Sandra K. Franken
Dean J. Tyler
Kristine L. Verdin
Raytheon
EROS Data Center
Sioux Falls SD
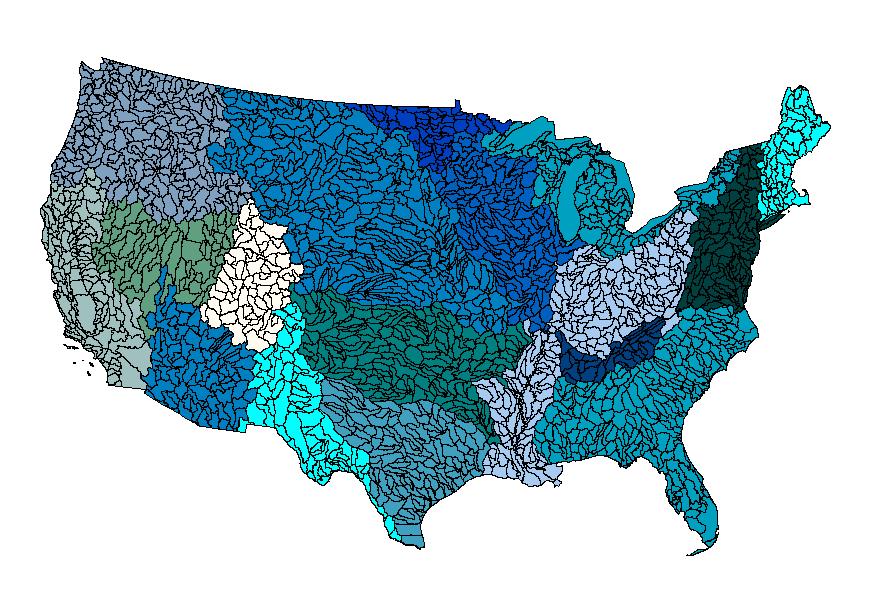
The recent completion of the National Elevation Dataset (NED) and the National Hydrography Dataset (NHD) has provided an avenue for nationwide development of topographically derived hydrologic data layers at a scale of 1:24,000. This multilayer dataset of hydrologic derivatives, entitled the Elevation Derivatives for National Applications (EDNA), is being developed by a consortium of participants, including the U.S. Geological Survey (USGS), National Weather Service (NWS), the Environmental Protection Agency (EPA) and others. After the dataset is completed, terabytes of data will need to be stored, managed and distributed. To facilitate browse and, ultimately, delivery of the EDNA data, the consortium decided to manage the data layers with ArcSDE and provide browse and delivery of the data through the use of ArcIMS.
____________________________
* Raytheon ITSS, USGS EROS Data Center, Sioux Falls, SD 57198 (Work performed under U.S. Geological Survey contract 1434-CR-97-CN-40274.)Any use of trade, product, or firm names is for descriptive purposes only and does not imply endorsement by the U.S. Government.
Any use of trade, product, or firm names is for descriptive purposes only and does not imply endorsement by the U.S. Government
Increasingly, many local, state, and federal agencies that have the mandate for management of water resources are finding that their needs are not being met by existing digital data sets. Current national coverage of digital data sets, such as, drainage basin boundaries and consistent elevation-derived parameters, do not exist or are not of a suitable scale or consistency to allow management of small or mid-size watersheds. This problem has become more significant as the management of water resources, both in terms of quantity and quality, is becoming more and more based on the watershed scale.
In 2000, the U.S. Geological Survey (USGS) EROS Data Center completed the first version of the periodically updated National Elevation Dataset (NED). Completion of this dataset has provided an avenue for nation-wide development of topographically derived hydrologic data layers at a scale of 1:24,000. The goal of this data development effort has been to develop, in a systematic and consistent fashion, many of the topographically-derived data layers used in modeling efforts. These derivative layers make up a multi-layered dataset, entitled Elevation Derivatives for National Applications (EDNA), being developed by a consortium of participants, including the USGS National Mapping Division (USGS/NMD), the USGS Water Resources Division (USGS/WRD), the National Weather Service (NWS), the Environmental Protection Agency (EPA), and others.
The impetus for the development of this dataset has been multi-faceted:
À The development of the EDNA dataset was to be responsive to the need for better drainage basin boundaries for the country. The new Watershed Boundaries Dataset (WBD) strives to identify the "best-available" watersheds boundaries available on a national level. Development of the EDNA derived Cataloging Unit, Watershed, and Subwatershed boundaries will be used to provide high-resolution boundaries for the WBD.
À The EDNA dataset will provide the capability of developing drainage basin boundaries above any point, and provide downstream linkages within the U.S. With this information available on a national scale, impacts of pollutant spills can be easily traced through the network, drainage areas above any point, not just terminal points of pre-defined watersheds, can be determined, and watershed units and stream segments downstream of a point-source discharge along with the location of the stream segment to which the point-source discharges can be easily be identified.
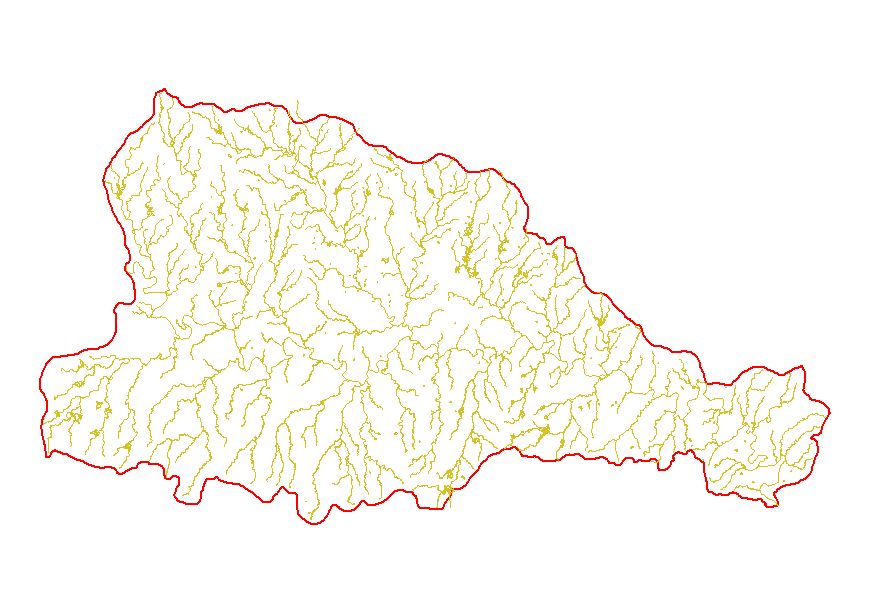
À Development of the EDNA dataset will serve to integrate two of the USGS' key national dataset, the NED and the NHD. Enhancements to both datasets will be expected as the quality control procedures used in the development of the EDNA provide feedback to both NED and NHD. The NHD will be further enhanced by consistency with the EDNA. Elevation-derived streamline and basin parameters can be transferred onto the NHD following conflation with the EDNA. This will provide valuable attributes useful in model parameterization.
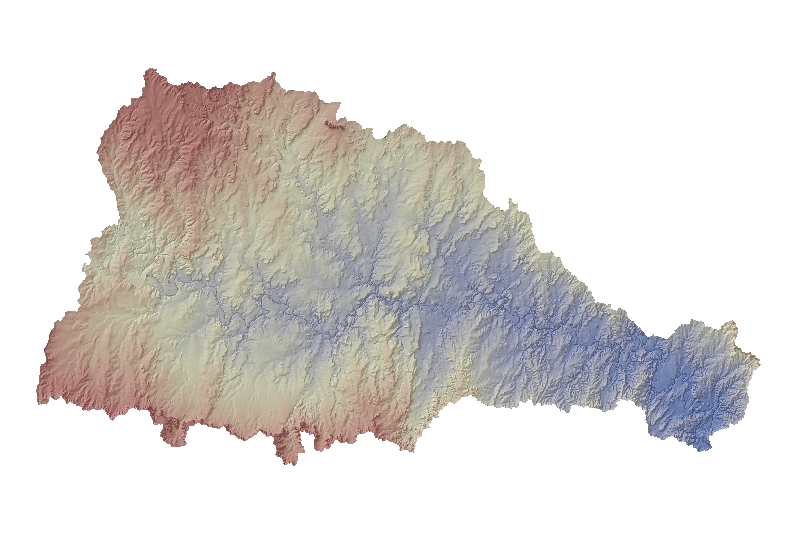
The development of EDNA required intense planning processes. The goal was to generate a seamless 30 meter product for the United States. While many of the tools used in the EDNA development have been implemented in standard Geographic Information System (GIS) software and used for small to moderate size applications, application of the tools to a problem of this size had not been attempted before. Due to the complexity of the project, three stages were necessary to process, store, manage, and distribute several terabytes of data. The purpose of this paper is to discuss EDNA Stage I data layers, as well as, the procedures developed to load, manage, and distribute the data.
If software and hardware capabilities had been up to the task, processing of the EDNA Stage I layers would have been done in one pass; processing the entire NED into hydrologic derivatives in one large piece. However, the NED data, which forms the basis for the EDNA dataset, is a very large Digital Elevation Model (DEM), requiring almost 60 GB of disk space for the conterminous United States alone. The size of the problem required a unique solution.
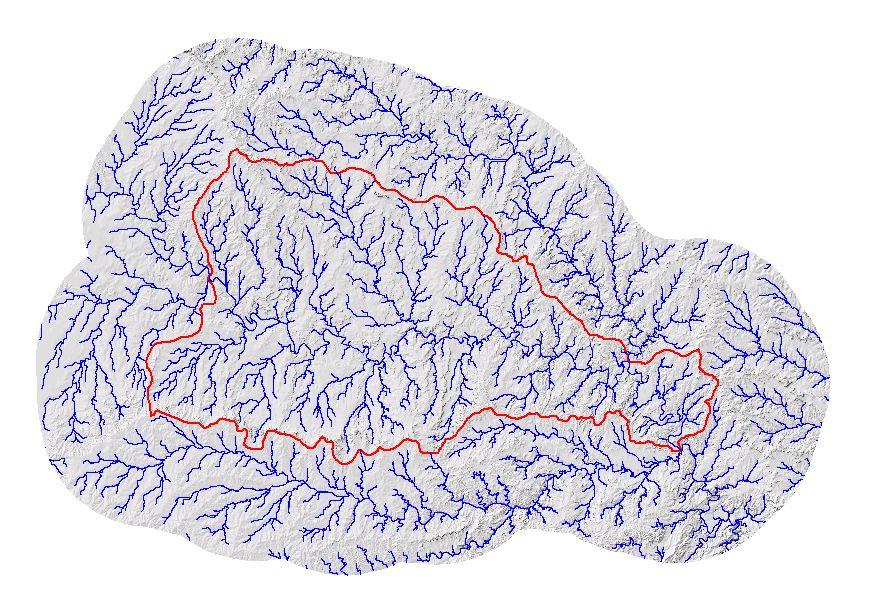
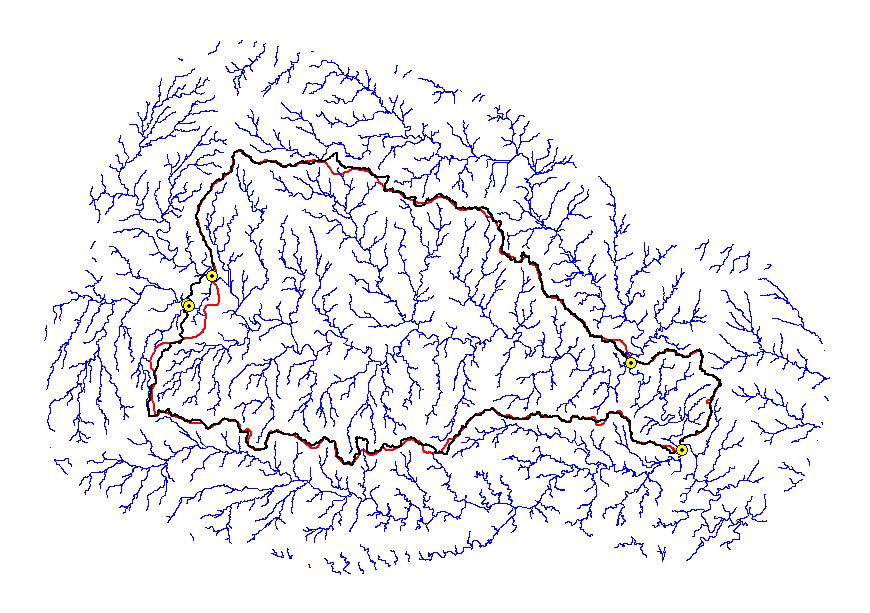
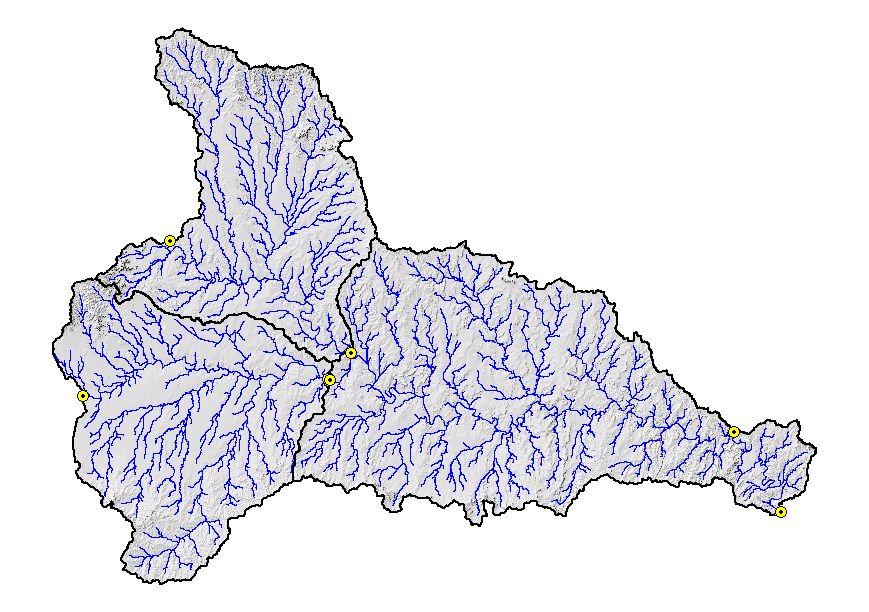
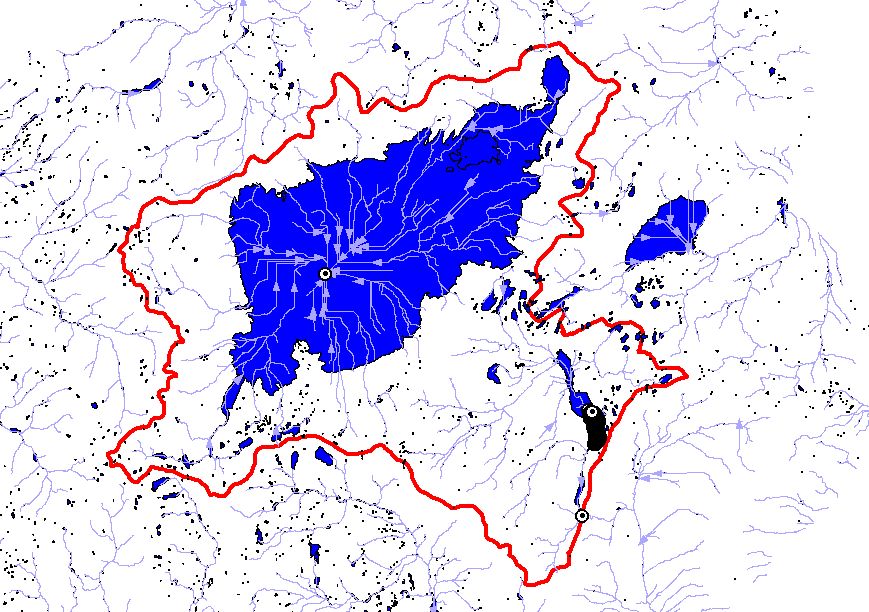
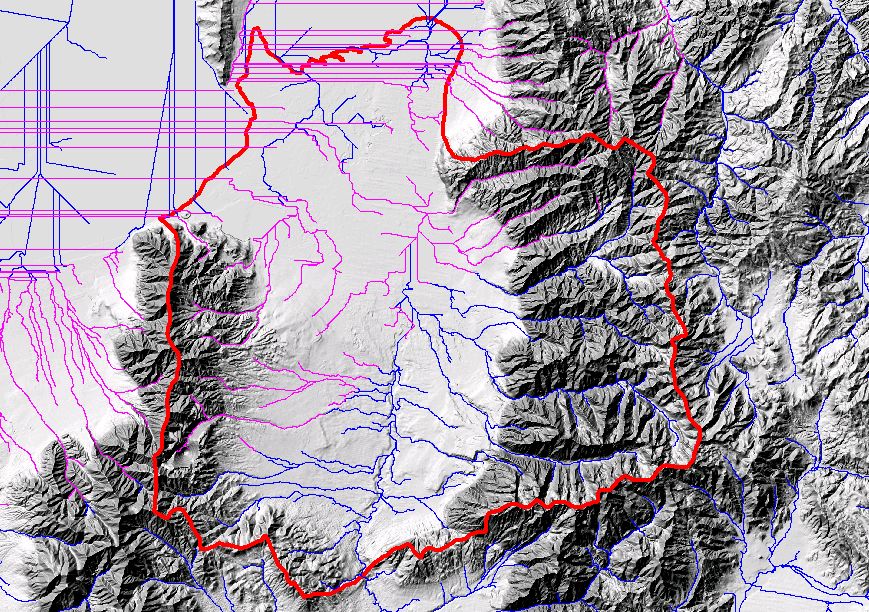
Utilizing the digital Hydrologic Units of the United States (Seaber, et-al, 1994), the EDNA Stage I data products were developed on a Cataloging Unit (CU) by Cataloging Unit basis. The Cataloging Units were chosen as the processing units, not only because they subdivided the NED into smaller, more manageable units, but because these units are “hydrologically based.” The boundaries of the Cataloging Unit more or less approximate hydrologic divides, which makes the task of assembling the pieces back into a seamless dataset somewhat easier.
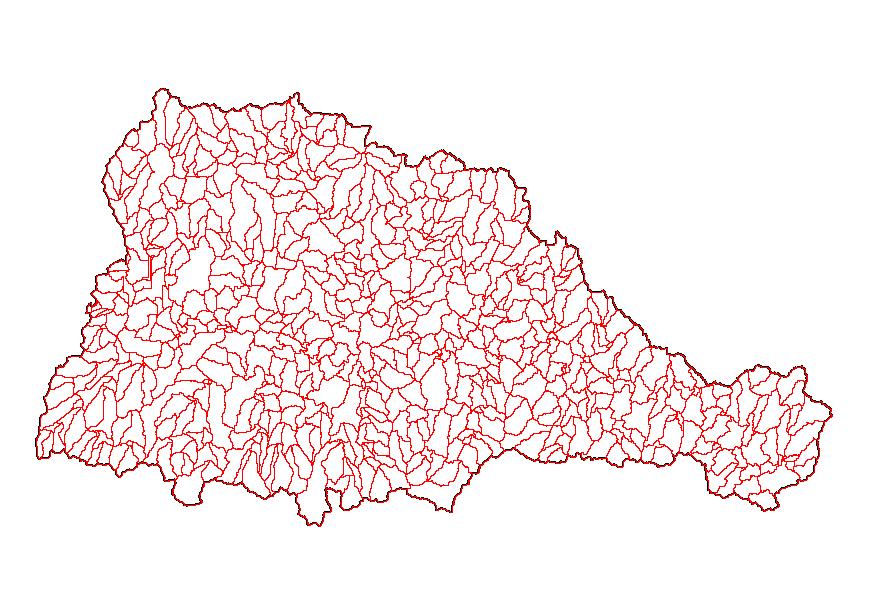
EDNA Stage I, or semi-blind pass processing, was designed to gather the required raw data, to organize that data, and to execute the preliminary processing with the minimum amount of interaction between the processing system and the operator. EDNA Stage I is an ArcInfo process that results in the generation of 11 grids and 18 coverages. It consists of a set of arc macro languages (amls) that execute the required tasks in an almost fully automated procedure. For every Cataloging Unit in the U.S., the following procedures are undertaken to create the Stage I EDNA layers:
It is critical to approach the Stage I process with caution. Inaccurate placement of the selected seed point with respect to adjacent Cataloging Unit synthetic streamlines will lead to an accumulation of problems that will ripple outward affecting all watershed boundaries surrounding the one being processed. As a result, numerous Cataloging Units will need to be reprocessed to correct the areas affected by the initial error.
After completion of the automated process, a cursory quality review is conducted to identify gross inconsistencies between the Cataloging Unit boundary or the drainage derived from the elevation data and the existing Hydrologic Unit boundary or NHD drainage pattern. The purpose of the review at this point in the procedure is to resolve major problems that, if left unresolved, have the potential to render further processing unacceptable. The review consists of a visual and statistical comparison of the derived Cataloging Unit boundary, and the derived drainage with the existing Hydrologic Unit boundary and NHD drainage pattern.
Before incorporating the Stage I data layers into the seamless data set, the data are checked to ensure that they are, in fact, seamless, without any gaps or overlaps. Additionally, the flow accumulation grid is adjusted to account for upstream drainage. The stream and drainage basins are attributed with a Pfafstetter code (Verdin & Verdin, 2000) to allow for rapid up and downstream tracing. Following these procedures, the data are loaded into SDE for subsequent access, viewing, analyses and downloading portions of the dataset.
The EDNA Stage I semi-blind pass process results in terabytes of data for each Cataloging Unit. The following grids are created and retained during the Stage I process. The grids are listed and described in the order in which they are created. Each of the grids covers an area equal to the extent of the Cataloging Unit plus the buffer zone of 25,000 meters.
The goal of the EDNA project was to create a seamless dataset derived from a hydrologically conditioned DEM. In theory, the Stage I process seemed simplistic at a smaller scale, such as the processing of one Hydrologic Unit. However, approaching Stage I at the magnitude of a national scale, where over 2,000 different watershed circumstances exist, warrants discussion of issues that needed to be resolved.
Several problems surfaced during the Stage I process that required a significant amount of time to correct in order to continue production of the Stage I seamless dataset. These include the necessity of coincident stream lines and seed points, overcoming flow direction errors in coastal regions and flat areas, sufficient buffer distances to generate correct flow accumulation and flow direction, controlling flow direction into and not out of closed basins, and storing several terabytes of data. These situations occurred individually and simultaneously throughout several Cataloging Units.
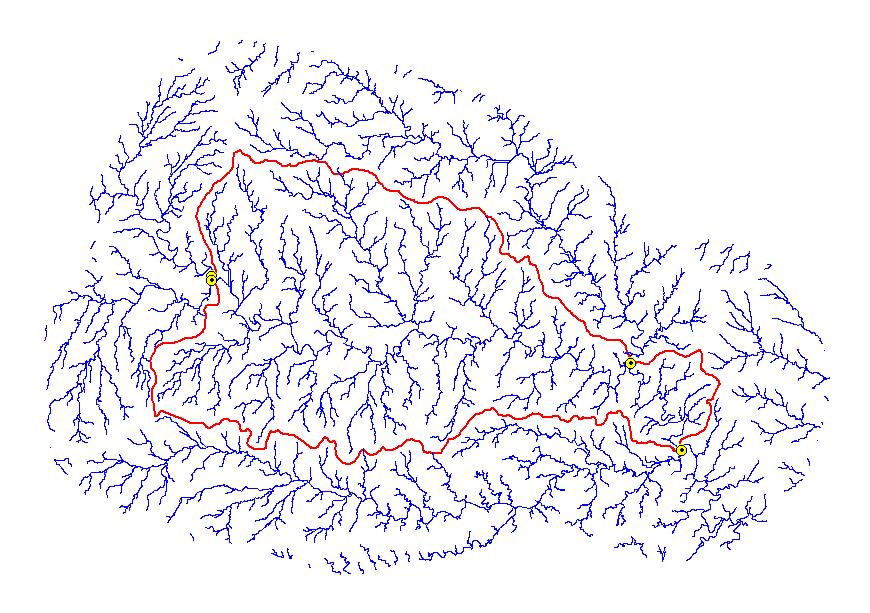
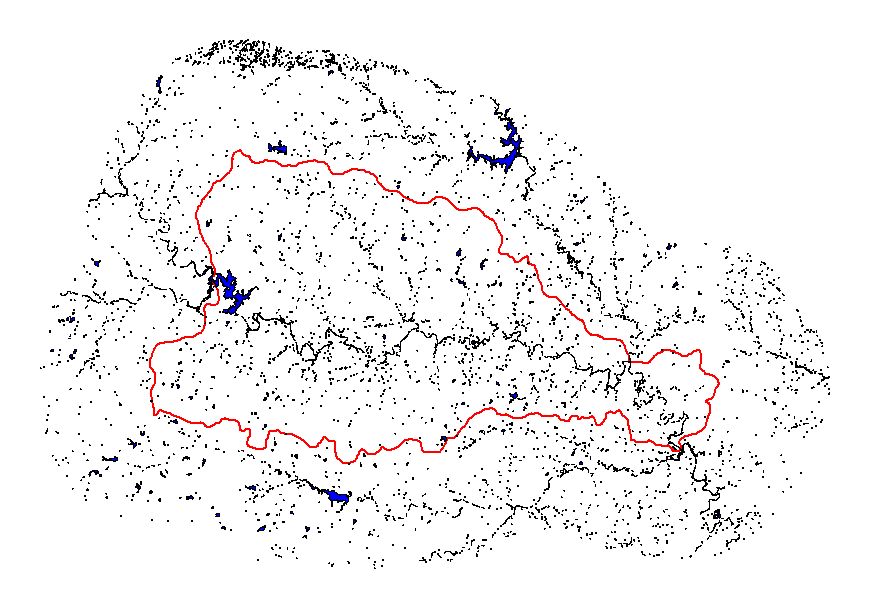
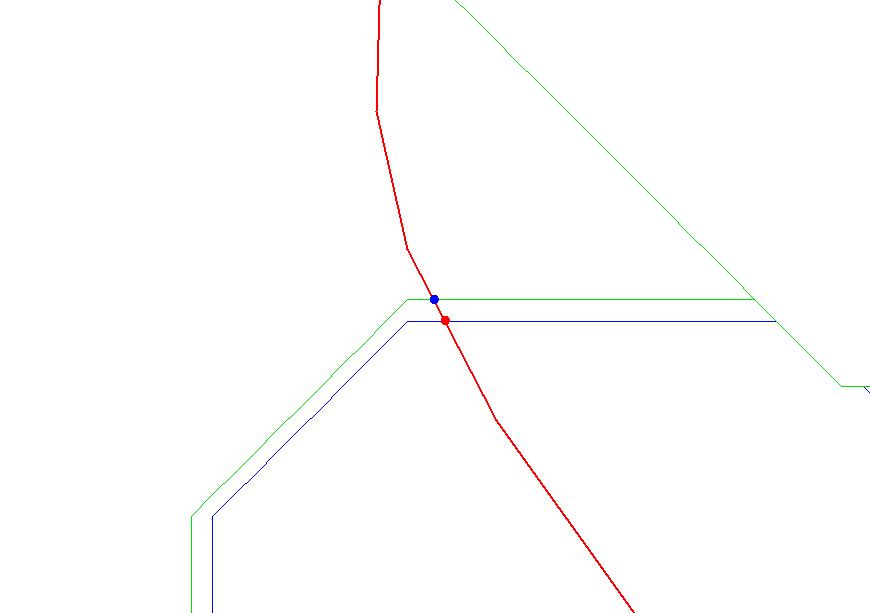
Coincident streamlines and seed points were critical to the Stage I process. If one Cataloging Unit’s stream lines were not coincident with adjacent Cataloging Unit’s stream line at the intersection where seed points were placed, seed points were moved upstream or downstream to a place where coincident stream lines existed. The movement of seeds was time consuming because it not only involved the Cataloging Unit that was being processed, but also all Cataloging Units surrounding the one that was being processed. One correction affected numerous areas, and thus the reprocessing of all affected Cataloging Units was necessary. The disadvantage of moving seed points was the deviation from the original digitized 1:250,000 Hydrologic Unit polygon, the huc_poly. However, this was necessary to create a Stage I seamless streamline coverage, and thus seamless coverages for the entire project.
At times, coincident streamlines did not exist at all as was the case in flat and coastal areas. The flow direction per pixel did not have a well-defined path, therefore, Stage I stream lines resulted in perpendicular stream lines in one Cataloging Unit versus an adjacent Cataloging Unit. In these situations, movement of seed points was also necessary to maintain the seamless streamline coverage, and again, the deviation from the 1:250,000 Hydrologic Unit polygon. Sometimes this problem was overcome by rerunning the semi-blind pass process at a larger buffer, such as a 50,000 or 80,000 meter buffer. The larger buffer allowed for relief to correct the flow accumulation so the flow direction would be corrected.
Closed basins are Cataloging Units where no flow drains out of the unit, however, flow may or may not come into the unit. In an open basin Cataloging Unit, the filling process allows flow only toward the edge of the DEM. In the case of a closed basin, locate points were instrumental in preventing a “true sink” within the Cataloging Unit from “filling up” and spilling off the edge of the DEM. These points were placed wherever a “true sink” existed within the Cataloging Unit to allow flow to occur not only toward the edge of the DEM, but also through the locate points.
Stage I processing of closed basins required intensive research to reach a determination whether a Cataloging Unit should be processed as an open or closed basin. The “smartlinks” coverage, showing connectivity from the centroid of one Cataloging Unit to the centroid of another Cataloging Unit, was used to determine whether or not a Cataloging Unit was, in fact, closed. The United States Geological Survey (USGS) Water-Supply Paper 2294, Hydrologic Units Maps (Seaber, et-al, 1994) was another valuable resource in the determination of closed basins. NHD coverages were utilized to visually determine if synthetic flow stopped within a Cataloging Unit.
The processing of closed basins was meticulous. Prior to processing a Cataloging Unit, it was imperative to determine if it was truly a closed basin. If a Cataloging Unit was processed as a closed basin when, in fact, it was an open basin, then incorrect placement of locate points within the watershed would “punch” holes through the DEM, and as a result data would be lost.
The EDNA project requires adequate storage space for the terabytes of data produced. The average size of a Cataloging Unit is 150 megabytes. With over 2000 Cataloging Units, excluding Alaska, the total storage space required for all stages of EDNA is at a minimum of 1.3 terabytes. These data are stored and managed on a Sun Ultra-Enterprise server on five separate disks, in addition to, archive storage on a silo tower, tapes and CDs from EDNA Stage I cooperators, and incremental backup storage of the processed data on the Sun server.
The EDNA Stage I seamless dataset will be loaded, stored, and managed in ArcSDE. This Relational Database Management System (RDMS) utilizes Oracle 8.1.7, and will provide an environment for multi-users to view the data via clients such as ArcExplorer, ArcView, ArcMap, or ArcIMS. The building of pyramids, the creation of statistics, and versioning will allow the end user to access, view, analyze, and download portions of the dataset.
The loading processes for vector coverages were fully automated using AML. Procedures resulting from a Cooperative Research and Development Agreement (CRADA) with Environmental Systems Research Institute, Inc. (Esri) were used to load and mosaic the EDNA raster layers into ArcSDE.
Development of the EDNA dataset required intense planning, research, production time, and storage space to produce a national seamless hydrologically derived watershed dataset. Stage I production of EDNA has been implemented by the USGS through application of Geographic Information Systems, and the assistance of a consortium of participants. Considering the magnitude and scope of EDNA, the production and management of the Stage I data have been successful. Utilization of ArcSDE will greatly enhance the availability of the data layers that contain valuable topological information that will lend itself to many regional to national applications.
Jenson, S.K. and J.O. Domingue,1988.Extracting topographic structure from digital elevation data for geographic information system analysis:Photogrammetric Engineering and Remote Sensing, Vol. 54, pp. 1593-1600.
Kelly, G., 2000.Description of Stage I NED-H processing and documentation of the output from Stage I Ned-H Processing, 1.
Seaber, Paul R., F. Paul Kapinos, and George L. Knapp,1994.Hydrologic Unit Maps.United States Geological Survey Water-Supply Paper 2294.U.S. GPO:Washington, D.C.
Verdin, K.L., and J.P. Verdin, 1999.A topological system for delineation and codification of the Earth’s river basins:Journal of Hydrology,Vol. 218, pp.1-12.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}