Mark Harley
There are many decisions to make when purchasing a home in a new area. Organizing real estate data spatially allows a broker to provide detailed and comparative information about potential homes and neighborhoods. Constructing a seamless, nationwide, geographic database with hundreds of millions of records presents a unique challenge and requires powerful GIS tools.
An SDE(tm) database was designed jointly by Esri, GDT and the Realtor's Information Network (RIN) partners. GDT integrated data from numerous sources and built the SDE dataset. Esri developed an extensive client/server software system to retrieve data, display maps, generate reports and log transactions.
RIN needed a spatial database covering the entire United States including a base map and census/postal geography with attached demographics and regional information. Also required was data on homes including each address, current telephone listing, property features, assessment, and any home sales, foreclosures, nearby schools and hazardous materials sites. SDE was selected as the repository for this information. This data was integrated from multiple vendors and much of it required a "spatial enabling" step before it could be displayed on a map. This was accomplished through geocoding and by attaching fields as attributes to existing polygonal regions. The system was designed to be updated often, due to frequent changes in the information. With an overall size in the hundreds of gigabytes, a partitioning scheme was developed to keep individual pieces manageable, and yet appear seamless to the end user.
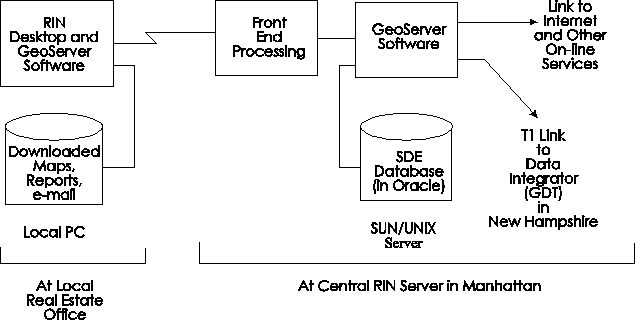
The central repository was built in SDE with the server applications running in a Sun / UNIX environment. The client software was prototyped in ArcView(r), with a final implementation using MapObjects(tm). A wide-area network was established between the data integrator and central server using a T1 line to allow for continuous, high-bandwidth updates. This paper discusses the challenges and corresponding solutions found for building and maintaining such a large SDE dataset.
The Realtors Information Network (RIN) was formed to provide real estate offices with new computer-based selling tools. Their plan was to use technology to assemble and distribute data to Realtors to enable them to more quickly and effectively match buyers with homes offered for sale. This data was not to be a static release of information sold on a CD/ROM and installed on each local computer; instead, RIN would collect data from many sources and build it into a central real estate database. Then, any Realtor with a PC who chose to connect with the RIN network would have access by paying a small transaction fee for each use. RIN would continually update the central database with the most current information possible, making it immediately available to all users.
To bring real estate agents up to date with technology, the RIN system would provide a basic desktop environment for everyone. There was e-mail for each user, access to "chat" rooms and a library of real estate related documents available on-line. RIN news contained a compilation of relevant articles from all over the country, updated daily. There was also access to a RIN on-line shopping "mall," a look-up module to find names of brokers and agencies nationwide, and Internet access via the Netscape Navigator.
One additional module, called "Geodata," was built to interact with a large geographic database. The construction of this SDE database is the primary focus of this paper. Geodata provided maps and allowed agents to define market areas near properties of interest. Then they could query the system for reports on community profiles, crime statistics, detailed school data, assessor reports, recent home sales and foreclosures. There was information on hazardous materials and a geocoded national telephone directory. Knowing the physical location of each item was critical to answer, for example, "how far from this house is the nearest school and what is it like?," "are there any significant hazardous waste sites nearby?," or "in this market area, what are the average real estate taxes on similar-sized houses?"
It was not sufficient to use a standard relational database to store this information. Because much of the data needed to be shown on a map, or accessed through spatial queries, it was stored in an SDE database, constructed on top of an Oracle relational database.
SDE stands for Spatial Database Engine (tm). SDE is an Esri product that allows spatial data -- points, lines, polygons and their associated attributes -- to be stored in a standard relational database. It is particularly well-suited for use in medium to very large-sized systems where data is shared by many users or contains large numbers of features. (Note that "large" in this context means hundreds of thousands to hundreds of millions of geographic features per SDE layer.)
SDE is not an end-user product in and of itself. It provides a data repository which is accessed using standard Esri/GIS software such as ArcInfo(r), ArcView or MapObjects. An SDE interface, including a suite of powerful spatial relation functions is also available to programmers from C/C++ or ArcView's Avenue(tm) language. As of this writing, SDE has been released for Oracle and Informix, with most other major relational databases to be supported soon.
The RIN system was built around a central SUN server, running Oracle, with an SDE database. Realtors connected using a modem and downloaded reports as graphics files, or maps as shape files, and accessed their e-mail and other desktop functions. Esri implemented GeoData on the RIN desktop, first using ArcView and later with MapObjects as it became available. Esri also developed the custom GeoServer software which ran on the SUN server interfacing with SDE, managing all of the requests and servicing the entire community of active users in real time.
There were numerous problems to overcome in building a database to support the RIN/Geodata system. Sheer size was the first obstacle. Geodata required a huge, central, spatial database on the order of hundreds of gigabytes, accessed by many users simultaneously, with fast query and retrieval times. It had to present a seamless coverage of the entire United States, including substantial data on every possible piece of real estate. It also had to be possible to update the system on-the-fly, without interrupting active use, due to the frequent changes in the data.
Esri's SDE product was selected to store and serve the data. SDE has the ability to handle large datasets, perform spatial queries and scale up to support large numbers of users. SDE is also directly usable with other powerful GIS software from Esri (notably, ArcView and MapObjects). It stores features "non-topologically,s" making on-line updates possible, so it was a logical choice.
Because SDE is built on top of a standard relational database, it is not possible to deliver "off-the-shelf data in SDE format." The geographic features must be loaded by SDE into the underlying RDBMS tables, which are in a proprietary, internal SDE format. At the time the RIN system was developed, there was only one tool supplied by Esri to convert outside data to SDE format: "shp2sde." This program is "shape-to-SDE," which takes a standard Esri shape file as input and loads the data into an SDE layer. Data can also be loaded into SDE by writing a computer program and calling functions in the SDE/API (Application Programming Interface.) It was found that writing a C/C++ program and using the API was faster and more flexible than using "shp2sde," particularly since much of the input data was not readily available in shape file format. A series of SDE loading programs were therefore written, one for each of the RIN layers.
The RIN database was built on a large Sun/Unix server that was physically located in downtown Manhattan. The company performing the data loading was in Lebanon, New Hampshire. With a large amount of initial data to install, and a continuous stream of updates planned, a wide-area network (WAN) was established between the two sites. A 'T1' connection was selected because the continuous, dedicated 1.5 million bits per second throughput matched the needs of RIN's particular update strategy. In a different situation, ISDN, frame-relay or a fractional T1 might prove sufficient, for a somewhat lower cost. If a higher data rate is required, it might be necessary to use multiple T1s or a T3 connection.
To load the data physically onto the RIN server in Manhattan, the data loading program for a particular layer was installed on the server machine. Then, the input data was copied over the T1 connection to a "staging area," which consisted of two nine-gigabyte disk drives. Next a script was created and executed to load a stream of data into the appropriate SDE layer.
A nice feature of SDE is that it is a full multi-user system supporting concurrent access. As the data was loading, it was immediately available to any other users on the system.
Another challenge in building the database was the number of companies supplying information. RIN selected around a dozen different vendors, all specialists in their own areas. Much of the data was tabular, but non-spatial. It was necessary to "spatially-enable" the information before it could be used by the system. Records with postal addresses, such as telephone listings could be geocoded, that is, have latitude and longitude attached. They could then be entered spatially, as points in the SDE database. Other information was attached to polygons so it could be drawn on a map. An example is taking a list of demographics by county and attaching the items as attributes to the corresponding features in an SDE county polygon layer. Then, a demographic field such as "median housing value" for a county could be queried relationally, but also shown or queried spatially on a thematic map.
To preserve the spatial integrity of the database, all of the geocoding was done relative to the same underlying street data. There were about 200 million records to assemble from the different companies, geocode, convert to SDE format and load into the RIN database. It was GDT's responsibility to write the SDE conversion software and to perform each of these "spatial data integration" steps. A relationship was formed with each data provider, agreeing on an interchange format, running tests using sample data, establishing a schedule and keeping the files flowing through the process.
RIN prioritized regions for data loading that included several important areas where key RIN beta testers were located, or that were near early demo sites. Those most critical areas were loaded first, with the rest of the nation following.
The SDE database designed to support the RIN/Geodata system included the following layers of geographic features:
a) Polygonal Layers - These were GDT polygons with many additional third-party attributes attached:
STATE: Geography, extensive demographics, pollution levels, voter registration, income tax rate, unemployment rate, sales tax rate
COUNTY: Geography, extensive demographics, voter registration, unemployment rate, sales tax rate
ZIP CODE: Geography, extensive demographics, sales tax rate
TRACT: Geography, extensive demographics
PLACE: Geography, crime rate, consumer price index, weather data
b) Geocoded Point Layers - These layers were built from ASCII source files containing an address, but no physical location. They were geocoded to match the street database:
ASSESSOR: Owner, value assessed, date purchased, many details about the property
SALE: Details of real estate sales transactions
FORECLOSURE: Details of foreclosure proceedings in progress
SCHOOL: Test scores, student/teacher ratios, facilities, enrollment by grade, demographics, equipment, budget, administrators and school district data
PHONE: Full national telephone directory listings with mailing addresses, each identified as business or residential
c) Geographic Layers - These are GDT Dynamap/2000(r) with no additional information added:
STREET: Full street coverage for the United States with current names, address ranges and ZIP codes
HIGHWAY: Interstate highways, US routes, state roads and other major arterials
WATER: Lakes, ponds, rivers, streams and other water features
LANDMARK: Parks, airports, military bases, golf courses, recreational facilities, retail centers, airports, churches, monuments and many other general areas of interest
RAILROAD: Railroads, named by owner
Data currency was critical to the system. For example, a client might ask "what other, similar homes have sold recently in this area, and what was the purchase price for each?" Unless the home sales layer in the database was updated often, the most recent (and therefore the most useful) information would be unavailable to the Realtor.
Of course, it was the largest layers that changed most frequently. The relatively small state and county boundaries, for example, are fairly stable. It was the four largest layers: assessor, sale, phone and street that required updating the most often. This data is volatile because:
- Assessor: Property is bought and sold frequently, and municipalities perform re-assessment on a regular basis. RIN planned to update this layer at least annually on a rotating basis.
- Sale : Recent home sales are the most important, so this layer was in need of almost continuous updates. RIN planned to update this layer weekly, using transactional adds.
- Phone : A large percentage of the US population moves or changes their telephone numbers each year. RIN planned to update this layer quarterly.
- Street : There are many changes to the street layer. The Post Office changes ZIP codes frequently, street names are updated and address ranges standardized. In high-growth areas, which are important to real estate agents, streets are added. RIN planned to update this layer monthly, using transactions.
The largest data layers in the RIN/SDE database included:
- Tax assessor data for most parcels in the country: about 70 gigabytes
- A national telephone directory: about 40 gigabytes
- Dynamap street and water layers: about 30 gigabytes
- Real estate sales data covering a minimum three-year time period: about 10 gigabytes
(Sizes are for each full SDE layer including all features and attributes.)
With sufficient disk space on the server (and a knowledgeable database administrator), Oracle was able to handle the tables required to store these five largest SDE layers. Backing up, recovering or updating a single layer in the tens of gigabytes was not deemed practical, however. To preserve the appearance of seamless, nationwide layers, a partitioning scheme was developed.
The idea was to divide the data into logical pieces that could be maintained separately, but create a VIEW in Oracle that would "fool" SDE into thinking the UNION of the pieces was a single, valid SDE layer. To understand how this works, here are a few details of how a layer is created in SDE.
An SDE layer is used to store any collection of logically similar geographic features as a single continuous "sheet." Each layer is given a unique number. For the sake of this discussion, let's say we are working on the nationwide "phone" layer, and that it is layer number ten. When storing layer ten in Oracle, SDE (version 2.1.1 and earlier) creates three tables in the database. The geographic features are stored in a "feature table" which is named "F," followed by the layer number, or F10. Associated attributes are in an "attribute table," called A10. To allow for spatial access to the features in this layer, a spatial index table is created, named S10.
To partition the telephone data, we decided to put each separate area code's worth of points in a different SDE layer, but then UNION all of the area codes together into a single "Phone" layer that looked like layer #10 to SDE. What we did was to first create a separate SDE layer for each area code, plus a layer 10. Then, in layer 10, we dropped the three empty tables: F10, A10 and S10. SDE still believed that layer 10 existed, but its tables were missing.
The second important part of the partitioning scheme involves the internal feature numbers in SDE. At this point, if we were to create a UNION of all of the area code layers, we would have a collision of feature numbers. To relate the rows in the F, A and S tables for a given feature, each feature is assigned a unique number by SDE. These numbers are created from a "sequence" object in Oracle. A "sequence" can be set up to simply give you the next available number in a sequence. For example, you can set up a sequence to start with the number "1," the next time you read it, return a "2," and next, a "3," and so on.
The problem with using these "sequence" objects is each separate SDE area code layer has its own Oracle sequence. Therefore, the first feature in each area code's partition would be numbered "1," the second "2," and so on. If you tried to combine one hundred area codes, there would be one hundred feature #1's, and one hundred feature #2's, and so on. To overcome this, we removed the Oracle sequence objects from each partitioned layer, and created an Oracle "synonym" to point at the single sequence object for our dummy layer, #10. This way, as the point features were loaded for each separate area code, they have unique feature numbers across all of the area code layers.
The final step was to create "dummy" tables for layer #10, to replace the F10, A10 and S10 tables that were dropped. This was accomplished by creating three Oracle "UNION ALL VIEWS" one each for the F, A and S tables. The view F10 was a "UNION all" of the F tables for the different area codes. Similar views were created for the A and S tables.
Once the three views were created, SDE would read layer 10 and believe it was accessing a single layer containing point features for all area codes in the United States. But, the system administrator was able to backup, recover or reload a single area code by dealing with its smaller, individual partition. Had it not been partitioned, a single phone layer would have needed to contain around one hundred million point features, plus associated attributes.
It should be noted that the partitioning scheme only works for READ access to the data; you can't write to the UNION ALL VIEW. When modifying points in a specific area code, it was necessary to perform the update on the individual partition layer for that area code. Since the RIN system needed read-only for the end users, this arrangement worked well. It was only necessary for the database maintenance team to understand the partitioning scheme and apply updates to the appropriate layers by area code.
In this discussion, the "phone" layer was used as an example. A similar partitioning scheme was used in the RIN database for the other large layers: assessor, sale, street and water.
Because it was the first SDE project of this magnitude for all of the RIN partners, including Esri, RIN was an excellent learning experience. Overall, we decided that SDE was well-suited to this type of large-scale GIS system. Here are some specific observations from having built the RIN database:
- It is important to have a knowledgable Oracle Database Administrator (DBA) available to configure the database properly and monitor it as the tables grow and users begin accessing them. This would be much less important for a smaller system, but the size of the RIN data often pushed the normal limits. A large Oracle installation is complex, and you need to have someone present who knows what they are doing.
- Spreading disk I/O is usually the single most important factor when tuning SDE performance. We moved the feature (F), attribute (A) , spatial index (S) and Oracle-generated indexes to four different Oracle tablespaces. To the extent possible, these four, plus the TEMP tablespace were divided among different physical disks on separate controllers.
- Setting up the grids properly for each layer was another important performance factor. SDE uses a grid scheme to spatially index its geographic features. Though SDE allows up to three levels of grid to be specified, for all of the RIN layers, retrieval speeds were markedly improved by only using the first level. Refer to the SDE documentation for the best methods of determining an optimal grid size.
- SDE, in general, worked well right from the start. Our early prototypes were based on the beta software in mid 1995, before Esri had released SDE as a product for the first time. The few bugs we found could be worked around. Subsequent released version of SDE appear to have been well-tested; they have performed solidly. Installing and monitoring SDE was as simple as the same for Oracle was complex.
- Geocoding throughput was an early bottleneck, with two hundred million records to process in a short time. Some of the problems were due to corrupt or missing input data from outside sources. Quality checking software was developed to detect these problems earlier. Performance of the geocoding systems was significantly improved from speeds in the thousands of records per hour to the hundreds of thousands. Jobs of this size are now almost routine.
- We ran into several difficulties with our partitioning scheme on the large layers. Our first attempt at partitioning a layer using an Oracle UNION ALL VIEW was done with Oracle version 7.1. Though UNION ALL worked well in 7.1, there was a bug when using the LONG RAW data type. SDE features are stored in LONG RAW fields in the "F" table, so partitioning did not work. That bug was fixed -- just in time -- with the release of Oracle 7.2. The bad new was, due to another Oracle bug, performance of the UNION ALL was very slow with more than a dozen or two tables participating in the UNION. (We were trying to more than five hundred tables in several cases!) This bug was that the UNION ALL command ignored a range constraint clause telling it which ranges of primary keys were in which tables in the UNION. As a result, it would search the indexes of all tables in the UNION, slowing performance significantly. This was not fixed by Oracle until version 7.3
- It really is possible to run a large project with key pieces coming from a dozen different companies if it is well managed. Good communication was crucial, including written specifications, a clean division of tasks between well-chosen companies, and weekly (or more) conference calls involving the key technical people. Esri's implementation services group, led by Mike Tait, was a pleasure to work with (and I'm not just saying this because the paper is a part of their User Conference!) They were professional, competent and dedicated, putting in countless hours to meet deadlines and building a quality product.
- The biggest single frustration with the RIN project was its termination. Just as the database was completely loaded and the system software finished its beta test cycle, RIN exhausted its finances. The National Association of Realtors which had so enthusiastically funded RIN initially, decided to focus its resources elsewhere. It should be noted that this was in no way due to any failure of the system to perform as expected; it was a business decision made for other reasons. We did learn much from the experience, however, and that knowledge is being put to good use. Esri's core server software, called GeoServer, has been adapted and re-used for numberous other clients. GDT has entered the SDE business, providing Dynamap data, Spatial Data Integration and SDE conversion expertise on many new projects.
AUTHOR
Mark Harley
Principal Engineer, Geographic Data Technology, Inc.
11 Lafayette St.
Lebanon, NH 03766-1445
Telephone: (603) 643-0330
Fax: (603) 643-6808
E-mail: markh@gdt1.com
Web: http://www.geographic.com/