|
|
Phil Friesen and Benjamin Lydon
Modeling Land Use Change: Using GRID to Develop Scenarios for Colorado Springs� Comprehensive Plan
GRID was used to model future land use patterns for the update of the City�s comprehensive plan. Four land use types - residential, retail, commercial services, and industrial - were modeled. Logistic regression was used to correlate existing land use with factors having a significant influence on land use development. The resulting coefficients were applied to grid cells representing vacant land, yielding four probability surfaces. Cells were then allocated until specific targets, determined by market analysis, had been met. A "base case" scenario for the year 2020 and a set of alternative scenarios, reflecting potential changes in the development environment, were generated.
Introduction
The City of Colorado Springs is currently revising its Comprehensive Plan. The Comprehensive Plan has traditionally been a policy-based plan, providing general direction in a myriad of areas effecting land uses. However, it was desired that the revised plan differ in a number of ways, including a strong focus on physical development issues and on future land uses in the City. It is this aspect of the plan that prompted GIS staff within the City Planning Group to look for ways in which GIS could be used to substantially contribute to the process of visualizing what the City might look like in the year 2020. While GIS has traditionally been used by planners to overlay and analyze spatial data representing existing features such as land use, land cover, terrain, etc., ARC/INFO�s GRID module contains tools that extend the functionality of GIS into the realm of predictive modeling. Since the City�s population has grown from 280,000 in 1990 to more than 330,000 currently, and has an incorporated area of nearly 186 square miles, of which 47% is vacant, city planners were quite interested in any methodology which could provide insight about the future development of this vacant land.
This paper describes how a land use allocation model was developed to project land use patterns. A turnkey package has not been developed nor can this methodology in any way be construed as a complete solution to the problem. Neither has a great deal of attention been paid to rigorous statistical technique or to model calibration � a shortcoming which appears to be alleviated by access to high-quality data. Given these caveats, the approach has proven to be an effective tool that works with the data available, integrates well with the other non-spatial methodologies employed in the revision project, and provides sensible information at a level of detail that would be difficult, if not impossible, to replicate manually.
To date, the model has been used to generate "no-change" and "open space" scenarios. The "no-change" scenario projects 2010 and 2020 land use patterns that could be expected if City policies and regulations remain unchanged and there is a continuation of the pattern of development of the last several years. The "open space" scenario indicates land use patterns resulting from the removal of open space candidate areas (as identified in the City�s open space plan) from the possibility of development. The generation of additional scenarios reflecting various transportation and redevelopment alternatives is anticipated.
The Land Use Allocation Model
At the outset of model development, a literature search was done to ascertain what kinds of models had been constructed elsewhere that might have relevance to our situation. In so doing, a primary concern was that our methodology be compatible with other components of the Comprehensive Plan revision process. In particular, a market analysis was to be conducted which would provide land demand forecast values for four specific land use types: residential, commercial service, commercial retail, and industrial. These values would be provided for nine different geographic areas, termed Planning Evaluation Zones (PEZ), into which the city was divided. Our model would need to spatially allocate these land uses within each PEZ, the results of which could then be re-aggregated by other geographic boundaries such as Traffic Analysis Zones and Census Tracts.
We found that within the context of the past several decades of urban modeling, our requirements seemed to most closely match the characteristics of what Sui has termed "first generation" urban models (Sui, 1997). This approach conceptualizes cities as mechanistic systems and employs "top-down," deterministic methods to make projections. The land demand values provided were developed by such a "top-down modeling approach" (Hammer, Siler, George, Associates, 1998) and we found that GRID contained a logistic regression function that would work well with the spatial data sets at our disposal. The "California Urban Futures Model," developed at the Institute of Urban and Regional Development (Landis, 1995; 1997), served as a guide and reference source for initial development.
"Second generation" models, as described by Sui, "conceive cities as complex systems which involve a large but finite number of intelligent and adaptive agents." Here, a "bottom-up," dynamic approach utilizes algorithms that incorporate principles of self-organization and rules of behavior which govern how agents may act but do not prescribe action outcomes. A more complete discussion may be found elsewhere (Batty, 1996). Although this approach is highly attractive, and has been at least partially implemented in GRID for such purposes as wild fire modeling, it was not followed for a number or reasons. These included a perceived lack of compatibility with other plan revision methodologies and the daunting task of learning the theoretical underpinnings, creating the algorithms appropriate to our situation, and developing the software within a reasonable time frame.
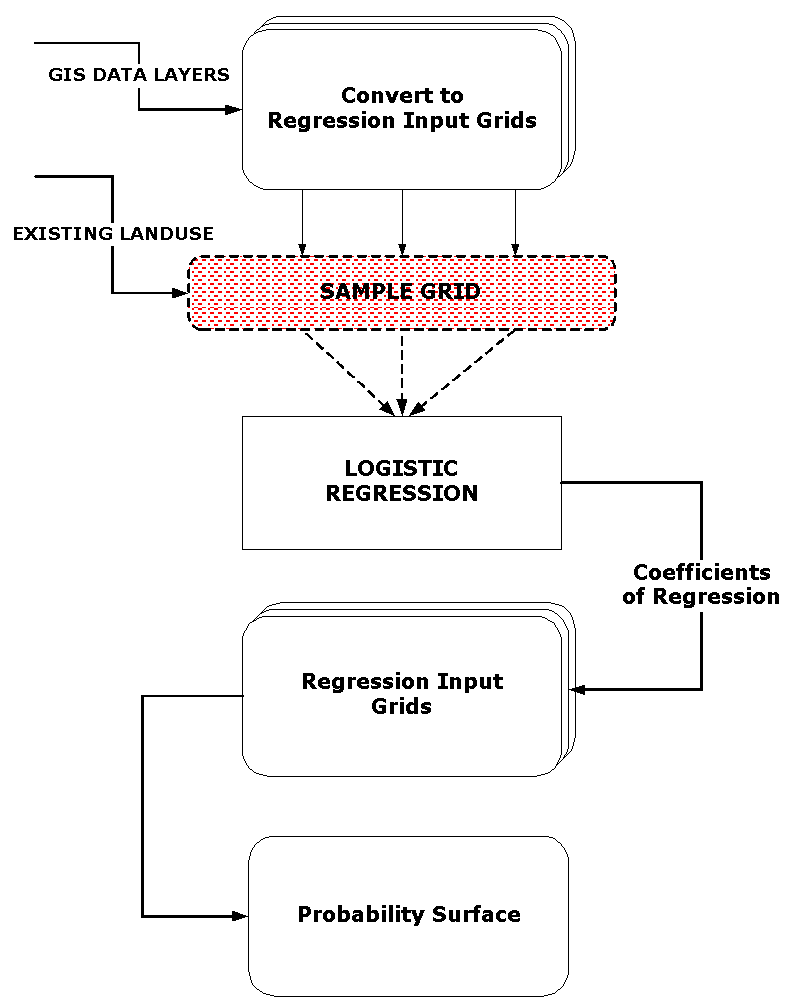
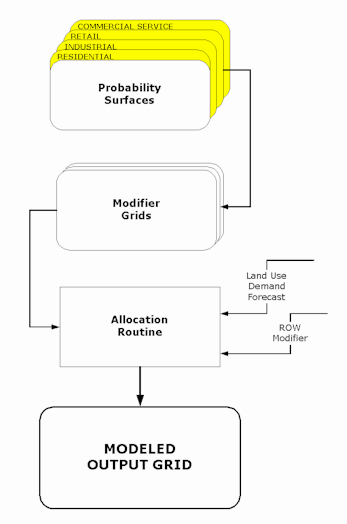
GRID�s logistic regression command allows the generation of probability surfaces for each of the land use types. Logistic regression analysis is used to determine the relationship between an unknown variable (the dependent variable) and multiple known, explanatory variables (the independent variables). The presence or absence of the unknown variable, i.e., land use type, is predicted on the basis of the known variables, which in this case are such characteristics as slope, flood plain, and transportation-related factors. Given input grids of these variables and a set of sample points indicating where a particular land use type is and is not found, an output grid can be generated in which each cell contains the probability value that the land use type will be found at that location. The diagram illustrates the process and the elements involved are explained below.
|
|
Sampling of Existing Land Use
A land use coverage had been developed previously using El Paso County Assessor data from May of 1997. The detailed land use categories in this coverage were aggregated and converted to grids for the four general land use categories of residential, industrial, commercial service, and commercial retail. A template sampling grid was then generated which contained sample cells every 200 feet throughout the city. This template grid was combined with each of the land use grids to yield grids with cells every 200 feet with values of �1� where there was an intersection with a land use category and �0� where there was not. The next step was to randomly remove grid cells until an approximately equal number of zero�s and one�s was obtained. These grids were then used as mask grids with GRID's sample command. The end result was a set of ASCII text files containing values from the input grids at the locations specified by the mask grids.
Data Inputs
Data was perhaps the most important factor that determined the success or failure of the land use model. Accurate land use, slope, transportation, and utility spatial data were already available. The next step was to convert these vector data sets into something the model could use to make a prediction. Three factors served as a general guideline: 1) the data values needed to be on a continuum or ranked scale since logistic regression cannot be applied to nominal values, 2) data values needed to be between 0 � 100 (if values exceed this range, significant digits were lost in the regression output coefficients), and 3) the data needed to represent the area of effect of a feature. Utilizing a GRID based analysis necessitates expanding a point feature to more than one cell.
The preparation of flood plain and transportation data illustrates the application of these factors. Conversion of the flood plain coverage into a grid retained the original data values of 0, 100, and 500, corresponding to areas of no flood plain, 100-year, and 500-year flood plains. However, an area within a 500 year flood plain is not five times more likely to have a flood than an area in a 100 year flood plain. Therefore the no flood plain value was modified to 1, the 500-year flood plain value to 10 and the 100-year flood plain to 50, thus generating a least likely to most likely continuum and preserving the data relationships. Another example illustrates how transportation line features were utilized. From analysis of the existing land use coverage it was discovered that 80% of the commercial land was within � mile of an arterial street. This indicated that distance from a transportation line feature could predict land use. A grid was generated in which values were populated with distances from arterials. These values were then generalized into � mile bands and reclassified to yield values ranging from 0 � 8. Thus zero represented the � mile band closest to the road and seven the band that was 2 miles from the road. When banding distance data, it is important to determine an increment that has distinct characteristics. A value of eight was assigned to cells that were farther away than two miles, the assumption being that an arterial had the same minimal impact on all areas beyond this distance.
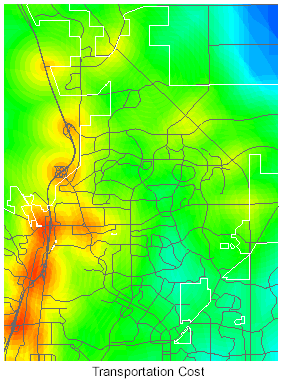
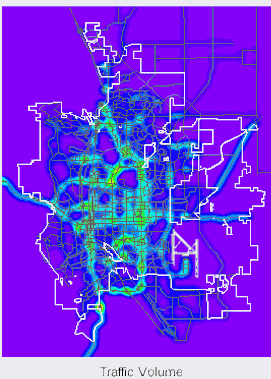
Input grids were constructed for the following types of features: traffic volume, street class, truck routes, exit/entrance ramps, rail lines, slope, ruggedness of terrain, proximity to open space, and flood plains. Grids for truck routes, ramps, and rail were combined into a single transportation cost grid. Below are illustrations of a portion of the transportation cost grid and the traffic volume grid.
|
|
|
Calibration
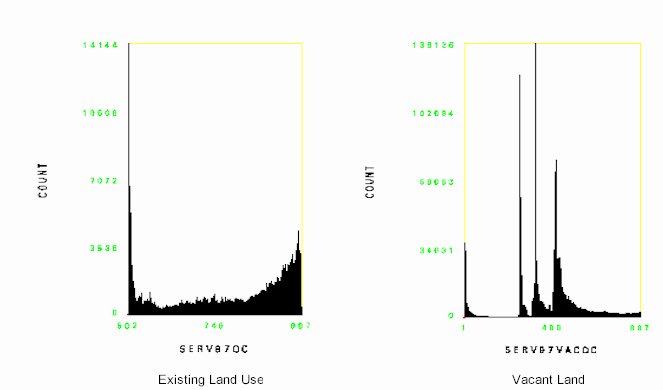
Data layer preparation is a time-consuming trial and error process. A data layer that is useless when prepared one way might be very useful when prepared in a different way. Testing the effect of different input data sets on the model output proved to be a unique challenge. After including a new data layer in the model and generating the output probability surface, two additional grids would be generated. One grid contained the part of the probability surface that intersected the existing land use type being modeled and the other grid contained the intersection of the probability surface with vacant land only. A histogram was then generated for each. The ideal existing land use histogram should have a decided slant towards the high probability values. The ideal vacant land histogram should be fairly flat or bell shaped with even amounts of high and low probability values. Comparing the changes in the histograms from iteration to iteration helped identify whether a change helped or hurt the model's predictive qualities. Below are examples of histograms for the commercial service probability surface.
|
|
We found the chi-square values generated from GRID's regression command to be of limited value since they summarized the total effect of all the input grids rather than being specific to each individual input grid. A third party statistical package could be used to alleviate this problem. Finally, department planners with domain expertise in local land use issues reviewed the model's output. Errors and mis-allocations were due largely to idiosyncratic circumstances pertaining to individual parcels and specific landowner issues and not to disagreements with the macro focus of the model.
Probability Surfaces
Our objective of using logistic regression to develop probability surfaces for a future point in time raised some additional issues. When input data reflecting current conditions, i.e., slope, current road network, etc., was utilized, the resulting probability surfaces that are applied to vacant land really only indicate how that land is likely to be developed under current circumstances. However, the desired 2020 predictions are dependent upon characteristics that will undergo substantial changes. In particular, the transportation system will be extended. A number of major road projects have already been planned and funded. One way to handle this situation might be to develop incremental probability surfaces. For example, surfaces developed on the basis of current conditions might be used for a land use allocation based on a two-year land demand forecast. The resulting projection would then be combined with existing land use data and used as the basis for another regression process, this time using input data forecasts for two years in the future. The cycle would be repeated up to the desired point in time.
Unfortunately, time constraints prevented us from taking this more comprehensive approach. Instead, two sets of probability surfaces were generated, one based on the current transportation system and the other based on available transportation plans for the year 2015. Current land use was sampled in both cases. Although we realized that it is problematic to generate regression coefficients in this way, we felt it was preferable to simply applying the coefficients developed from current conditions to the data representing 2015 conditions.
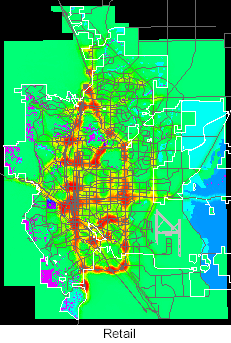
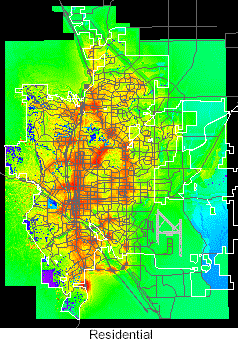
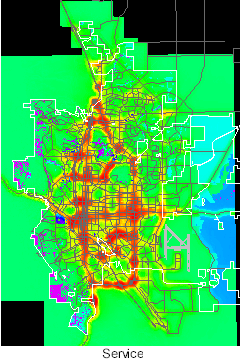
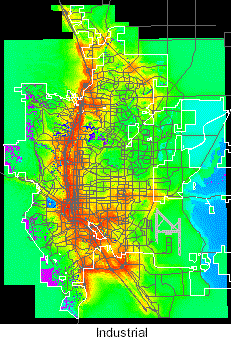
Once created, the two sets of probability surfaces served as platforms for various allocation scenarios and did not have to be reconstructed. Grids for the four land use types using transportation forecasts for 2015 are illustrated below. High probabilities are in red and yellow. The color shifts across the spectrum to blue and violet for low probabilities.
|
|
|
|
|
|
Allocation
The diagram illustrates the remaining phase of the modeling process. To compensate for known situations regarding future land use development, a set of grids was employed to customize the probability surfaces prior to allocation. For example, a large vacant parcel located near a major arterial was originally assigned a high probability for industrial development. However, it was also known that the owner of the parcel, an educational institution, would neither sell the land nor develop it in the predicted manner. By factoring this into the modifier grid, the probability values were reduced for cells associated with this parcel, thus ensuring that they would not be allocated for industrial use. Similarly, some large areas of vacant land adjacent to a highway, which according to the model would be candidates for commercial development, are in fact not likely to be developed at all due to the prohibitive costs for wastewater service. These areas were removed from any possibility for allocation. Planners identified as many of these types of circumstances as possible.
|
|
Allocation was accomplished primarily through INFO programming rather than by GRID processing. Some experimentation was done with focal functions and docell blocks to allocate cells dynamically. However, processing times were prohibitive, sometimes taking several days to run. Thus an approach was taken which allowed the allocation process to be completed in within an hour or two.
Each of the four probability grids store integer values between zero and 999. Through an iterative process, these grids are combined with a Planning Evaluation Zone (PEZ) grid, which contains values from 1-9. The resulting VAT contains a four-digit number, the first digit of which identifies the PEZ. The VAT from the combined grid is then copied to a separate INFO table for processing. A hierarchical approach is taken in which commercial retail cells are allocated first, followed by industrial, commercial service, and residential. This is accomplished by sorting the table so as to order the records by PEZ and by probability. Starting at the top of the table, which contains the record identifying the highest probability value for retail cells in PEZ #9, records are assigned to retail land use until the total number of cells allocated meets the land demand target figure for each PEZ. (In actual practice, the land demand figures were increased by approximately 15% to account for the additional right-of-way that needed to be allocated for mapping purposes and to account for some loss of acreage that occurs in a final smoothing routine.) These records are flagged and related back to the original VAT. A mask grid is created so that these cells cannot be reallocated. The process is then repeated for each remaining land use type. This procedure is performed on the grids derived from both the current input data and 2015 input data. The results are apportioned together, and used to construct a final output grid which stores the projected land use.
Scenarios
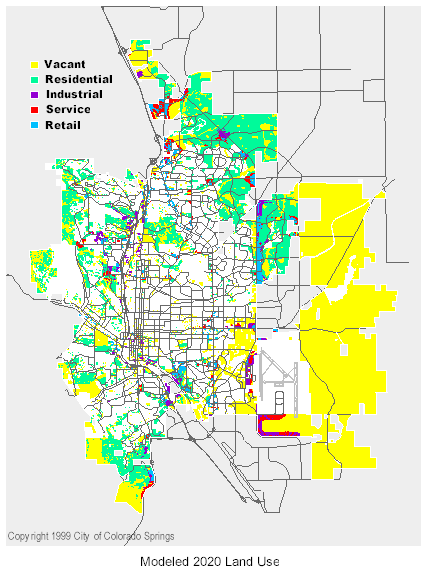
As mentioned previously, several scenarios have been developed. These include "no change" projections for 2020 and 2010 and "open space" projections for the same years. The 2010 projections were generated by scaling back the land demand figures and then applying them to the probability surfaces so that results are consistent with the 2020 results. The 2020 "no change" results are shown below.
|
|
An important aspect of being able to spatially allocate the land demand forecasts was the ability to re-aggregate the results according to other geographical boundaries. For example, after the "no change" future land use pattern had been fine-tuned and deemed acceptable, it was overlaid with Traffic Analysis Zones to provide inputs to a transportation modeling package. Similarly, an overlay was done with Census Tracts and the results utilized for City budget planning. While these tasks could have been accomplished in other ways, the process would have been far more labor-intensive.
Conclusions
The land use allocation model has been a useful tool in helping planning staff visualize future land use patterns and in providing information for the revision of the Comprehensive Plan. According to planners, a major benefit has been the time savings in the quick turn-around between "tuning" the model and examining the outcome. We expect to continue to use it in its current form for additional modeling, but offer these suggestions for enhancing its functionality:
It has been an exciting project, particularly so since GIS has not been typically utilized in this way for city planning purposes. We hope that this work has demonstrated the value that modeling with ARC/INFO and GRID can have for local government.
Acknowledgments
The Facilities Information Management System of the Colorado Springs Utilities and the El Paso County Assessor provided the high-quality spatial data that made this project possible. Also, the City's Comprehensive Planning Unit must be acknowledged for providing resources and support to what at first must have seemed like a rather questionable endeavor.
References
Batty, Michael. 1996. Visualizing Urban Dynamics. In Longly, Paul and Batty, Michael, (eds) Spatial analysis: Modeling in a GIS Environment. New York, GeoInformation International: 297-320.
Hammer, Siler, George, Associates. 1998. Technical Documentation: Land Development Projection Model Baseline Subarea Development Allocations. Unpublished report, City of Colorado Springs.
Landis, John D. 1995. Imagining Land Use Futures: Applying the California Urban Futures Model. Journal of the American Planning Association 61, 4: 438-457.
Landis, John D. 1997. Modeling Urban Land Use Change: The Next Generation of the California Urban Futures Model. Unpublished paper from Land Use Modeling Workshop, National Center for Geographic Information and Analysis, 1997 (www.ncgia.ucsb.edu/conf/landuse97/).
Sui, Daniel Z. 1997. The Syntax and Semantics of Urban Modeling: Versions vs. Visions. Unpublished paper (geog.tamu.edu/sui/research.htm).
Phil Friesen
Ben Lydon