
Paper Topic: ArcView Applications, Data Automation and Processing, Customizing with Avenue, GPS and Ground Control
Abstract:
Recent improvements in technology have allowed the natural resource scientist to collect spatially explicit field data with vastly improved efficiency. Current field collection techniques often involve a paper trail of data where the conversion to usable electronic format can be extended for months. This time gap from collection to conversion costs both in terms of technician hours and data entry error. An application has been developed to facilitate real time electronic data collection that is spatially pinpointed using a Global Positioning System receiver in combination with the ArcView 2.1 GIS software package. Scripts were written in the Avenue programming language to pan and zoom GIS coverages to a point obtained from a GPS receiver. Further scripts allow the user to enter points, lines, or polygons and attribute them in real time with full error checking. This application as utilized for the collection of sample plots for satellite image classification produced an increase in efficiency and vastly improved data fidelity.
Introduction:
Data entry may be the most commonly abhorrent part of natural resource work. The paper trail from the field to the computer can be daunting along with the time spent accumulating and processing it. This arduous process need not be so long and dreary however. With the miniaturization of equipment and the increased functionality of PC-based GIS software systems such as ArcView, the researcher can take his office into the field and complete his field collection in one step. This paper describes a suite of Avenue scripts that speed field data collection and entry.
To adequately assess the challenges of data collection for land cover classification a crash course in field techniques was taken from a colleague who works on a large land cover mapping project. This methodology has been utilized for over five years in concurrent projects. The researcher travels into the field by truck and drives around until a homogeneous patch of land cover large enough to be discernible by Landsat TM imagery is found. (Locations also may be selected a priori based on a preclassified image.) Once an acceptable location is found, the researcher records on paper the approximate polygon size (in pixels), the UTM location, the cover type, the percent coverage of tree, shrub, etc., topographical measurements (elevation, slope, aspect), a picture reference, and surrounding landmarks or cover types for reference. Training sites are thus recorded daily throughout the field season with total sites numbering in the thousands.
At the end of the field season, the researchers begin the data entry. Each paper record is taken one at a time and entered into the computer. To enter a record, the researcher displays a TM image using the Imagine software package, locates the UTM location written on the paper, and attempts to recall the location and digitize the polygon that was envisioned in the field.
The obvious problem with this method is that the viewing of the cover type and the digitizing of the cover type may be months apart. Certainly this site cannot be recalled after visits to hundreds of other sites. If the site is surrounded by distinct features which were well identified in the field, the time delay may not be overly problematic. However, when this is not the case, mislabeling errors can arise. A more significant challenge remains in error checking. Since eye to hand to paper recording is fairly imprecise, several recording errors can occur. The most insidious error is a mistake in the recording of the UTM location. There are two chances for a mistake. The coordinate can be either misrecorded on the paper or it can be mistyped into the computer. Either case can result in a bogus polygon as this error is virtually undetectable over a broad area. Other errors are less detrimental, however, unless they are caught in the field they will never be corrected. These errors include missing data and invalid entries. All of these errors can be caught and corrected if the collection and entry of the data occur in the field.
Locate UTM Coordinate:
Upon completion of the crash course, it was recognized that improvements to this process were needed. To this end, two avenue scripts were developed which allow complete in situ data collection and entry. Data was collected using a military field data assault vehicle, GPS, and Laptop (Pentium 75Mhz, 16Mb RAM) with ArcView 2.1 loaded.
Upon arriving at a location, the first script, "Locate UTM Coordinate", is initiated. To run the script, the user simply reads a UTM coordinate from a GPS and enters it into a message box. The view then zooms to a scale of 1:10,000, pans to the location, and places a red dot at the coordinate.
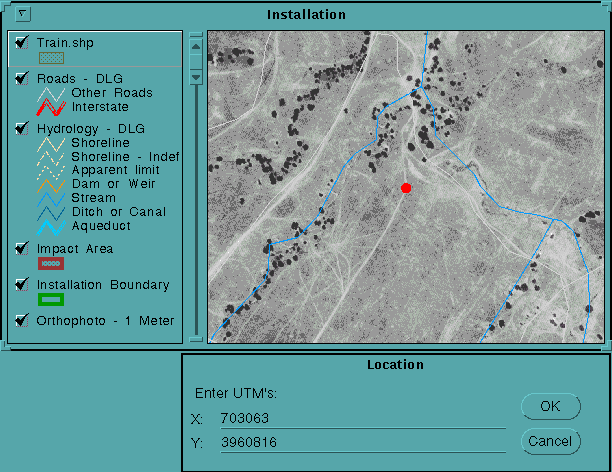
Due to selective availability, the location will be off by 50 to 100 meters, (Hurn 1993). However, with an orthophoto, SPOT, or TM image as a backdrop, the actual location can be readily identified through distinguishing features in the landscape. If the actual location cannot be discerned, the user may have entered an incorrect coordinate (in which case it is reentered) or he may choose to move on to another location. A significant number of misentries (perhaps greater than 5%) were found in testing, which increases the suspicion of mismapping under the former process. Once the correct location is identified, a polygon is drawn around the homogenous land cover unit using a preformatted shape coverage with fields named according to the next script, "Enter Field Data".
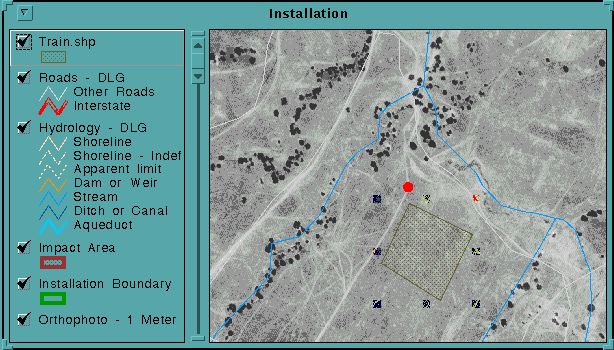
Enter Field Data:
The "Enter Field Data" script allows the user to attribute the newly drawn polygon. The script pops up a "MultiInput" message box that contains one entry for each field in the attribute table.
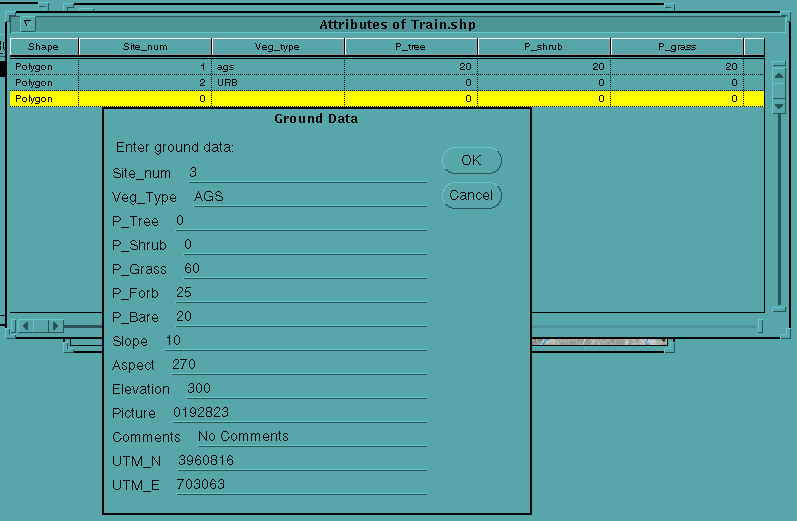
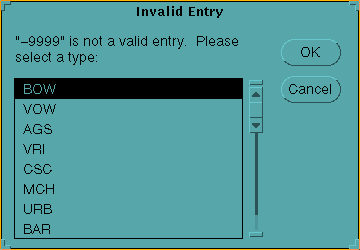
Some default values are automatically generated. For example, the "Site_num" field defaults to the next available record number. This prohibits the user from duplicating any polygon ids. Other fields have a set of possible valid entries, or must fall within certain parameters. If the "Veg_type" entry is not contained within a given list of valids (set within the script), a list is provided for the user to choose from.
Or, if the percent cover fields do not sum to 100, the values must be reentered.

In this manner, entries are checked for errors while the researcher is still at the site for observation. These scripts allow the user to visit, digitize, and attribute about five to six sites per hour. For comparison, the previous method yields approximately three to four sites per hour. Incidently, both methods require a nearly equivalent amount of field time, however the paper method requires extra time in the lab to enter the field data.
Set Random Polygons:
Typically the next step for classification of satellite imagery purposes is to withhold a certain percentage of training polygons for future accuracy assessment of the classification model. A common way researchers accomplish this is to extract site ids and cover types, run them through a statistical package, and link the results back to the original coverage. A third script, "Set Random Polygons", now allows the user to select the shape file, choose a stratification field (i.e., Veg_type), and set a percentage. The script then randomly selects the specified percentage of polygons (per cover type) and adds a field called "Validate" with a boolean "True" value if the polygon is to be withheld. These polygons may then be selected and saved out as another shape file. (A shape2arc.aml program allows the shape polygon coverage to be converted to an ArcInfo polygon coverage. Currently ArcInfo's shape2arc command will only convert a polygon shape coverage into an ArcInfo region coverage.)
Assess Accuracy:
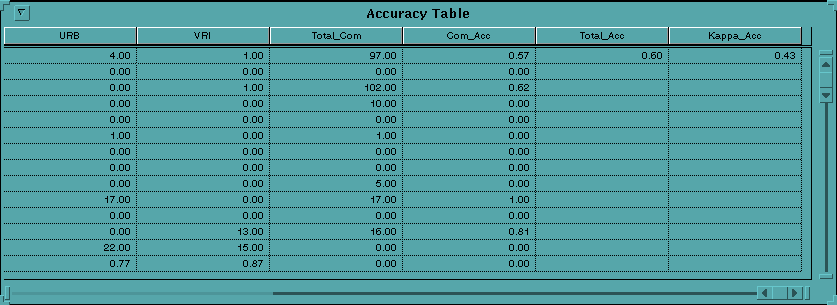
When a final classification is completed, it needs to be assessed for its accuracy. The user may now utilize the final script, "Accuracy Assessment". The accuracy script requires a coverage and field to be assessed, and a coverage and field with which to assess the accuracy. If the "Set Random Polygons" script was used, the reserved polygons would become the latter coverage. The accuracy script generates an error matrix, per class accuracies (omission and commission), overall accuracy, and Kappa accuracy. The output is recorded in a Dbf table. A polygon is considered correctly classified if its center falls within the same class as itself is defined.
Conclusion:
To assist researchers in the collection, entry, and processing of field data, four Avenue scripts have been written. The "Locate UTM Coordinate" script pans and zooms to a location to allow the researcher to identify and digitize a homologous polygon. The "Enter Field Data" script provides for real-time attributing and error checking. The "Set Random Polygons" script lets the user withhold a chosen percentage of polygons for error checking, and the "Assess Accuracy" script is a one step error matrix generator. These scripts improve both the speed and fidelity of data collection and entry.
References:
Hurn, Jeff. 1993. Differential GPS Explained. Trimble Navigation Limited. Sunnyvale, CA.
Author Information:
Brian Biggs
Allan Falconer
Department of Geography
Utah State University
Logan, UT 84322-5240
Tel: (801)797-1790
Fax: (801)797-4048
Email: biggs@nr.usu.edu or als@nr.usu.edu