Heather Dolph, Clem Henriksen, Arun Rajarao
Producing the electronic 1996 Esri User Conference Proceedings
Abstract
The Product Marketing Group at Esri produced
the on-line versions of the 1996 Esri User Conference Proceedings. The Proceedings team
elected to extend the HTML-based Proceedings concept
to include all of the 190 papers in an alternative medium -- Portable Document Format (PDF). This paper outlines the
computer environment and tools used to create the CD-ROM and the WWW site Proceedings version, and describes
the production processing flow. This paper identifies and evaluates key technologies.
Project Objective
With six weeks to deadline, the Product Marketing Group agreed
to take on the task of producing the Compact Disk (CD-ROM) and World Wide Web (WWW) versions of the
1996 Esri User Conference Proceedings. The Proceedings consist of user-submitted
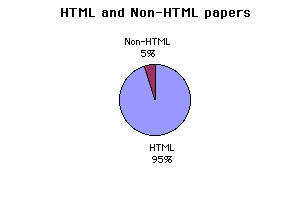
papers. Per instructions to authors, most papers are submitted in HTML format.
The design objective of the 1996 effort
was to support Hypertext Markup Language (HTML) as in years past,
and to explore the Adobe Acrobat Portable Document Format (PDF).
The HTML documents would be transformed into PDF documents. The
major advantage to PDF was availability of commercial software to provide ad hoc
keyword search of the proceedings directly from the CD-ROM. The disadvantage of adopting PDF was the inherent redundancy of
the PDF and HTML databases.
The project was to produce two outputs: a multi-platform
CD-ROM disk and an addition to the already-existing Esri World Wide
Web (WWW) Internet site. Both outputs would use the same content. The CD-ROM was the initial focus because it had an earlier deadline.
Establishing the Authoring Environment
Hardware:
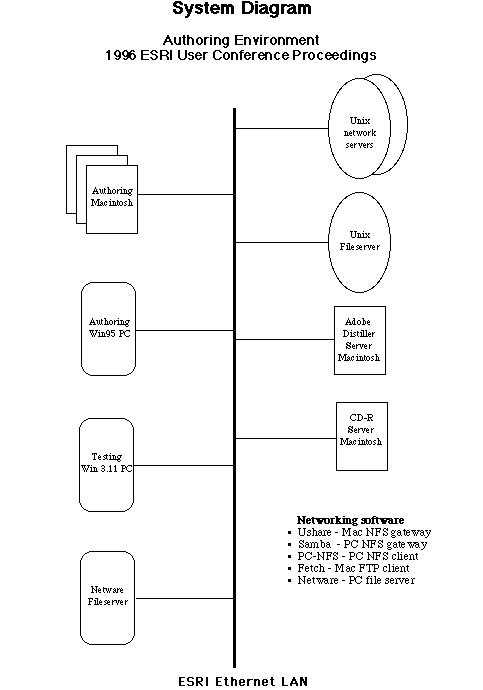
The team used the available hardware resources at Esri, including a mix of existing PC and Macintosh computers. We chose a UNIX fileserver for the bulk data storage because of the following features:
- Availability. Disk space was available on a UNIX machine. We used, at 'high water mark', over 500 megabytes of disk storage. Production space requirements greatly exceeded final deliverable requirements.
- Access. The UNIX files system was accessible from all authoring platforms. Macintosh and PC computers at Esri can share a UNIX file system, but otherwise do not have direct Mac-PC network connection.
Therefore we had the following hardware setup:
- UNIX workstations and file servers (Sun)
- 486 PCs (Windows 95, Windows 3.1)
- Macintoshes (IIci, Quadra, PowerPC)
The networked Esri computing environment provided options for processing. A task would be performed on a given machine based on convenience, access to software and personal preference. We depended heavily on the NFS and FTP standards as implemented in a number of system software products to support the project.
Production Software:
We used a number of software products to process the Proceedings, including:
- FileMaker Pro 2.1 (Mac): A database program used to track intake and production
- Quickmail (3.0 and above): (PC and Mac): For our PC and Mac e-mails
- Netscape Mail: For UNIX e-mail
- Netscape Navigator 2.0 (all 3 platforms): For viewing HTML files and creating PostScript output
- Microsoft Word (both 5.1 and 6.0.1) (PCs and Macs): To edit HTML files as text
- Internet Assistant for Microsoft Word (PC): For converting Word and other text files
to HTML format
- rtf2html converter (Mac): To convert Word documents to HTML
- Other word processors (Mac, PC, UNIX): For simple edits we used software such as TeachText, Notepad and vi.
- Acrobat Distiller 2.1 (PC, Mac): To convert postscript files to PDF
- Acrobat Exchange 2.1 (PC, Mac): To create bookmarks, links, thumbnails, and title information in the
PDF document
- Acrobat Catalog 2.1: To build index files for PDF files used by the Acrobat Reader Search plug-in
- Acrobat Search 2.1 for CD-ROMs: Acrobat Reader with text search plug-in. Licensed for one title, i.e. the 1966 Esri User Conference Proceedings on CD-ROM
- Graphic Converter 2.2.2 (Mac): To convert graphic files into GIF and perform simple edits such as cropping.
- xv (UNIX): To reduce size and convert graphic files into GIF files
- Young Minds (UNIX) and PinnacleMicro RCD-ROM (Mac): To premaster CD-ROM
- Pagespinner 1.1b2: Used to author this paper
- Microsoft Excel (4.0 and 5.0) (Mac): To create graphs referenced in this paper
- Microsoft SiteMill (1.0 ) (Mac): To check HTML hyperlinks for all HTML files in a directory tree
- Dr. HTML (Internet service): To check HTML hyperlinks for a single HTML file
All software was available at the start of the project, except Acrobat Search for CD-ROMs, which was acquired specifically for the project. Each member of the team had familiarity with HTML, PDF and the software cited above. However, we did discover that the project challenged our knowledge of the software tools, and provided us with ample opportunity to learn more about the software we used.
Certain steps in the production process were automated using UNIX scripts, which generally performed file-system-oriented tasks, including:
The Ushare Mac-to-UNIX NFS software supports the concept of the Macintosh resource fork on the UNIX file system as hidden files named '.rsrc'. Ushare would provide a .rsrc file in each directory it accessed. At later processing stages these .rsrc file (sometimes found upcased to .RSRC) had to be removed. We used a UNIX alias employing the 'find' command to do this:
alias rmrsrc2 'find . -type d \( -name .rsrc -o -name .RSRC \) -exec rm -rf {} \;'
Network Software:
In the heterogeneous network environment at Esri, we used a number of communication products to expedite our file operations. Network software products we used included:
- Ushare: A Mac NFS client and UNIX gateway implementation of NFS. Useful for sharing files across a network.
- Fetch: A versatile shareware FTP implementation for Mac to `get' and `put' files across a network.
- Novell Netware: PC software used to support a PC e-mail gateway. Also used as a PC file server to support access to applications.
- Samba: This was the PC NFS client, UNIX NFS gateway software used by the PC authoring computer
- PC-NFS: A PC NFS client used on a PC testing computer
We used native NFS implementations on other UNIX machines to access the project file system.
File system set up:
We set up our Intake and CD-ROM staging areas on a UNIX server, so that it could easily be accessed from all UNIX and PC platforms. The PCs could access the files using NFS software and the Macs could access the files using Ushare (NFS) or Fetch (FTP).
The system design was crucial, as it set the foundation for the processing and completion of the project. We drafted a detailed diagram of the anticipated workflow before papers started to arrive. We also installed software on the Mac and PC, and delegated tasks to our project members. The Esri Systems staff provided valuable help on the UNIX end; Dave Scheirer and Peter Moran of the Product Marketing group also assisted us greatly with HTML and PDF editing.
After this it was time for our authors to send in their papers!
Intake file system:
We had sent an 'author guidelines list' to all authors, which
included suggestions and an introduction to HTML. We requested that all the
papers be sent to us in HTML format; this request, however, was not met by all the authors, as shown in the statistics regarding paper intake.
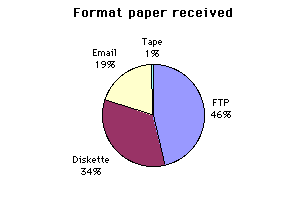
Papers came in to Esri via UNIX e-mail, PC e-mail, Mac e-mail, ftp, diskette, and one hard copy by fax. They were in several different formats: ZIP files, tar files, compressed files, UUENCODED, Wordfiles, WordPerfect files, ASCII text files and more. All papers, regardless of format, were copied to the intake area on our UNIX server. The FileMaker pro database was updated regularly to reflect the arrivals, changes etc. We received a significant number of papers during the last two days before the
deadline.
Once entered to the intake directory, user files were not changed. The submissions were preserved exactly as the authors had provided them, so we had a reference file if a question turned up during processing. We were careful to track the intake process in the FileMaker database, which functioned as a central status repository.
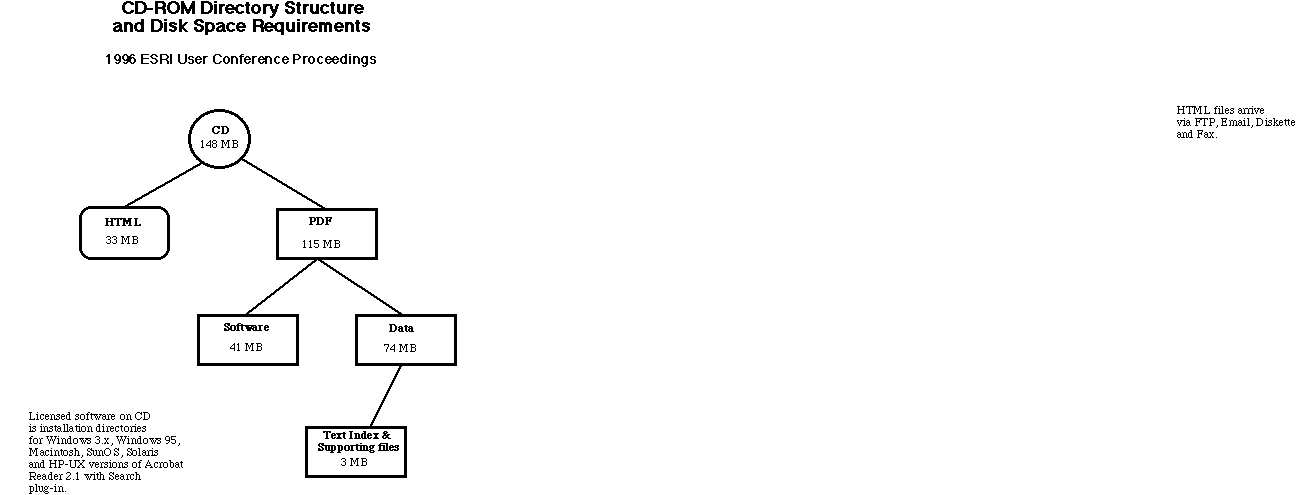
CD-ROM Staging file system:
This area of the UNIX file system was the file system as we wanted it to appear on the CD-ROM and the WWW site; when the processing was complete, we would have the exact disk image that we needed on the CD-ROM, making the pre-mastering a simple file transfer operation. The directory structure was designed to collect each paper in its own directory. Likewise, the directory structure segregated the HTML files from the PDF files, so that the HTML and PDF processing streams could proceed independently.
Intake
To track concurrent process of the HTML and PDF production, a new layout was added to the FileMaker Pro database, titled "CD-ROM Checklist." This layout contained the following fields: Paper Number; Format of Paper; Date Paper Received; All Permissions Received; HTML Complete; and PDF Complete.
HTML and PDF processing of each paper started when all permissions were received for that paper. An updated version of this layout was printed nightly to reflect daily process; daily assignments were then made in longhand on this copy.
HTML
HTML processing started by copying a paper directory from the intake area to the CD-ROM staging area, so all processing was performed on copies of submitted files.
The HTML documents submitted reflected a wide variety of HTML experience -- from very basic to very sophisticated formatting. One of the more common problems was with "pre-formatting" tags; many of the documents that employed these tags showed text that "ran off" to the right side of the screen when viewed through the browser. This was corrected by adding more specific HTML formatting to those sections of the documents. In some documents, large GIFs did not appear; this was resolved by changing the border to equal "0" so that the GIFs were not constrained.
In addition to noting document completion, comments were included in the "HTML Complete" field to indicate possible problems in the conversion of documents to PDF. These comments proved very useful in categorizing papers for PDF processing. For example, some authoring variations and large GIFs, while being suitable for HTML, turned out differently when converted to PDF. These differences included GIFs split between two or more pages, and loss of text -- from a few words to entire paragraphs.
For so-called "problem documents," documents and GIFs in the individual HTML files were copied from the UNIX server for the conversion process, so that the original/posted HTMLs would not be changed.
Since the 1996 Proceedings present HTML 'as submitted,' very little editing was done to the HTML files. Even so, there were some edits. If a <TITLE> tag did not have the actual title of the paper, the title was added. The TITLE tag is used to support keyword search of HTML on the Esri WWW site. User submitted files were edited to conform to the ISO 9660 conventions--this was required in order to create a CD-ROM file system that could reliably be accessed from Macintosh, Windows and UNIX computers. In some cases this required systematic edits to HTML files to modify file name references in the body of the text.
Each paper was reviewed for linkage accuracy. Only files directly used by the paper were left in the CD-ROM Staging directory (e.g., .zip and .tar files were deleted).
The team contacted authors for clarification where needed.
HTML Indexing
We built indexes for accessing the HTML database by Title, Author, Track (Subject), and Abstract. This procedure was semi-automated and database-driven. When the submittal deadline passed, we took a snapshot of the FileMaker database. We created an output export file from the database for each index; each of these files had the same data, but sorted in the order required by each index. We then manipulated each file in Microsoft Word, using Word's Mail Merge feature. This enabled us to add HTML tags automatically and uniformly to each output index. We finished up the indexing with hand editing and lots of quality assurance testing.
The Abstract index for the CD-ROM uses different formatting than the Abstract index on the WWW site. The WWW approach used multiple files that was more appropriate for that medium. The CD-ROM Abstract index used one large file, which was acceptable on CD-ROM and allowed keyword search of a single HTML -- a feature offered by many HTML browsers.
Conversion to PDF
The conversion of documents from HTML to PDF involved three main steps:
- Generating a PostScript file
- Converting PostScript to PDF via Acrobat Distiller
- Using Acrobat Exchange to create a finished PDF file
Generating a PostScript file
The first step of the process was done in one of two ways: printing a Postscript file directly from Netscape, and manually converting a text file.
Printing PostScript ("Print to File") directly from Netscape
This is the area in which the "problem documents" showed text loss and/or divided GIFs, which would happen when the GIF appeared in either the middle or the end of the page. (This problem did not occur when the GIFs came at the beginning of the page.) In many instances, this problem could be fixed by either;
- Reducing the GIF size with GraphicConverter (maintaining ascpect ratio, with a width of between 500-600 pixels), or;
- Reducing the print size of the document or by changing the paper size from letter size (8.5 in. x 11 in.) to legal size (8.5 in. x 14 in.) or larger, or both.
The different printer options offered by Netscape on Macintosh and Windows became evident at this stage in the process. On the Mac, the print size could be reduced by percentage; however, the two largest paper sizes offered were legal or letter. It also had the option of enlarging the print area (which was utilized), but limited the number of downloadable fonts. The Mac could not show a print preview, like Windows; the Windows version also offered larger paper sizes (up to 11 in. x 17 in.)
The Windows print preview capability was helpful in determining any setup changes before printing. The Mac documents, however, would have to be thoroughly checked after the conversion to PDF and, if text was lost, re-done using different print options. Several documents had to be re-done several times; many of these still did not print correctly, and had to be converted manually.
Manually converting a text file
This method offered a higher rate of success with "problem documents." We saved a text file from the Netscape display, then opened the text file in Microsoft Word. Changes were then made to match the HTML version, including font size, bolding, italics and underline. Tables had to be re-created by hand, as the conversion to text did not retain the HTML tabling format.
The text version saved from Netscape did not take full advantage of the horizontal margins. This was fixed by using Word's "Replace" function, in which the paragraph mark - listed under special symbols - was replaced by a space within paragraphs. This function was used on a paragraph-by-paragraph basis. In addition to any size reduction, GIFs were converted to EPSF (Encapsulated Post Script Format) in GraphicConverter. The EPSF images were then inserted into the documents, and the full document was converted to PostScript.
Note on image conversion: GraphicConverter was set to use the default resolutions. Ultimately, the quality of reduced GIFs was largely dependent on the quality of the original GIF.
Converting PostScript to PDF via Acrobat Distiller
The PostScript files were then saved to an Acrobat Distiller "In" folder (on either the PowerMac or the PC). When a PostScript file appeared in "In," Acrobat Distiller (already executing) would automatically convert it to a PDF and place it to the "Out" folder. The Distiller was set up to generate thumbnail images automatically, and to delete the PostScript file when the PDF conversion was finished.
Using Acrobat Exchange to create a finished PDF file
When Distiller converted the PostScript file correctly (as it did on first attempt for a large percentage of the papers), further processing in PDF format was performed. The pages were rotated, if necessary (so that it could be read horizontally). Bookmarks were added to create an "outline" of the document that would facilitate quick navigation of the paper without scrolling. Inter-paper links and Weblinks were also added via the Add Link command. These were created by dragging the tool to a rectangle shape over selected text or graphic, then specifying a "go to view" or a Universal Resource Location (URL). Since text links were already underlined, the PDF links were specified as invisible. Blue border links were used for graphics, as in Netscape. Pages with graphics only were trimmed (under Pages: Crop), then thumbnails for these pages were re-generated, as the old ones were disabled automatically during the trimming process.
The title and author names were then added under General Document Info, and the finished PDF placed in the appropriate storage folder.
PDF Indexing
The papers were then indexed using Acrobat Catalog. 'A,' 'a,' 'An,' 'an,' 'The,' and 'the,' were all designated stop words (by which Reader would not search); all other search options were supported. We indexed the PDF database using Catalog with a local copy of all PDFs on the PowerMac server. The final collection of PDFs and the corresponding index files were then transferred to the UNIX server shortly after completion.
General PDF note: the Mac automatic naming process for PDF noted all PDFs in lower case. Since this was a potential recognition problem in ISO 9660 naming conventions, all PDF documents -- including the top level Index folders and documents -- had to be converted to upper case. This was done in one of two ways: manually on the Mac for individual documents, and automatically by a UNIX script for groups of documents.
HTML and PDF - Closing Observations
As we look forward to the 1997 Proceedings, some basic needs come to mind when preparing HTML and PDF documents.
- Authors need to review their HTML documents thoroughly before sending. This is especially important with "pre-formatting" tags and links (both those within the document and to outside URLs).
- Guidelines for maximum GIF size requirements need to be set, so that the width of GIFs does not exceed 550 to 600 pixels. This will help download the HTML document faster and, if PDF is included next year, print it to PostScript with fewer problems. Authors also need to review all GIFs in their documents before sending, as some GIFs (of all sizes) were not of optimum quality.
- If PDF is included in future Proceedings, a better means of printing HTMLs to PostScript needs to be utilized. Preparations for next year's proceedings should include the exploration of printing options from browsers other than Netscape 2.0. Printing from a future version of Netscape will also be an option if the advantages of Windows and Mac versions are reconciled or consolidated. As HTML documents do not have page breaks, whereas PDF documents do, the problems that were encountered during the conversion process can be traced to the inherent differences in these two approaches to text management.
- The importance of testing by the production team cannot be overemphasized. Adhering to standard processing procedures avoided many potential errors, and follow-up quality assurance testing of outputs uncovered many problems that were missed during the initial processing. It is important to apply tests at each step of the processing flow, and to back up these processing steps so that problems are resolved at their source.
WWW Processing
The process of creating the CD-ROM was the main part of the project, but we were not yet finished. In order to complete the WWW part of the project, we had to finish these tasks:
- Add papers that arrived after the deadline, but were otherwise acceptable. Modify indexes to match.
- Create linkages to, and integrate with the greater Esri Web site.
- Update the Abstracts HTML index to the multi-file format.
- Disable the PDF text search capability (for which we were not licensed to use on the Web) and substitute the HTML text search capability (for which we were licensed to use on the Web).
- Install and test.
The Web work was performed with the same techniques as the CD-ROM.
Technology Assessment
The team successfully delivered the CD-ROM and WWW products that we originally agreed to provide. The technical environment was very supportive. A majority of the software tools for supporting projects like this one are readily available and relatively inexpensive, with some of the software available as shareware. The project pointed out the need for ample working disk space which is several times larger than the final deliverable file size requirements. By having the room to leave older copies of data on line, we were able to trace and fix problems without having to re-create the data from 'scratch'.
The project encountered two areas of technical difficulty:
- Problems created by NFS implementations. Because the team had access to NFS capability, it was able to use data in place rather than copying it to authoring machines. Although this capability saved a lot of time, unfortunately it introduced a certain amount of confusion.
The Ushare software builds 'caches', which are its own map of the UNIX file system. It is possible to modify the file system independently of Ushare, which obsoletes the Ushare cache. Consequently, Ushare sometimes presented an inaccurate picture of the UNIX file system. Another problem discovered mid-project was that Ushare allows automatic conversion of text file line terminators between UNIX and Macintosh. This capability created problems for the DOS files we put on the system that did not want to be translated. Once we discovered the problem and changed the Ushare setting to not change line terminators, the problem was resolved.
On the Win95 authoring machine, Windows 95 or the Samba NFS gateway used by the PC performed interpretation of file names according to its own rules - specifically, it did not display upper/lower case for file names as they actually were on the UNIX file system. Since much effort went into making the file names conform to the ISO 9660 standard, this interpretation was counter productive.
Ultimately, the most reliable way to deal with the file system was with native UNIX. Whenever we developed a question about a file-system issue, we would fall back on a UNIX command line interface to make our queries.
- Uneven CD-R technologies.We used Esri's two CD-R (CD-ROM-Recordable) technologies to pre-master our CD-ROM, and discovered that neither was adequate to create a multi-platform CD-ROM that was usable on Macintosh, PC and UNIX . We asked our CD-ROM duplication vendor to provide pre-mastering services. The vendor created a true multi-platform pre-master, using data sent to them on CD-ROMS pre-mastered at Esri. The CD-R systems available at Esri are adequate for backups and any two but not all three operating systems. Esri is currently investigating CD-R subsystems capable of pre-mastering multi-platform multimedia titles.
Conclusions
The 1996 Esri User Conference Proceedings required significant resources in data publishing, system expertise, hardware, software, perseverance and time. Those who undertake similar projects in the future should approach them knowing the process demands a considerable amount of effort and "hands-on" education. The existing computer industry technology supports projects of this type well.
The authors would like to thank some of the many people who contributed to this project:
the entire Esri Product Marketing team, Patti Helm, Judy Clarke, Barry Zickuhr, Enrique Yaptenco, Brian Berry, Jim Hoag, Jim Henderson, Karen Rossi, Linda Hecht, and many others.
Copyright 1996 Environmental Systems Research Institute. Mention of products does not constitute endorsement by Esri.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}