
Don Murray, Safe Software Inc.,
Dale Lutz, Safe Software Inc.
A Seamless GIS Solution
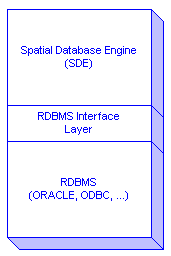
Traditionally, geographic data has been collected and organized around the mapsheet. While the mapsheet centric approach made sense when Geographic Information Systems (GIS) were used to automate the map-making process, this method of data organization is not well suited for inherently seamless applications such as decision support systems. Esri's recently announced Spatial Database Engine (SDE) claims to meet the needs of the next generation of geographic data users. This geographic database product provides a spatial extension to the underlying commercial Relational Database Management System (RDBMS), thereby enabling all data (spatial and non-spatial) to be stored within a single RDBMS.
A prototype system has been deployed using Esri's SDE. The prototype system evaluates Esri's SDE and is compared with an existing system which uses earlier GIS technology. This prototype exercises many features of Esri's SDE including programmatic feature type creation, data loading integrity checking, and transaction support. The prototype also makes heavy use of the SDE Application Programmer's Interface (API). In addition to an on-line data browsing and analysis facility, the system also incorporates a data export facility. This facility allows data to be selected using both spatial and non-spatial attributes, providing remote users of the system with the ability to extract data of interest for further processing and integration on their own desktop systems.
The data import and export facilities are table driven and can be customized for particular schema and/or geometric transformations. They currently support the Spatial Archive and Interchange Format (SAIF), Esri's Shape Files, Intergraph's Design Files (DGN), and MapInfo's MIF.
To evaluate the administration tools of the Spatial Database Engine an X-Windows based Spatial Database Administration tool was constructed. This GUI is used to test the ease with which users can perform index tuning and other administration operations on the Spatial Database Engine.
Introduction
Traditionally, geographic data has been collected and organized around the mapsheet;. While the mapsheet centric approach was appropriate for automating the map-making process, this method of data organization is becoming increasingly problematic as GIS moves into new domains.
Esri's recently announced Spatial Database Engine (SDE) claims to meet the needs of the next generation of geographic data users. This geographic database product provides a spatial extension to an underlying commercial Relational Database Management System (RDBMS), thereby enabling all data (spatial and non-spatial) to be stored within a single RDBMS.
A prototype system has been deployed using Esri's SDE. This system stores cadastral and topographic data in a single seamless database. The prototype system evaluates Esri's SDE and is compared with an existing system which uses earlier GIS technology. This prototype exercises many features of Esri's SDE including programmatic feature type creation, data loading, integrity checking, and transaction support. The prototype also makes heavy use of the SDE Application Programmer's Interface (API) by performing mapsheet generalization and mapsheet merging operations.
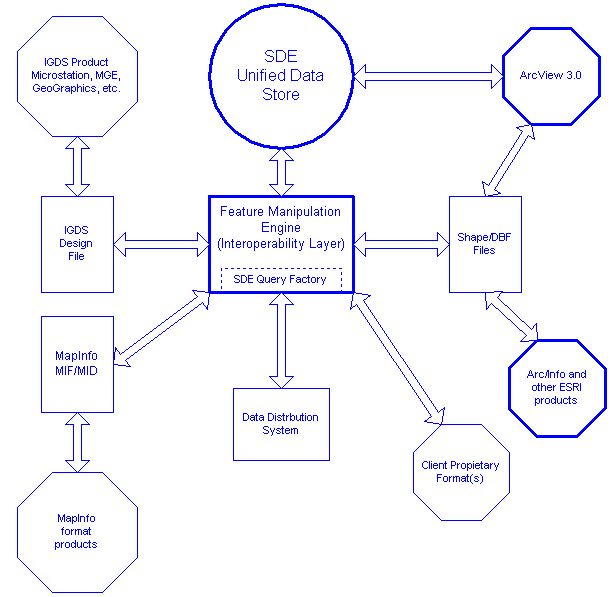
In addition to the Spatial Database Engine, the prototype also uses the Feature Manipulation Engine (FME) for providing interoperability with other GIS systems. This product enables data to be exported from the SDE to a variety of popular GIS formats. The Feature Manipulation Engine provides a table driven interoperability layer which can be customized for particular schemas and/or schema transformations. The prototype currently supports SAIF, Esri's Shape Files, Intergraph's DGN, and MapInfo's MIF.
To evaluate the administration tools of the Spatial Database Engine an X-Windows based Spatial Database Administration tool was constructed. This GUI is used to test the ease with which administrators can perform index tuning and other administration operations on the Spatial Database Engine.
The prototype system was developed to replace and extend an existing system built with a myriad of earlier GIS technology. While the existing system is adequate it is cumbersome and expensive to operate. The prototype was designed to provide the following capabilities.

| The prototype must be able to store a vast amount of data which covers a large geographic area. The area used to test the prototype is about the size of California, Oregon, Washington and Nevada combined. |
|
| The prototype must have a powerful query facility. In particular, the prototype must be able to process a large number and variety of queries in an automated fashion. wants to automate the query response as much as possible. |
|
| The prototype must be able to create derived products easily through a well defined API. The prototype system must be able to handle custom data requests which occur from time to time. The custom data requests are currently very problematic for the existing system. |
|
| The prototype must have a scalable architecture so that it can handle increasing numbers of users and increasing quantities of data. |
|
| The prototype must be able to output data in a variety of popular GIS formats. |
While the existing system meets many of the needs outlined above, it is a batch oriented system in which turnaround time is measured in hours at best and days at worst.
Data flows through the current system as follows:
While considerable effort has been made to automate the existing system it is an inherently expensive approach for distributing data. Manual interventaion must be used at several steps of each data request. Given the GIS tools which were available at the time of its development, however, it is difficult to come up with a better solution. The current solution also does not include the abilitiy to distribute the data in a variety of formats. The system distributes its data in a single format leaving the interoperability to other systems.
The prototype system consists of two key pieces of technology. The first component, the SDE, forms the foundation upon which the rest of the system is built. The second component, the FME, provides an interoperability layer on top of the SDE.
Using the SDE, made it possible to replace the entire existing system from the optical disks to the spatial and non-spatial processing of the data requests with a single software component!
Esri's Spatial Database Engine (SDE) brings GIS into the realm of MIS by providing an efficient and powerful spatial interface to industry standard RDBMS technology.
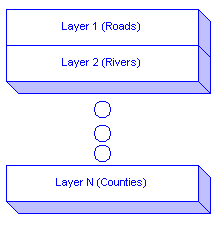
The SDE enables a Relational Database Management Systems (RDBMS) to store both spatial and non-spatial data.
The SDE provides a seamless geo-relational data model organized around feature types. Feature types are roughly equivalent to entities for those familiar with Entity-Relationship diagrams, classes for those familiar with Object Oriented concepts, or layers for those familiar with CAD or traditional GIS products.
Example feature types include Roads and Rivers. A single SDE database may consist of a large number of different feature types.
Each feature type has the following properties:
The SDE was chosen as the prototypes' data store for several reasons, including:
|
| Seamless data model: Data no longer needs to be broken down along mapsheet boundaries. This seamless approach enables spatial queries to be handled much more quickly than any map-based GIS product. |
|
| Heterogeneous client support: The SDE enables both UNIX (many varieties) and Win32 clients to communicate directly with the SDE Server. This makes the SDE an ideal solution for data providers who wish to support different types of clients from a single database. As SDE clients communicate with the SDE Server using the industry standard TCP/IP, it is reasonable to expect that more client platforms will be added in the future. |
|
| Scaleable architecture: The SDE can be installed on machines ranging from the very small to the very large. As the data repository of an organization grows or the number of clients accessing the database grows the SDE server can grow along with the data repository ensuring fast performance into the unforeseeable future. The SDE leverages off of mature RDBMS technology to provide a smooth migration path. This scaleability also lessens the cost and hence the risk of evaluating the SDE. The SDE can often be installed and evaluated without the need to purchase new hardware resources. |
|
| Unsurpassed spatial query performance: For large data stores, the performance of the SDE is currently unmatched. |
|
| Data management: The existing system was managed as a collection of files with procedures to ensure that multiple updates did not occur and no real security system in place. The SDE provides its own administration tools in addition to the Data Management of the underlying RDBMS. |
The Feature Manipulation Engine (FME) sits on top of the SDE and is responsible for providing semantic data interoperability between the prototype system and external systems. Coupling the FME with the SDE enables the prototype to freely and easily move data between the SDE and a variety of systems. The FME design enables new formats to be added without impacting the rest of the system.
Through the use of the SDE's powerful query facility the FME extracts data from the SDE and converts it to the user's desired format on the fly. From the user's standpoint the data appears to be stored in the prototype system as Esri Shape Files, IGDS Design files, or MapInfo MID/MIF, or any of the other formats supported by the FME.
The FME is also responsible for performing generalization on features stored within the prototype when a user requests data at a lower level of detail than that stored within the SDE. This capability makes it appear that the prototype system is storing the same data at many different levels of detail when in fact the data is only stored once.
When designing the data model a number of significant issues arose:
|
| Prototype source data is divided into several different and logically
unrelated data products. For example, the cadastral product consisted of
several layers that were logically different than the topographic product layers .
It was decided that layer ranges
within the SDE would be reserved for each of the different data products. As
the SDE has a virtually unlimited number of layers this was a simple
task.
We also noticed that there was a great deal of overlap between some of the data stored within the products. Ideally, the notion of data products would not be reflected at the database level. A data product is merely a standard combination of data extracted from the SDE. Unfortunately, this was beyond the scope of the prototype and the each of data products wereleft in tact. Data redundancy could be reduced by the rationalization of the data which is duplicated from data product to data product. |
|
| The prototype source data was initially stored in UTM coordinates. Due to the size of the test area the data intersects 3 different UTM zones. As the SDE stores data in a single cartesian plane, a cartesian coordinate system had to be decided on before the data loading could commence. After looking at many different planar projections it was decided to simply extend the middle UTM zone enough to completely cover the test data. Coordinate conversion was done prior to the data being loaded into the SDE. |
|
| The existing system currently enables clients to request data from some products which are at different scales. Storing the data at many different levels of detail was considered but was abandoned in favour of only storing the data at the highest level of detail. If a request comes for data at a lower level of detail then the interoperability layer generalizes the information as it is extracted from the SDE. This greatly reduced the amount of data that had to be stored within the database and also permits the prototype system to support any multiple levels of detail. |
|
| As the SDE is a seamless database an attempt was made to perform mapsheet merging on data which is stored within the SDE. The goal was to erradicate all remnants of mapsheet boundaries from all the data stored within the database. The prototype does have a mapsheet merge facility which automates much of this process. It is able to merge polygons and lines broken along mapsheet boundaries. However, our worst fears were realized when features which don't join at mapsheet boundaries (but should) were discovered. These will require manual intervention to join together. |
Once a preliminary data model had been decided upon the focus of the prototype activity changed to developing a method of storing the data within the SDE. The SDE performs a great deal of geometric integrity checking when data is being loaded. This integrity checking ensures that data which is loaded into the SDE is valid. During the prototype development it was discovered early that occasional input features have invalid or unsuspected geometry. This results in the SDE rejecting the feature and the FME aborting the data load operation. The data load operation then had to be restarted after all features which were successfully loaded during the data load operation were first removed from the database. This was not an ideal situation and was resolved as described below.
Initially, the data load process did not take advantage of the SDE's transaction model and thus when a data load operation was aborted it was difficult to recover in such away that no features were skipped and no features were loaded into the SDE twice. The prototype was then upgraded to take advantage of the SDE transaction model. This enables the prototype to recover from erroneous data in a graceful and controlled manner. The impact to the prototype system was surprisingly small and required only 2 days of effort. The prototype system now performs a transaction commit after every 100 features and prints the transaction number to an FME log file. If the data load operation is aborted because of bad data or other erroneous events the user simply corrects the problem(s)and reruns the data load operation with the last successful transaction specified. The FME ensures that the loading of features into the SDE begins at the correct point of the data load operation. No features are lost and none are duplicated.
A capability of the SDE which was found to be crucial to the prototype is the SDE's ability to create all database entities through its API. The prototype system exploits this capability by performing the following through the SDE's API.
Making the data loader module responsible for all aspects of layer creation and verification radically reduced the amount of time required to prepare a new SDE database for use.
The prototype uses FME control files to completely describe all the feature types stored within the SDE database. These control files control all interoperability aspects for the prototype system. Because they can be easily editted, changes to any import or export schema can be quickly and painlessly made by data analysts in the field, without requiring any modifications to software source code and recompilation.
The prototype system enables data to be exported either through the use of precanned queries or custom control files for those who have direct access. Custom queries not handled by the interoperability layer may also be developed using the SDE 's C API or other interfaces provided by Esri such as Avenue and MapObjects, though for the prototype this was not necessary.
The prototype incorporates a Data Distribution System (DDS) that users can directly interface with. The goal of this component was to allow users who are connected to the same network as the prototype (intranet or internet) to be able to perform adhoc queries on the database. The DDS module accepts the query and returns the requested data in the desired format. The prototype accomplishes this by using the FME's SDE QueryFactory module.
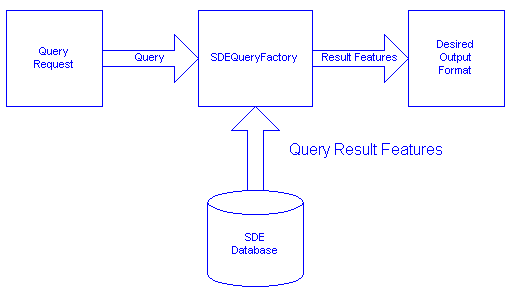
When interoperability layer of the prototype receives a query, it:
The Data Distribution module of the prototype is driven by simple ASCII files, making it simple for other software modules to communicate with the prototype system. In the prototype system there are two such software modules. A text-based front-end is used by the public and replaces an older batch ordering system. However, an interactive viewer enables users with a high speed direct link to interactively select the data to extract from the prototype system. It has been found that most custom data orders can be solved through the use of this interactive viewer without the need to develop any software.
The query facility present in the prototype system exploits the following SDE functionality:
|
| Search specifying both an arbitrary spatial component and an arbitrarily complex where clause. The spatial component includes the Search Method which is to be used when the search is performed. The where clause not touched by the query facility and is passed directly the the SDE for processing. |
|
| The maximum features to return may also be specified. |
|
| The SDE's corridor technology is also exploited. If the query specifies a buffer distance then the buffer distance is constructed by the SDE. The SDE is then instructed to use the buffered feature for the query. |
|
| The SDE's spatial filter capability is also used. This enables the spatial component of the search to use two features to filter data. |
The data distribution component of the prototype is one of the most interesting components of the prototype. It enables the prototype to answer a great number of queries very quickly.
The prototype system described here demonstrates a sophisticated spatial data processing environment constructed using the Spatial Database Engine. By using the SDE as its core, the prototype system is able to effectively manage, and more importantly make available to users, a vast amount of spatial and attribute information.
Typical queries which took hours or days to process with the old system were reduced to taking only seconds using the new SDE-based system. The prototype system also makes possible data manipulations and queries which were previously prohibitively expensive.
The SDE API was found to be rich and powerful, enabling obstacles encountered during development to be overcome in a timely fashion. The resulting system is both fast and robust.
The fact that the prototype was almost entirely constructed from commercial off the shelf products makes the results achieved even more encouraging.
|
| Author's Home Pages: Don Murray and Dale Lutz |
|
| Esri Home Page |
|
| Esri's Spatial Database Engine (SDE) |
|
| Feature Manipulation Engine (FME) Home Page |
|
| Safe Software Inc. Company Home Page |
|
| Spatial Archive and Interchange Format (SAIF) Home Page |
Don Murray or Dale Lutz
Safe Software Inc.
Suite 105 10720 - 138th Street
Surrey, BC
Canada
V3T 4K5
phone: (604) 583-2016
fax: (604) 930-8407
e-mail: dcm@safe.com or dal@safe.com