David P. Lanter
An enterpriseĺs GIS data and applications assets are developed in the context of specific product development projects. Knowledge about these and how to update products dependent on them is easily lost and forgotten. This paper presents an architecture for a SDE-based dynamic data warehouse that learns about its contents and how to update ArcGIS products derived from them. A schema is presented that organizes and catalogs geographic data assets. A workflow model sets up new product developments within an automated sequence of production processes. The result is an effective way to develop and maintain a geospatial data warehouse while conducting practical projects.
The evolution of the Esri product suite is resulting in a new class of heterogeneous GIS consisting of new and old systems. Some use these systems in a stand-alone environment, others in tandem. Individually, they have been rather efficient in their respective applications, data models, and programming environments. They have been supported with different computer hardware, system software, and professional personnel, often operating in their own distinct stand-alone environments. This paper presents a high level conceptual architecture for a GIS enterprise. It provides a federated solution for sharing heterogeneous GIS datasets and data processing methods unified to meet organizational sharing and reuse needs.
The architecture supports:
- Cataloging
- Browsing, accessing, reusing
- Updating
Earlier work illustrated implementation of dynamic metadata within data catalogs enabling users to browse, find, and reuse unknown environmental datasets (Lanter 1999; Michener, W.K., Lanter, D.P., and Houhoulis, P.F. 1997; Lanter and Essinger, 1995). For an enteprise geospatial data warehouse, data can be cataloged and stored with identifications concerning theme, source and product.
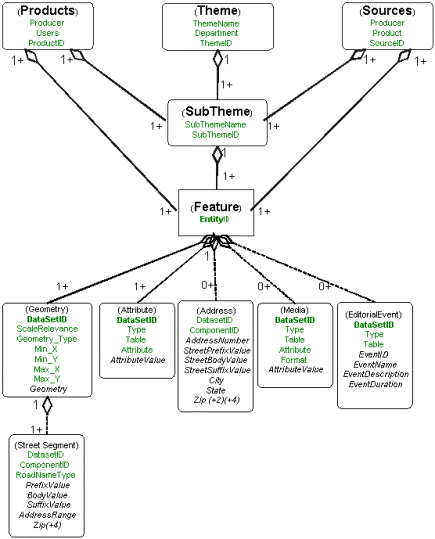
Theme Organization: Within the data catalog, data are organized thematically. The theme identifies which department and general geographic thematic data class the dataset belong to. Examples include: ôWater Departmentö, ôStreets Departmentö, or ôParks Department.ö Each theme is associated with a set of subthemes. The subtheme is a general feature class that designates the thematic make up of the specific data set. An example would be rivers, another would be sewer pipes.
Each subtheme consists of a collection of named, and possibly anonymous features. Examples of named features include Delaware River, JFK Boulevard, and Manhole 2857. In addition to its association with its subtheme (and transitively with its theme), each feature is identified with a persistent unique identifier (ôEntity-IDö). GIS data entities are associated with their geospatial data representations (i.e. geometry and attributes. They may also be associated with media (e.g. pictures, movies, or sound files) and any dynamic editorial event information (e.g. ôPhil and Friends concert Wednesday nightö). When appropriate addresses are included. Hospitals, precinct houses, commercial facilities, governmental offices or landmarks are all likely to have addresses. For named street features(e.g. JFK Boulevard), the geometry components corresponding to the street subnetworks (adjacent connected set of street segments) are uniquely identified and persisted, as are the individual street segments that comprise these subnetworks.
Product Organization: Within the data catalog, geographic information products are identified, as are users of the products. The latter is important to support identifying those potentially affected by data updates. Product catalog details will not be discussed in detail in this paper. Products are associated with the informational subthemes, features, data types, and datasets that comprise them.
Source Organization: Within the data catalog, data sources are identified as well as the producing agencies are described. Specific details of the source catalog are not discussed in this paper. What we are concerned with here is the relationship soures have to the data themes, features and ultimately to their transformation and storage within the warehouse.
A conceptual object model of the organization of themes, sources, products and database tables that will ultimate store them is presented in Figure 1 below:
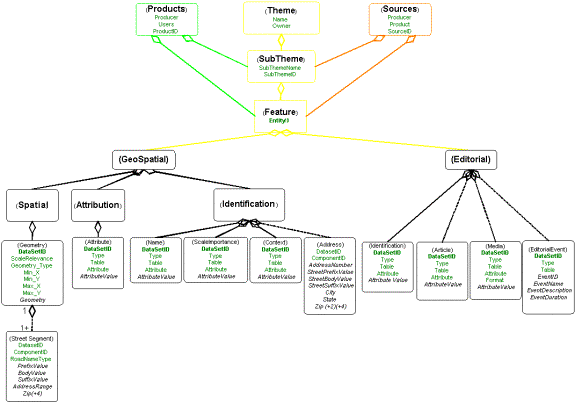
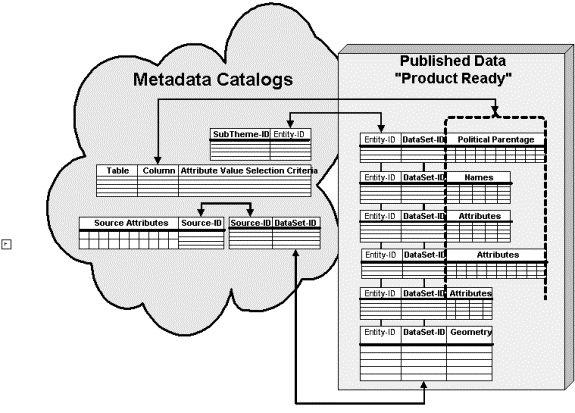
Figure 2 (below) illustrates that particular types of feature attributes can be broken out and clustered to provide support more powerful data browsing and search methods. For example, browsing methods can provide information on feature names, scales, and spatial contexts (larger surrounding features) for best viewing the map of the feature:
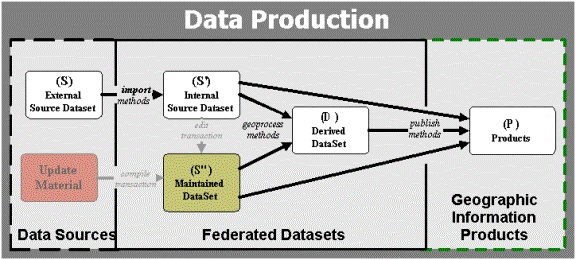
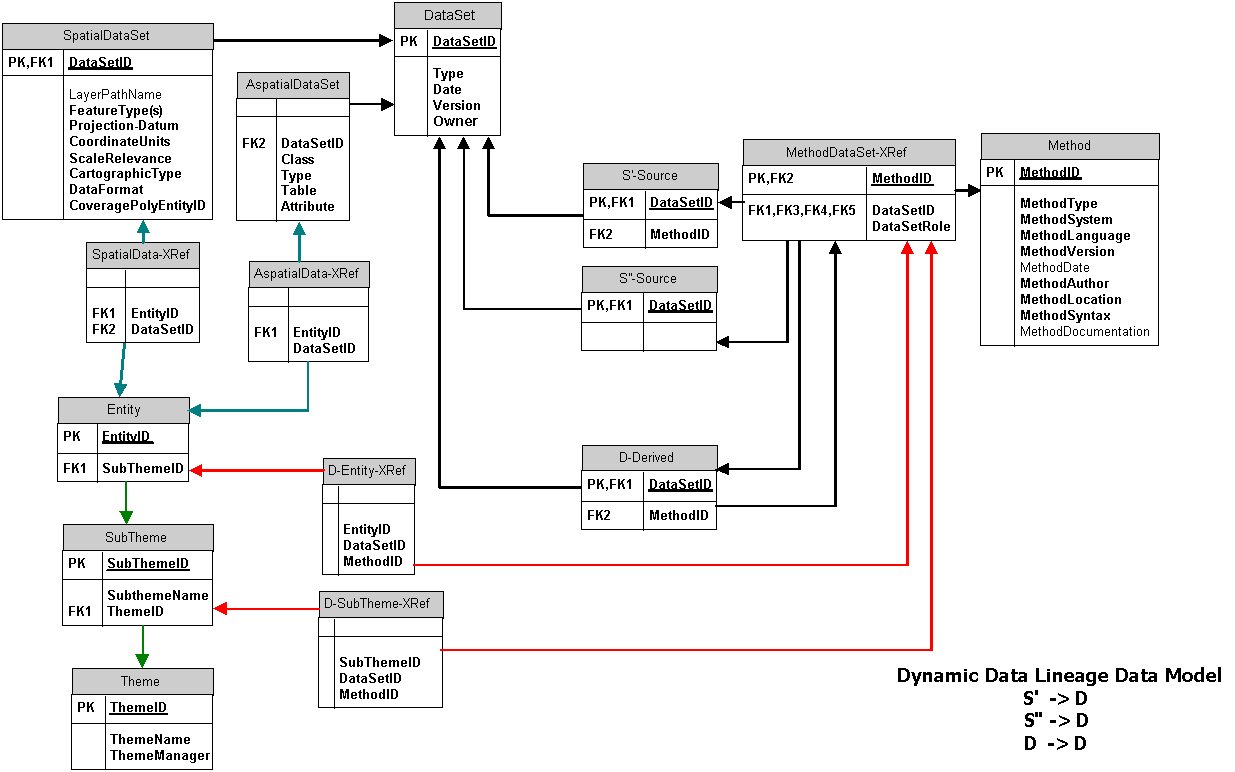
I have written much, perhaps too much, about dynamic data lineage metadata, representation and inference (Veregin, H. and Lanter, D.P. 1995; Lanter, D.P. and R. Essinger 1995; Lanter, D.P. 1994a, b, c; 1993a, b, 1992a, b, c; Lanter, D.P. and Veregin, H. 1992; Essinger, R. and Lanter, D.P. 1992; Lanter 1991a, b; 1990). Figure 3 (below) illustrates the data flows, transformational import, geoprocess and publising methods, and input/output dependencies existing among various data sources, maintained data, derived data and dependent data:
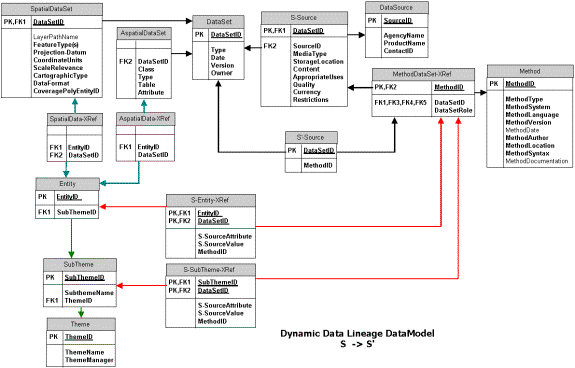
Data entered into the warehouse are accompanied with thematic, source, and product metadata in the data catalog. Lineage metadata is assembled for detailing the import methods applied to the data sources, geoprocessing methods for deriving new data, and publishing methods for extracting data and using with geographic information products. This lineage metadata is setup along with thematic crosswalks between source subtheme and entity identifications and their corresponding references in the enterprises catalog. This metadata is dynamic or active. It enables import, derivation, and publishing methods to be rerun on updated source materials to propagate these updates to affected internal data sources, derived datasets, and ultimately to products. This dyanamic metadata processing supports plugging Ĺn playing new data source updates and propagating ("rippling") updates throughout the warehouse. Figure 4 (below) illustrates how metadata can be assembled to support source thematic data cataloging, source to warehouse subtheme and entity identification translation crosswalks, and imports of updates to the warehouse to update dependent data:
Each department in an enterprise has needs for its own specific kinds of geographic data. As a result, they focus on collecting and developing data as well as applications ("methods") to process these data and meet their needs. These departments often depend on data from other departments to support their own work. Data developed within and among different departments, however, may be heterogeneous with respect to data format (e.g. coverage, shapefile, geodatabase, GRID, TIN, etc.). The methods to process these data are also often correspondingly heterogeneous with respect to software language, dialect, and computational environment. (e.g. AML, Avenue, AXL, VBA, VB, COM, etc.). Figure 5, below, illustrates how metadata can be assembled to track and reaply these applications to support interoperability of these data and the transformational methods they flow among. This logical model supports source update propagation to dependent derived datasets. It also, supports the development of heterogeneous applications that span across multiple data formats and applications environments.
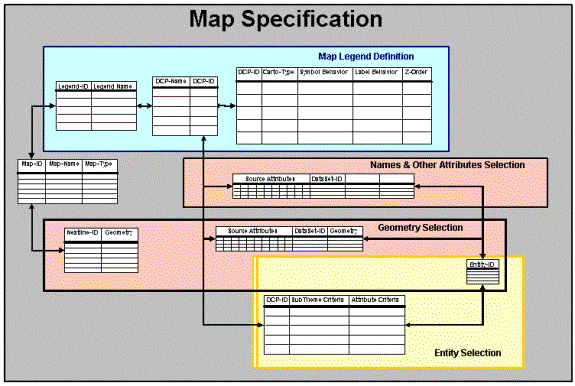
During geographic information product (map and report) production, thematic data is identified and selected from the catalog by subtheme and/or feature attributes. The specific representation (i.e. version) of the data is selected using source metadata (e.g. scale, date, quality, use restrictions, etc.). Data selection queries are formulated by combining subtheme and/or entity, with data source specifications. These identify and bring data from the warehouse in for product (i.e. map or report) development. Such queries are stored as the link between warehouse and product - and serve to close the gap in resolving product update needs and processes. This is illustrated in Figure 6:
Specific feature classes that will be symbolized and/or labeled are established and linked to the queries and the selected thematic subthemes/entities and datasets used to represent them. Cataloging the display class definitions (DCPĺs) and their relationships to the queries and the selected datasets is a critical element of knowing what data is used in which products. This also supports automated update propagation. This is illustrated in the Figure 7, below:
This paper has provided a rambling overview of how dynamic metadata can be setup and used within an enterprise warehouse to catalog, develop, and update datasets and dependent products. Illustrations of this architecture have been provided to demonstrate how the constituent metadata concerning sources of data, warehouse datasets, processing methods (import, geoprocessing, and publishing), and products can be assembled in a RDBMS and coupled with GIS data facilitated with SDE. This is the basis for data federation both within and across large GIS using organizations.
Lanter, D. 1999, "Environmental Data Explorer - An Intelligent Interface for Exploring Unfamiliar Environmental Data Sets", Papers and Proceedings of the Applied Geography Conferences, Volume 22, October 1999, Charlotte, University of North Carolina at Charlotte, North Carolina.
Michener, W.K., Lanter, D.P., and Houhoulis, P.F. 1997. "Geographic Information Systems for Sustainable Development: A Review of Applications and Research Needs", Sustainable Development in the South Eastern Coastal Zone, Editors: F. J. Vernberg et al. University of South Carolina Press. pp. 89-110.
Veregin, H. and Lanter, D.P. 1995. "Data Quality Enhancement Techniques in Layer-Based Geographic Information Systems", Computers, Environment and Urban Systems, Vol. 19, No. 1.
Lanter, D.P. and R. Essinger 1995, "Object-Oriented Exploration of Environmental Data Sets", GIS/LIS '95, Nashville, TN.
Lanter, D.P. 1994a. "A Lineage Metadata Approach to Removing Redundancy and Propagating Updates in a GIS Database", Cartography and Geographic Information Systems, Vol. 21, No. 2, pp. 91-98.
Lanter, D.P. 1994b. "Comparison of Spatial Analytic Applications of GIS", in Environmental Information Management and Analysis: Ecosystem to Global Scales, Editors: Michener, W.K. et al., London: Taylor & Francis, pp. 413-425.
Lanter, D.P. 1994c. "The Contribution of ARC/INFO's Log File to Metadata Analysis of GIS Data Processing", Proceedings of the Fourteenth Annual Esri User Conference, Palm Springs, California.
Lanter, D.P. 1993a. "A Lineage Meta-Database Approach Towards Spatial Analytic Database Optimization", Cartography and Geographic Information Systems, Vol. 20, No. 2, pp.112-121.
Lanter, D. 1993b. "Scale Independent Analysis of Spatial Analytic Applications of GIS", Environmental Information Management and Analysis: Ecosystem to Global Scales, May 20-22. Albuquerque, New Mexico.
Lanter, D. 1992a. "Intelligent Assistants for Filling Critical Gaps in GIS", Technical Publication 92-4, National Center for Geographic Information and Analysis, Santa Barbara, CA.
Lanter, D. 1992b. "GEOLINEUS: Data Management and Flowcharting for ARC/INFO", Technical Software Series S-92-2, National Center for Geographic Information and Analysis, Santa Barbara, CA.
Lanter, D.P. 1992c. "Propagating Updates by Identifying Data Dependencies in Spatial Analytic Applications", Proceedings of the Twelfth Annual Esri User Conference, Palm Springs, California.
Lanter, D.P. and Veregin, H. 1992. "A Research Paradigm for Error Propagation in Layer-Based GIS", Photogrammetric Engineering and Remote Sensing, Vol. 58, No.6. pp. 825-833.
Essinger, R. and Lanter, D.P. 1992. "User-Centered Software Design in GIS: Designing An Icon-Based Flowchart That Reveals The Structure of ARC/INFO Data Graphically", Proceedings of the Twelfth Annual Esri User Conference, Palm Springs, California.
Lanter, D.P. 1991a. "Design of a Lineage-Based Meta-Database for GIS", Cartography and Geographic Information Systems, Vol. 18 No. 4. pp. 255-261.
Lanter, D.P. 1991b. "GEOLINEUS: A Graphical User Interface for GIS", Proceedings of the Eleventh Annual Esri User Conference, Palm Springs, California.
Lanter, D.P. 1990. "Lineage in GIS: The Problem and a Solution", Technical publication 90-6. National Center for Geographic Information and Analysis, Santa Barbara, CA.