500 |
0.782 |
Table 15 shows the results of the tests. Paradoxically, using an index on the valuemap lookup field seemed to slow image creation. Clearly either the index is not being used or it is being used inefficiently. The four layers using minimum and maximum display thresholds were much faster than scale-dependent valuemap rendering across the scale range tested. Appendix D contains the AXL file used in this testing.
So what did we learn from our testing? On generalization, the most complex question we tackled, we learned that "it depends." We learned that generalization can be used to reduce the complexity of line features and to reduce the size of the shapefiles. We learned that to maximize generalization, you must both UNSPLIT the lines and then run the generalization script to remove the unnecessary vertices. The image creation time reduction will be a function of how many lines can be joined, vertices removed, and shapefile size be reduced. If your data is very amenable to generalization, then significant image creation time can be saved. If your data is not very amenable to generalization, then not much time can be saved. We also found no thresholds in image creation: the time needed varies fairly directly with the number of lines and vertices to be rendered.
With regard to attributes, we learned that reducing the number of attributes in your shapefiles reduces image creation times, but not by much and not in proportion to the reduction in shapefile size. We further learned that attribute indices appeared to have no effect on valuemap rendering times. We found that the a spatial index is essential for successful map display.
From a symbology standpoint, we saw that for drawing the same set of features, there was no significant difference between rendering one layer and several layers. We also learned that using labels takes extra time, but the difference at larger scales is almost negligible. We also saw that the additional cost of adding shadows and special effects to labels is negligible. In considering different approaches to labeling, we found that shields are generally faster to render than labels.
Where do we go from here? Our plan is to create our production background shapefiles for our initial ArcIMS deployment based on what we have learned. Once our background shapefiles have been built, we will migrate them to ArcSDE. We will then perform some basic performance tests on ArcSDE by way of comparison to our results with shapefiles.
Through our work so far, we have come to two conclusions. Firstly, ArcIMS will enable us to deliver GIS services to our agency users and the citizens of Florida much more easily and cheaply than has been the case in the past. Secondly, that a lot of work needs to be done to determine how to most efficiently deliver those services via the Internet.
Barnett, L., and Carlis, J. V. (1996) "A 'Roads' Data Model for Feature-Based Map Generalization." 4th ACM Workshop on Advances in GIS. New York: ACM Press, pp 59-67.
Carnes, R. (2001) Posting on the Esri ArcIMS User Forum Web Site [http://www.Esri.com].
Esri (1996). Automation of Map Generalization: The Cutting Edge Technology, Esri White Paper, Redlands, California.
Esri (2000). Map Generalization in GIS: Practical Solutions with Workstation ArcInfo Software, Esri White Paper, Redlands, California.
Goreham, D., Naftzger, M., Roth, K., and Calkins, J. (undated). FGDC Framework Workshop: Generalization Routines (workshop report).
Harvey, F. (undated). "Generalization and GIS - Holism and Hurpose, Conceptualization and Representation," at University of Kentucky web site [http://www.uky.edu/ArtsSciences/Geography/faculty/harvey/gi_generalization.html].
Lee, D. (1994). "Knowledge Acquisition of Digital Cartographic Generalization." Proceedings of the Fifth European Conference and Exhibition on Geographic Information Systems, EGIS `94, Utrecht: EGIS Foundation, vol. 2, pp. 1634-1647.
Persson, J. (1994). "A Resource Based Approach to Generalization in the Context of GIS." Proceedings of the Fifth European Conference and Exhibition on Geographic Information Systems, EGIS `94. Utrecht: EGIS Foundation, vol. 1, pp. 142-150.
Richardson, D. E. (2000). "Generalization of Road Networks," at Canada Center for Remote Sensing web site [http://www.ccrs.nrcan.gc.ca/ccrs/tekrd/rd/apps/map/current/genrne.html].
Robinson, A.H., and Sale, R.D. (1969). Elements of Cartography, Third Edition, New York: John Wiley & Sons, Inc.
Wang, Z., and Muller J.C. (1993). "Complex Coastline Generalization." Cartography and Information Systems, vol 20, no. 2, pp. 96-106.