Executive Order 12906 in April, 1994, directed Federal agencies to participate in the development of the National Spatial Data Infrastructure (NSDI) -- a system to facilitate the discovery of and access to digital spatial information. To promote access to information in the NSDI, the National Geospatial Data Clearinghouse was created to coordinate spatial data services on the Internet. As of January 1995, Federal agencies with significant digital spatial data holdings were required to begin serving descriptive information for published data in a searchable form on-line. A number of Federal, State, and university participants have also provided links from descriptive data (metadata) to actual data sets so that they may be retrieved directly, without fee, from the Internet by the public. This is achieved through use of a consistent index and search strategy based on the Hyper-Text Transfer Protocol (HTTP) and Z39.50 Search and Retrieve protocols available in non-proprietary server and client software. This paper presents the architecture of a spatial data server and the current availability of digital spatial information from the Clearinghouse Internet.
Executive Order 12906 was signed by President Clinton on April 11, 1994 to help evolve the National Spatial Data Infrastructure (NSDI). Several objectives were defined to promote the population of the NSDI with geospatial data held by Federal agencies and other organizations. These include:
To further these capabilities, the Federal Geographic Data Committee (FGDC) Clearinghouse Working Group over the past year has been testing service scenarios, providing training, and sharing technology with member organizations and related groups. Through such experimentation it has been demonstrated that the Clearinghouse must be a distributed archive of information -- distributed among several nodes within an organization, but accessible to all potential users through a single point-of-entry, or gateway, managed by the FGDC. By placing the servers at the field or service center level of an organization, the information is likely to stay more current, require fewer system resources, and more closely reflect agency holdings than would the development of a single, centralized server of geospatial information. Therefore, the ability to search multiple data servers for data sets that are relevant in both location and content is a key requirement for the success of this distributed clearinghouse concept.
There has been a continuous advance in services available on the Internet to post information. Initially, anonymous file transfer protocol (ftp) provided a service that allowed knowledgeable users to log into and download files of interest from 'public' file directories. A proliferation of ftp sites led to the creation of an index called Archie at McGill University that contains all file names from all public ftp sites around the world. This is still a useful service if a specific file name is known, but it does not provide any content-based searching. Gopher was developed at the University of Minnesota to provide more verbose 'tags' for directory contents with up to ten words to describe the contents of a file or directory in its headline. An index to Gopher, called Veronica, has been developed to search all Gopher servers (Gopherspace) that permits search of these stores of information by wordy file handles.
In the early 1990's, two Internet services were developed in the public domain that have become widely used for information retrieval. The first of these was Wide-Area Information Server (WAIS) software, based on an American National Standards Institute (ANSI)-standard search and retrieve protocol that allows for the indexing and search of full-text documents or fields within structured text documents on the Internet. The second, and most recent, Internet information access tool is the World-Wide Web (WWW) and its browsers fashioned after the Mosaic product developed at the National Center for Supercomputing Applications in Champaign-Urbana, Illinois. The WWW and its primary communication protocol, Hyper-Text Transport Protocol (HTTP), allow for a simple connection between a client, such as Mosaic, and a server. By clicking on a string of highlighted text (hypertext), graphic, or icon, the client is presented with a new 'page' of information from the WWW. In this way the user can explore whatever links are interesting or relevant at the time, traversing many systems and even using other simple protocols such as Gopher and ftp.
With the proliferation of information on the Internet the ability to find specific information is becoming increasingly difficult. The WWW metaphor provides single-click access to specific files on the network, but provides no inherent search capability. To use a library analogy, the WWW allows one to browse the available files (like books) by walking along the shelves until something of interest is found, without the assistance of any kind of card catalog. As the number of libraries (or WWW sites) increases, and their organization varies significantly from site-to-site, one's ability to conduct an efficient search is greatly reduced. Some search services (e.g. Lycos, Web Crawler) have been developed to alleviate this problem, but their scope is very broad and provide no geographic search capabilities for entries in the index. The WAIS software, on the other hand, provides a search capability, but has no browse capability. The underlying protocol, Z39.50, allows multiple server connections to be handled by the client (or gateway process) so that one query can be passed to multiple servers at the same time. Given the complementary nature of WWW and Z39.50 services, and the requirement for both browse and search, it has become clear that to be considered a full NSDI Clearinghouse node, metadata and spatial data must be served using both Z39.50 and HTTP protocols.
The scope of the NSDI is to include all information that is geographically referenced. Being a vague directive, this clause is interpreted differently by each agency with respect to their data holdings that are published or can be made accessible to the public, are of sufficient quality, and can be documented as to content and quality. These data sets may include information that is indirectly referenced to the Earth's surface (e.g. census tables referenced by state and county codes but containing no coordinates) as well as the more tangible georeferenced coordinate and attribute data sets that can be readily loaded into a geographic information system (GIS). This paper will focus on the architecture of a spatial data server that operates within a GIS environment, with specific focus on the service of of ArcInfo data.
To serve spatial data to the Internet the information server must reside on a computer that is capable of handling multiple simultaneous requests for data through known TCP/IP ports. The UNIX and Windows-NT operating systems handle multiple users and queries concurrently. The faster the processor, and more critically, the input-output rate (I/O), the more capacity a given computer will have for service. Needless to say, this computer must also have an adequate connection to the Internet for the level of service to be offered. If it is serving only metadata and not spatial information, then this can probably be satisfied through use of a dedicated SLIP connection at 28,000 bps. If data sets are to be served, then an entry-level connection should be 56,000 to 64,000 bps with faster services for primary servers within an organization.
Clearinghouse data service does not require GIS software to be running on the server, but if the data are created and managed in a GIS it allows the data and metadata to be better synchronized. Those interested in serving metadata not otherwise managed in GIS can set up server processes that run on Intel-based PCs running the public domain Linux (UNIX clone) Operating System or other UNIX variant. In-house comparisons of computers at the U.S. Geological Survey show that an Intel 486/66 running Linux is comparable to a Sun Sparcstation 1 in performance for WWW and WAIS services. For large numbers of simultaneous queries, however, the Sun equipment manages multiple users better than the Intel-based server.
To support browse and search capability, as described above, the computer must be running a version of the WWW HTTP daemon that supports Hyper-Text Markup Language (HTML) 2.0 with forms support and a Z39.50 server process. At present the Clearinghouse has promoted the use of the public-domain freeWAIS-sf software from the University of Dortmund, Germany that supports fielded search of information. The Clearinghouse is in the process of converting its service to support Z39.50-1992 over the next few months and will be testing the freely-available Isite software for better interoperability with digital libraries and the Government Information Locator Service.
The first requirement of a spatial data server is that the data be documented. This documentation, known as metadata, can be achieved using the DOCUMENT program included with ArcInfo version 7.0.3, initially developed by the U.S. Geological Survey (USGS) and the U.S. Environmental Protection Agency. It was subsequently modified by Esri for platform independence and is also available from Esri for 7.0.2 users. This DOCUMENT program creates and uses four INFO files per data set (coverage, grid, or image):
A menu interface has been developed for DOCUMENT that allows input, update, display, printing, and deletion of a metadata entry. The report that is generated from DOCUMENT, with the FILE option, contains data elements and structures from the June 8, 1994 version of the FGDC Content Standards for Digital Geospatial Metadata. DOCUMENT is an initial attempt to make ArcInfo data use the consistent terminology of the metadata standard. A system-wide approach for metadata management within the ArcInfo software suite is anticipated in the next major release of the software, to support life-cycle metadata management for all on-line data.
For data sets to be served in a consistent manner from a site, it is desirable to store them in a location with consistent structure and access. The ArcInfo Librarian subsystem is available to all users as a common, local repository of coverages. The USGS has extended the principles of library management to include grids and images through the creation of a suite of Arc Macro Language (AML) programs for the USGS Distributed Spatial Data Library (DSDL)(Nebert, 1994). These programs include the Librarian modifications for grids and images, simplified administration tools, and support for posting selected library data to the Internet via WAIS. This service will be soon upgraded to support the latest version of the protocol (Z39.50-1992) and will support generation of HTML for the metadata entries for use in WWW servers. The ArcStorm software was investigated for use in this data service, but it is a separately-priced product and is not designed for wide-area network use. It was important that entry-level metadata management and service not require the purchase of additional software for participation in the Clearinghouse. In fact, the server and indexing programs provided through the Clearinghouse working group are designed to work independently of a given GIS. Implementation of the server capability within ArcInfo was based on internal requirements of the USGS Water Resources Division and is being shared with the general user community to minimize duplication of effort.
Once data are documented, the DSDL AMLs permit digital data sets to be inserted into the Library, checking to be sure documentation is present. If the library has multiple tiles, a representative tile is selected to "document" the layer and to be seen by queries, but tile- specific metadata is preserved for each tile-layer combination. The librarian data structures were modified as shown in figure 1 to include the documentation files with each layer template and a wais subdirectory to store the forms of information to be served by the WWW and WAIS servers. The population of the wais subdirectory is achieved through the use of the ARCWAIS AML program. The database administrator is allowed, through this menu interface, to create the various 'variants' of data shown in this list as the data are available for publication. The command allows for some layers to be accessible to local library users and for others to be posted for external service at the discretion of the database administrator. All other local layer access is controlled through the Librarian or DSDL access programs.
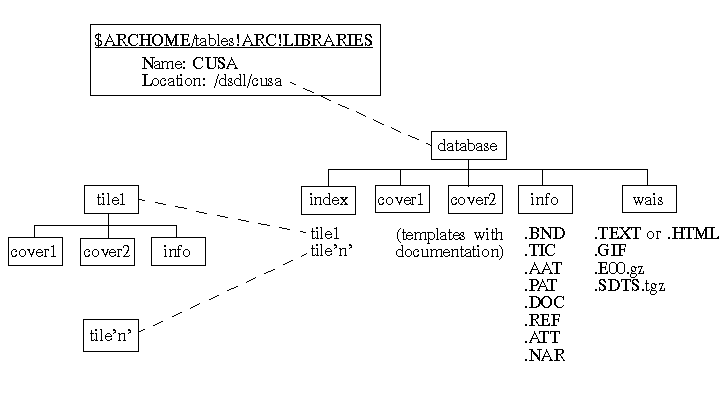
The wais subdirectory holds a series of files for each layer in the library. Although this duplicates the data stored online somewhat, the storage of compressed distribution formats -- Arc EXPORT and Spatial Data Transfer Standard (SDTS), as depicted here -- and metadata reports ensures rapid data delivery to a client as opposed to creating the export files or metadata reports on-the-fly. From the perspective of a GIS-independent Clearinghouse implementation, this model can be applied for many different collections of data.
Full integration of the Z39.50 search and retrieval capability within GIS software is a near-term goal for spatial data service to eliminate the current configuration where information is stored on-line in several forms, creating potential problems in synchronizing versions of data and using extra disk resources. As processor speed improves and data conversion algorithms are optimized, GIS vendors should be able to connect the Internet search directly to libraries of data and generate output data and metadata on request.
One of the objectives of the Clearinghouse effort is to make geographically referenced information accessible by several prominent Internet service protocols. As discussed previously in this paper, the Clearinghouse has been focusing on Z39.50 and HTTP as the primary service protocols that provide search and browse capabilities, respectively. To accommodate clients using the different protocols, two server processes are installed on the data host computer that are connected to the same indexed collection of data. A user requesting information through a WWW client accesses the WWW server and is given a search form to complete that includes text and spatial search information (figure 2). The form variables and their user-assigned values are passed to the WWW server, repackaged, and submitted to a Z39.50 server. The query to the Z39.50 server is formulated in such a way that it appears like another Z39.50 client and the request is processed, sending the results back to the WWW client. The results that are returned are usually in the form of a list of available documents that provide direct hypertext access to the metadata, browse graphics, and various on-line exchange formats of the data.
Access by a Z39.50 client is similar except that, unlike WWW, Z39.50 provides an interactive session analogous to a database connection with the remote server allowing for result sets to be built and re-used. A query from a Z39.50 client provides a list of documents that include links to the on-line "variants" of the data (e.g. browse graphics, export formats).
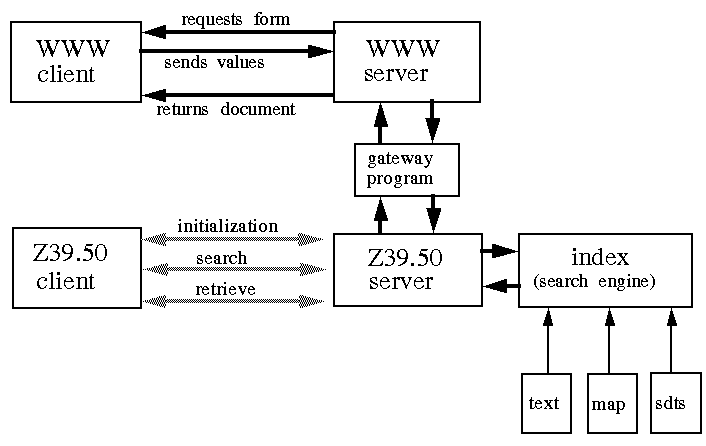 Figure 2. WWW and WAIS Client-Server Transactions on Spatial Data
Figure 2. WWW and WAIS Client-Server Transactions on Spatial Data
The U.S. Geological Survey has been the first agency within the scope of the FGDC Clearinghouse activity to demonstrate a distributed browseable and searchable clearinghouse of spatial data. Servers have been set up to index and serve a subset of metadata and on-line data from the EROS Data Center ftp site, water-related national data sets, and selected geologic data bases. A single query (e.g. search for the word "basin") can be passed to the three servers handling the information, and a single set of results is returned. So even though the information is distributed, it provides -- for the first time -- a single view of the agency geographic information resources, as shown in figure 3.
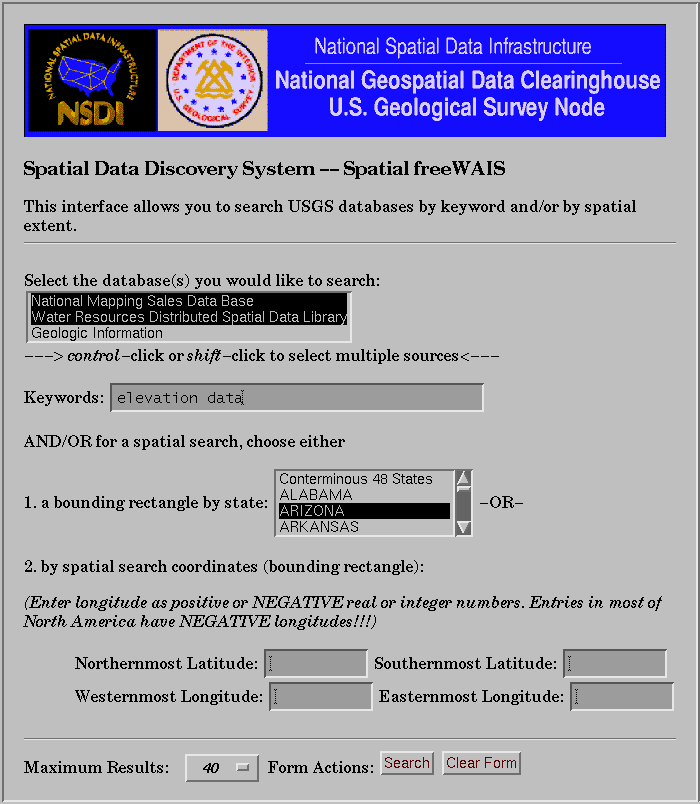
The FGDC Clearinghouse gateway is being established to provide a similar comprehensive view of the stores of information registered with FGDC by Federal and non-Federal agencies. Through a single query system, made accessible via WWW, a user can access one or more agency collections and enter search terms -- including geographic search -- to locate available metadata and, in most cases, link directly to the data for retrieval and immediate use in GIS.
The National Wetlands Inventory of the U.S. Fish and Wildlife Service has recently been placed on-line for access via ftp, WWW, and WAIS. Their on-line catalog has been indexed for text and spatial search via WAIS, but it is not yet connected to the data, also on-line, but in a different location.
The WWW and freeWAIS-sf system is also being used by the Johnson Space Center to spatially index and serve over 300,000 scanned photographs from Earth-observing missions (Marsh, 1995). A user can specify a bounding rectangle over a region on the earth and all scanned photographs whose nadir point falls within the search region are accessible for retrieval as images that can be viewed by most WWW browsersJPEG or GIF.
Through the complementary use of WWW and WAIS technology, an increasing number of agencies are able to index stores of spatially-indexed information for discovery and retrieval on the Internet. The World-Wide Web provides the universal user interface and WAIS provides a unique search capability that can be run across multiple servers simultaneously. The FGDC Clearinghouse seeks to provide a referral service for information servers that contain spatial information and support search of coordinates, primary text and numeric fields, and general free-text to enable a high level of interoperability.
Marsh, K., 1995. Digital Image Collection -- Earth Observation Collection, NASA Johnson Space Center.
Nebert, D. D., 1994. Design of the Distributed Spatial Data Library for the Water Resources Division, U.S. Geological Survey. U.S. Geological Survey Open-File Report 94-327, Reston, Virginia, 27 pages.