 Arabic
Cartography
Arabic
CartographyMohamed F. Mabrouk, and Walid Effat
In increasingly growing markets such as Egypt's and other countries in the Middle-East, North-Africa, and other regions, one can easily realize that Geocoding is one of the most needed GIS capabilities. Unfortunately, Geocoding in those countries is still undergoing an uneasy take-off and the standard matching of addresses used in GIS software packages of today still cannot be directly applied because of some cultural differences.
The paper investigates the reasons for why Geocoding is not a popular application of GIS in the Arab region and other comparable regions. Cairo was selected as the typical middle-eastern city and its streets and patterns of addresses were used for this study. ArcInfo was the GIS software used in the study and was selected because it's the de facto standard.
Experiment showed that inability to apply address-matching in native language and different styles of addresses were the main reasons for the problem. Arabization's principles and techniques were explained specially its features related to address matching techniques. Then, samples of Cairo's streets were analyzed for their style and distinct differences from standards used in ArcInfo. Some workarounds were introduced and thoughts on a more open structure of addresses providing for further internationalization were explained.
Authors' research has relied mainly on lab results, informal conversations and correspondence with active experts in the field of GIS Arabization such as Mr. Munir Kawar-Jordan, and Mr. Ayman Hindam-Egypt. During the research, it was noticed that references in the field of Arabization are extremely rare if not non-existent. Manuals covering various Arabization packages were used and reports on the WWW were studied--and linked to. Links to important Web-sites are included in this document (functional provided that connection exists for the reader of the document in its HTML format and that owners still maintain under the same address.)
The facts, assumptions, and test results recorded here remains true (to our best) to the version of ArcInfo 7.0.3 and its Aljographi Arabic Language Supplement, AL-MASHRABIA's ArabArc 1.5.1 on SunSparc with Solaris 2.5.
The authors hope sincerely that this demonstration of some experiences in that subject should pave the way for a better usage of the Address-Matching capability for the many applications of Geocoding not only in the Arab region but in many non-Western regions as well.
The authors would like to notify the reader that this is still an early stage of research on such problem and consequently this paper is reporting the authors' findings up to current stage of research. Other reports on later stages should be expected in the future.
Issues that hinders an operational Geocoding, in a typical middle-eastern country like Egypt, lie mainly in two fields: Arabizing the data, and Arabizing the Addresses styles used in the Address-matching.
Arab people are those who speak the Arabic language but who do not necessarily belong to the Arabic ethnological groups (pure Semitic) like, for instance, in the case of Egyptians and Syrians. However, and because of the tremendous widespread of Islam in the last millennium and a half from the Yellow Sea in China to the Atlantic ocean bordering Europe and Africa, collective efforts were to bring about a certain kind of art and culture that is, however different from one native civilization to another, is somehow based on common values and philosophy. This art previously called Arabic Art is now named by most scholars 'Islamic Art' and had Calligraphy at the middle of its heart. One can observe some excellent original examples of Islamic Art in many places around the world, such as Taj-Mahal Mausoleum in India, Sultan Hassan Madrasa in Egypt and Al-Hambra Palace in Spain.
Arabic
CartographyNowadays, considered one of the most finest of all, Arabic Calligraphy is facing new challenges. After a humble start in block letters millennia ago, Arabic letters as the medium of Allah's words, received attention--almost unprecedented to any language's script--from the artists of the major civilizations of the ancient world; Egypt, India, Mesopotamia, Persia, China, Assyria, and even from Spain and more. This to a certain extent has complicated the way Arabic Cartographers has to do their work. This could be the reason why some modern Arab cartographers has complained that Arabic digital cartography is still immature. This in fact is an interesting opinion, since Arabic letters are not confined in usage only to Arabic-speaking countries, but also are the writing letters for several other non-Arabic speaking nations. So, in spite of the fact that Arabic has received some of the most advanced technical efforts to be computerized, there is still much innovations to be done in the field of Arabic scripts for Cartography.

Since almost a millennium ago when the celebrated Arab cartographer and geographer AL-IDRISI (after which some famous GIS software is named) did his popular map in Arabic, it has served as primary reference for over 500 years for many Arab and non-Arab researchers.
 1.1.2.
Arabic Alphabet
1.1.2.
Arabic AlphabetArabic alphabet is composed of 28 letters (Table 1). They sound mostly like those in the English alphabet except the lacking of the V and P sounds that are not pronounced in the Arabic tongues, but with some additional guttural sounds (like the HAH and AIN) that Latin speakers cannot give voice to. In Arabic there is no direct equivalents of the Latin's upper and lower case representations.
Arabic letters, opposite to Latin, are written and read from right to left (technically called RTL). This makes writing a book or publishing a magazine in Arabic language seems like exactly opposite to ones done for Latin--the magazine or book starts from its 'Latin' end which is the right side. For instance, some comic books such as Asterix, Tin Tin, or that of Disney's are licensed to publishers and translated to Arabic. They actually get a mirrored copy of the complete page of drawings to keep the sequence straight to the Arabic reader and then imprint their translated scripts.
In spite of the fact that the realization of the advanced system of Arabic numerals (compared to its European predecessor called Roman Numerals) is the contribution of the Islamic world, most Arabic speaking countries don't use such representation of numerals and are the only exception probably world-wide in that! In fact most of the Arab countries (e.g., Egypt) use the Hindu Numeral instead which are merely a different symbolization of exactly the same system. They involved the concept of the 'Zero' which is stylized from the Arabic word for nothingness and that has completed the decimal system that everybody use nowadays. Hindu and Arabic Numerals follow exactly the same orientation of writing; less significant numbers (e.g. the one or the four) to the right and more significant ones to the left (e.g., the one thousand or the four millions.)
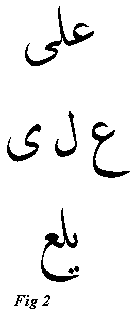 1.1.4.
Technical Challenge
1.1.4.
Technical ChallengeArabic letters unlike the Latin letters that is written on computers from LTR, they not only pose the challenge of changing the direction of writing of the words on computers to RTL, but has more major obstacle. Its cursive nature with letter-connected words in scripts are established millennia ago since the pre-Islamic times. This very nature of script made necessary certain complications in the digital representation of Arabic. An example is shown in (Fig 2) where the name Ali is written in Arabic from right to left. The first has simply the name "Ali" correctly written in Arabic in RTL. Second line is where the three Arabic letters AIN, LAM and YEH (ordered from right to left) from which the word is composed are displayed under their respective positions in the word. And just to give a hint about the further complexity of shaping of the letters according to their context, the third line includes the same three letters connected again but in a reverse order. Each of those letters, such as the YEH letter, has several shapes according to its position (context), but only one unique code to represent it in its ASCII-like table called code page. Thus, Arabization software has to analyze the context of each letter to give it its suitable shape.
Early developers of Arabization software devised their own code pages. Their size was devised similar to ASCII (the English language standard code page) which is limited to the maximum of 128 characters. This was due to the fact that only 7 bits were used to store the code of each of the characters and ignore the 8th bit of each byte. Arabic code pages are mostly called ASMO. A good example of an Arabic 7-bit code page is ASMO 449. Today, developers cannot ignore standards and for best results, it must be a non-overlapping and neutral 8-bit code page. ASMO 708 also known as ISO 8859-6 is becoming the choice by many developers.
In the early versions of Aljographi (Esri's official Arabic Language Supplement to ArcInfo), it was necessary to arrange for the user to use a special Arabized Terminal hardware to enter intelligible Arabic letters to the prompt line of ArcInfo. To enter bi-lingual text, special switching characters were used. Aljographi uses currently the curly brackets '}' and '{' as its switches to Arabic and to English respectively. Later in the version studied, the need for such expensive and cumbersome Arabized Terminal was eliminated by developing software utilities.
ArabShell is a specially designed utility that has an Arabized input field. The utility could be evoked from within any of the prompts of ArcInfo. In normal conditions, ArabShell functions properly and can include bilingual text in one line using the switches to Arabic and to English.
A command that could be initiated from any prompt or AML routine of ArcInfo. It has the ability to display Arabic texts in 7-bit Arabic code page and in 8-bit as well as Latin in the same window.
Among other text-based applications of ArcInfo, Address Matching engine is one of the most complicated. In the opinion of the authors, proper Arabic address-matching procedure depends solely on a good adjustment of the following:
The following is the argument of the authors on what is the nature of each of those adjustments.
Aljographi works by default with a 7-bit code page which necessitates that the switching '}' and '{' characters be included in the string. It also offers 8-bit as an option. Authors have tested other successful ArcInfo Arabization software available in the market such as AL-MASHRABIA's ArabArc. It utilizes 8-bit ASMO 708 (a.k.a. ISO 8859-6) as its default code page.
From the authors' experience, only the use of 8-bit code pages such as ASMO 708 should be applied for the use of Address Matching in ArcInfo. It is practically impossible to use 7-bit code pages and some good reasons are listed below.
8-bit code pages don't need any switching codes to be stored with the string to show the system when to switch to English and when back to Arabic. On using 8-bit, Switching brackets and all other stored switching control characters will be unnecessary which will save all the confusion and potential attempts to adjust the source code of ArcInfo to ignore the switching characters whenever found during the processes of data manipulation. More reasons are:
Incompatibility means that the procedures set in ArcInfo for address matching are somehow biased. For instance, Arabic words has its own definite article word--the ALEF-LAM letters connected to the beginning of words. This should be normally ignored so that better chances of matching could be obtained. Also, certain single characters (e.g., Kashida) need to be ignored. ArcInfo in its current state doesn't provide for those necessary functions. Because of this and others, probability of the matching of input and reference addresses in Arabic is relatively much lower than in the case of techniques used for English.
Certain workarounds have been tested and proved successful. For example, one can ignore to insert the Kashida in the first line of the Arabized Soundex file. This will eliminate the existence of Kashida in the Soundex of the street name.
Unicode is rapidly approaching a maturity. With some disadvantages such as the double size of data compared to the normal size of normal code pages, Unicode promises to prove peerless as space problem of data storage gets lightened by time.
A brief analysis to the usage of Unicode shows that it is needed the most in multi-lingual environment that necessitates either the usage of several languages in the same document or the frequent exchange of data of different native languages. If the users' software (GIS in our case) is not ready to properly display and handle those other native languages, it will leave its user helpless.
Maybe the GIS domain is not probably in desperate need to Unicode as the WWW is right now. However, once it becomes the prevailing standard on Internet, many data processors will have to comply with such seemingly unnecessary standard. It is in the opinion of the authors, that the complications of including such standard to a certain software package such as ArcInfo could be cumbersome, if not taken into consideration early enough and been prepared for.
Generating, maintaining and using 8-bit Arabic data is the only way to deal with Arabization as explained above. Using Arabic 7-bit data for address-matching seems ridiculously cumbersome and even practically impossible because of the so many problems it has and impacts on how ArcInfo should be handling Arabic data.
Western styles that many countries has followed are not the only styles that exist in our world of today. If not for cultural differences, it could be because the lack of a good system of enforcing a systematized approach of addressing. Those countries still have many users who wish to benefit immediately from the many advantages of Geocoding.
This is a brief report on some of the efforts of research to be shared with Esri that is expected to be fruitful in the future of a better handling of Arabic Address's.
This process is done through the ADDRESSCREATE command in the ARC module. With either of the two options PARSE or NOPARSE (depending on the form in which addresses data are arranged), the command creates a .ADD info file that relates to the .AAT of a street address coverage.
The .ADD file includes the items ADDRESS and SOUNDEX among other items, which are critical to the functioning of the Address-matching process. Several elements of the street addresses are included in the ADDRESS item. The SOUNDEX routine of this command picks only (according to previously stated assumptions) the streets name element and convert it to the six-characters format of SOUNDEX in the item SOUNDEX. All other elements are standardized to its abbreviated form like Street Type and put in place, according to a fixed order. right after the Street Name.
Attempt was to represent the following translation for the styles of Cairene addresses in a way that--however not accurate--would be able to make the point we wish to explain. Please note that order of address elements was left exactly as it would be in Arabic but made LTR.
Explanations of how the previous styles are different from the standard which is handled in ArcInfo:
In addition to few and minor general characteristics of the system, it seems that the problem splits naturally to two branches: addresses based on block (polygon) identification and on streets and house number identification.
Analysis
A table of separated items of address elements was conceived by authors to describe how those styles mentioned above could be grouped together in one common system of identification. Please note that translation has rendered names representation in Latin but kept RTL orientation intact as much as possible.
|
District |
Subdistrict |
Block |
Building Indicator |
| Heliopolis | Division Asmaa Fahmi | 4 | B |
where:
Subdistrict: is the site that comprises this style of addresses in the district-not the whole district is addressed in the same style.
Block: usually a number representing a group of buildings.
.ADD File
|
Address |
Zone 1 |
Zone 2 |
|
A F 4 |
Divison Asmaa Fahmi | Heliopolis |
where:
A (From Building Indicator), F (To Building Indicator) in Address (required): are the address range from number 'A' to number 'F' and engine should be able to match with it if any number within the range was spotted namely; A, B, C, D, E and F. It could be in other cases as normal as 1 to 6.
4 in Address (required): is the representation of the Block.
Zone1 (required)
Zone2 (required)
Analysis
Due to many needed customizations, the authors research was initially inclined towards a dramatic change in both the data structure and in the way commands handle those structures. Later, a device although seems simple, was designed with a rather sophisticated concept, that can keep the conventional data structures intact to a far extent and yet can provide for the necessary adjustments.
A sample of the different styles of addresses are as follows. Again, although translation or--in some cases transliteration--was done, orientation is kept intact as much as possible:
| Zip | District | Street Name | Street Type | Num Ext 2 | Num Ext 1 | Number |
| 11211 | Zamalek | Ismail Mohamed | Street |
- |
- |
23 |
where:
Number (required): the normal House Number except that it should be able to hold letters and be able to work on ranges that are composed of those numbers. For example, a range could be formulated from B to G.
Street Type: must precede Street Name in Arabic. For Arabic customization, it should has at least the following types: Sharia, Harah, Atfah, Tareeq, Sikkah, Zuqaq, Midan. This will require a complete change of the STREET.TYPE info file.
Street Name (required): Soundex for that element will be discussed in details later on.
District (required): what we might be able to describe as Zone 1.
Zip: Zone 2.
.ADD File
Suggested structure of standardized .ADD addresses is the same as original, although different at least in the order of items. Nonetheless, the usage of such items has been altered to suit the needs of internationalization.
|
Address |
Zone 1 |
Zone 2 |
|
13 29 Street Ismail Mohamed |
Zamalek | 11211 |
Considerations:
Address-matching is (according to the knowledge of the authors) mainly embedded in the commands ADDRESSMATCH in ARC module and MARKER * (with COORD set to KEY ADD) in the ArcPlot module. Functioning in a similar way, the only difference is on the amount of records they can take at each execution of the command. However, our following discussion will be considering only the MARKER command in ArcPlot.
The above discussions served to introduce to the next part. It is where we are going to show some more practical suggestions towards an experimental version of ArcInfo that can provide for the international needs for a more open architecture of the addressing styles.
This text file will be used by several routines of the Address-matching commands, and it is to store the necessary information about the style of address used in application. It contains information about the order of elements of the address that suits the most the country of question in addition to the widths of the user-defined items.
An example of the physical contents of the file could be:
3
1
5
4
6
7
0
3
6,20
which could be explained in the following table:
Name of item |
Order Defined |
Items Width |
Notes |
number of Extensions |
3 |
- |
default is 2. This must not be left blank. If user intends not to define any additional (3rd) Extensions, '2' must be placed in that row anyway. |
House Number |
1 |
- |
contained within ADDRESS item in .ADD |
Street Name |
5 |
- |
contained within ADDRESS item in .ADD |
Street Type |
4 |
- |
contained within ADDRESS item in .ADD |
Zone 1 |
6 |
- | - |
Zone 2 |
7 |
- | - |
Extension 1 |
0 |
- |
aka 'Prefix Direction' optional item. this order of '0' means that item is to be removed entirely from .ADD definition |
Extension 2 |
3 |
- |
aka 'Suffix' optional item. this order of '0' means that item is to be removed entirely from .ADD definition |
Extension 3 |
6 |
20 |
User-defined item. Must be defined within the ADDRESS item in .ADD |
Notes:
This is an info file that is designed to hold all the possible abbreviated forms of all possible types of streets. For Arabization to take place properly, this file will be appended with Arabic names entered in the same fashion explained in manual. Arabic names will have to be entered under the same mode of 8-bit code page that Address-matching will work under.
Explained previously in 1.3.2. was the need to ignore ALEF-LAM letters, among other things, from some words. A text file of the name ADDIGNORE.TXT is suggested to hold a list of all those names that the user wishes to be ignored. The process will be as if the combinations has been completely omitted from address strings. This however, has to be intelligent enough (following simple preset rules) differentiating, for instance, ALEF-LAM as definite articles at the beginning of the words from ALEF-LAM that are part of words.
Geocoding applications in the Arab region (as is the case in some other regions), used to suffer some difficulties. The authors, who are involved in some major projects in the Arab region, believe that it is not only becoming possible, but in fact it is happening. The authors are aware of the fact that Cairo, the city of more than 35000 inhabitants/km2, of nearly four thousands kilometers of streets and of the one thousands nights and a night, is experiencing the applications of Geocoding today. More cities data in the Arab region are now underway (soon in other developing regions as well) to make a world of GIS applications unprecedentally available to decision-makers and markets' experts thirsty for applications such as: local government applications, marketing applications, emergency dispatch, transportation routing optimization, localized AM/FM and more.
The authors would like to express their appreciation to Ahmed Ayoub, Chairman to Regional Observation Center, and a friend, for continuous valuable assistance and motivation. Special thanks go to Ayman Hindam for his deep insight of Arabization, long discussions, and for the fabulous graphic of AL-IDRISI map. Also, thanks to Tarek Mabrouk for his beautiful colorful piece of Arabic Calligraphy.
ALJOGRAPHI is a trademark of JoGraph.
AL-MASHRABIA is a trademark of AHO.
Stands for Arab Standards and Metrology Organization. It also lends its name to a variety of code pages of the 7-bit and 8-bit sizes. For example, ASMO 449 is 7-bit, whereas ASMO 708 is 8-bit and is an alias for ISO 8859-6.
Numerals that are used internationally by all countries except some Arabic countries. Have replaced Roman numerals in medieval Europe.
A code page is a table that assigns each of the alphanumeric characters and symbols used in a certain language, a unique code. For instance, ASCII is the standard code page for the English Latin. Code pages has now mainly three types:
a) 7-bit pages: the maximum number that can 7 bits hold is 127 which is the number of cells a table of the size of 7-bit can use. Therefore, this type of pages (if we subtract the first 32 cells that are reserved for the system's unreadable codes in addition to a few more things) will leave only approximately 96 cells for alphanumeric characters and other symbols. This means that you can only store the alphabet of one language. In bi-lingual manipulations of texts, a Switch-To-Arabic and Switch-To-Latin are needed to indicate which code page to use for each code. ASMO449 is a 7-bit code page. 7-bit code pages are neccessarily overlapping.
b) 8-bit pages: the maximum number that can 8 bits bear is 255 which is the number of cells a table of the size of 8-bit can use. Double the size of 7-bit pages, 8-bit code pages can store the alphabet of two languages at the same time. This allows the placement of English Latin letters assigned the same codes exactly as in ASCII whereas, all Arabic letters are assigned codes in the other upper half of the page. Another major advantage is that the Switches are not needed any more since codes are indicative of its own language. ASMO708 is the common standard 8-bit code page.
c) 16-bit pages: new emerging standard often called Unicode.
Unlike printed letters in Western alphabets, Arabic letters like other cursive scripts (e.g., Devanagari) frequently change shape at different positions in a word. A letter might have up to four different shapes, depending on whether it stands alone (isolate) or comes at the beginning (initial), middle (medial), or end of a word (final). Any basic Arabization software must (to just be able to give shape to any entered Arabic letter) analyze its context and pick a shape from the font page.
In the Arabic written language, one of the small symbols occurring above and below Arabic characters used to indicate certain short vowels (accent marks) and other language characteristics. Being somewhat poor in its letter vowels, diacritics (tashkeel) are often needed (although optional for most writers) to differentiate between different words that are spelled the same.
Special page that complements an Arabic code page. ASMO (a code page) gives every Arabic character a unique code. However, each character has different shape depending on its context in word (See contextual analysis) that are all defined in a font page.
Numerals that are used in most Arabic countries. Used and ordered exactly like Arabic numerals.
In the Arabic written language, certain characters may need to be elongated along their horizontal axis for esthetics. The elongated part of such a character is called its 'Kashida'. For instance, in Western languages, when a paragraph of text is justified on both sides, space is added between words to fill out lines and align them to the left and right margins. However, justification in Arabic is done using Kashidas.
Individual characters joined together to form a single typographical unit. It is a combination of two or three characters into one shape, such as joining an "a" and "e" into the "æ" shape. If one character of a ligature is deleted, the remaining character(s) should automatically revert to the correct shape according to context.
Left-To-Right. Direction of progress of typing in line. Used for Latin characters.
Physically in computer files, only codes representing characters are stored. If any user-interface or other computer applications attempt to decipher this file, they must be equipped with a certain table that we call code page to interpret those codes with. Sometimes in multi-lingual environment certain precautions must be taken to not to confuse certain standard characters (e.g., Numerals) across languages. A page is referred to as neutral when it offers (within its coding scheme) only one set of codes for both Hindu and Arabic numerals (e.g., ASMO 708). This feature is available only to 8-bit code pages.
On the other hand, in the case of some 8-bit code pages, there are one set of codes assigned Arabic (the one used internationally) numerals in the lower part of the page (coded from 0 to 127) whereas, the Hindu (used in Arabic countries) numerals are put in the upper half of the page with the Arabic letters. A good example for such a page is PURE708, where the Hindu numeral TWO, for instance, is coded 178 whereas the same numeral in Arabic is coded 50. PURE708 could be referred to in this document as non-neutral code page.
The phenomena of assigning different languages' letters to the same codes. In 7-bit code pages, one will find that while the code of '74' represents the Latin letter 'J' in ASCII (the standard English code page), the same code represents the Arabic letter of 'TEH' in ASMO 449 (a standard Arabic code page). This phenomena necessitates that some sign should be given to computer processor, upon which it will decide whether to interpret the code in hand as Latin or as Arabic. In non-English 8-bit code pages (double the size of 7-bit) such as ASMO 708, non-overlapping is reckoned essential, that is, all first 127 cells of the page are English Latin exactly as in ASCII, whereas the next half (codes of 128 to 255) is assigned the Arabic (or other languages') characters. Thus, the two languages' letters are spread over two different ranges of codes.
Right-To-Left. Direction of progress of typing in line. Used for Arabic characters.
Much larger than the 'normal' 8-bits code pages with room to only 256 chars. Unicode is a new universal 16-bits code page with space for 65536 characters. This seems enough room to combine all known writing letters of all known used languages in addition to all sorts of symbols like mathematical, dingbats, etc.
For more you can read http://www.asca.com/ for a necessary introduction.
The Software Arabization Page. http://www.palnet.com/~jack/arabic/ (Internet connection must be maintained for that link to function properly.)
The Unicode 2.0 Charts. http://intleng.apple.com/Unicode/Unicode2.0.html (Internet connection must be maintained for that link to function properly.)
Geocoding User's Guide. 1995. Address Matching. Environmental Systems Research Institute, Inc., Redlands, CA 92373 USA.
ALJOGHRAPHI User's Guide. 1991. JoGraph, Redlands, CA 92373 USA.
AL-MASHRABIA ArabArc User's Guide. 1997. Ayman Hindam Office, Cairo, Egypt.
Ayman HINDAM, 1996 and 1997. Informal Conversations. GIS Specialist and President of AHO, Cairo, Egypt.
Mohamed F. Mabrouk GIS Analyst and Technical Director with the Regional Observation Center (ROC)-Egypt. Correspondence maybe sent to: Regional Observation Center, 4B Takseem Asmaa Fahmi, El-Nozha Street, Heliopolis, Cairo 11341, Egypt. Tel: +20 2 2906151, Fax: +20 2 2901196, Email: roc@ritsec3.com.eg, or mmabrouk@idsc.gov.eg
Walid A. Effat GIS Specialist with the Regional Observation Center (ROC)-Egypt. Correspondence maybe sent to: Regional Observation Center, 4B Takseem Asmaa Fahmi, El-Nozha Street, Heliopolis, Cairo 11341, Egypt. Tel: +20 2 2906151, Fax: +20 2 2901196, Email: roc@ritsec3.com.eg, or weffat@iti-idsc.gov.eg
{kind=link}
{kind=link}