Curtis White
Realistic models of municipal water distribution systems pose problems due to their size and complexity. Traditional approaches are to build and run system-wide models that are highly abstract (skeletonized), and more detailed, limited extent, independent models (e.g., single pressure zones). This compromise makes it impossible to assess detailed impacts in the context of overall system operation.
This paper discusses the use of hierarchical organization techniques implemented primarily with GIS tools and data structures that allow detailed models to be created and simulated within the context of a complete system-side model. A three level structure is used that allows considerable detail at the local level. This approach is being used at the City of Tucson's Water Department to allow investigation of water quality issues in detailed networks.
The models are built in conjunction with spatially accurate maps maintained with CAD (AutoCAD/ArcCAD) and GIS (ARC/INFO, ArcView, MapObjects) tools. Data structures are used to track the association of elements between hierarchical levels. This amounts to formalizing how elements at one level are aggregated into fewer elements at the next higher level. Appropriate attributes are maintained for modeling for elements at each level. The couplings, or connections, between model subsystems are critical in this approach as they define where a collection of model elements at one hierarchical level may be removed and replaced with a more detailed representation at the next lower hierarchical level.
The goal is to be able to "drill down" to the appropriate level of detail for the question at hand (water hydraulics or quality, extents of problem, time frame) and then have the model built automatically by various programs. The process of specifying where detailed structures are to be substituted in will be handled through an interface combining both data base and GIS technologies (MapObjects with Visual FoxPro 6.0). Examples of these interfaces will be presented as part of the paper.
The City of Tucson’s Water Department (Tucson Water) is in the process of converting existing map documents into CAD / GIS digital files, upgrading their current hydraulic water model from KYPIPE to EPANET / CYBERNET, and linking the model to these GIS maps. The first section of this paper, "Problem Description", will examine some of the objectives of this project and the approach taken. This section outlines the hierarchical approach to model construction that is being used and why this approach has been selected. Background information on the water utility and model components are also presented in this section.
The second section, "Spatial Structure of the Service Area", examines the current spatial extent of the water service area and how this is structured into Water Service Areas which are essentially discrete pressure zones. This structure is essential to the hierarchical model structure. The coarsest model level is termed the Regional Model and is analogous to the Department’s current "Skeletal" model. The spatial hierarchy is further developed to the Area, Local and Actual levels in this section.
The third section, "Supporting Data Structures and Schema", illustrates the types of data structures that are required to support the modeling effort. The design emphasizes how unique models are generated automatically depending on the type of question that is being asked.
The fourth section, "User Interface Design", examines some of the issues regarding the mechanics used to generate a specific model. The fifth and final section, "Sample Model Output", shows the results of a sample run made using the Area hierarchical level detail.
The Tucson Water "Hydraulic Model Mapping and Data Conversion" project has numerous objectives. These are primarily:
These objectives need to be discussed in order to make clear why a hierarchical approach to modeling has been selected. Further details on some of the theoretical issues are presented in White, Victory and Mulhern (1999) (see references). Before beginning this discussion, it is useful to present some facts about Tucson Water.
Tucson is located in southeastern Arizona. Tucson Water provides service to approximately 630,000 area residents. In 1998, the utility delivered approximately 32 billion gallons (100,000 acre feet) of water to over 175,000 customer accounts. The service area covers approximately 300 square miles. Potable and non-potable (reclaimed) water are delivered in separate systems which combined total about 550,000 components. For example, there are about 80,000 valves in the system.
Simulation models of water distribution systems are typically built to examine two primary areas: water hydraulics and water quality. The first concerns the ability to deliver a reliable amount of water at a fairly constant pressure and to meet certain contingencies (e.g., high water volumes at a high pressure for short time periods for fighting fires). The second concerns the ability to deliver a reliable quality of water for various objectives (e.g., maintaining chlorine or dissolved solids concentrations within certain prescribed boundaries). Water quality models are typically an extension of the more basic water hydraulics models.
When dealing with very large water systems, it is typically not possible to model an entire water delivery system at its finest level of detail (that is, including every existing pipe, valve, service line, and so forth). Certain simplifications are made to allow model implementation in a timely manner. The approach frequently taken is to construct a highly aggregated model of the entire water system (often called a "skeleton" model) and use this to look at general hydraulics and quality issues over the entire service area. Then more detailed models are built for individual pressure zones to examine hydraulics and quality issues within those zones.
However, these detailed models are run separately (uncoupled) from the overall model; inputs to the zone are taken from certain "driving" data sets, or the couplings to other zones are through storage facilities of some sort that are simply "drawn down" during the short simulation periods of the detailed models. In fact, many utilities will simply do "static" analysis of their water systems and not even conduct dynamic "extended period" simulations. That is, the start and stop time of the simulation is the same time; the state of the system is simply calculated so that the water pressure, for example, is known at all points, but how the pressure might change over time is not calculated.
Now it would be possible to create a detailed model of the entire water system (to some specified level of detail). It is not practical in large water systems to model each and every component. That is why the system is typically generalized and only the larger pipes are included in a model. The demand points (nodes) of the model do not represent individual services, but collections of services (groups of users). The usual problem is to decide to what extent water system components are to be aggregated. Coarse models (large aggregation) are very useful in determining overall system capabilities, but finer models (less aggregation) are necessary if questions at particular locations (e.g., neighborhoods) are to be answered. With the desired introduction of Central Arizona Project (CAP) water into the system, it is necessary to add water quality to the water hydraulic model and to be able to predict, at a specific level, what the water quality will be in particular locales.
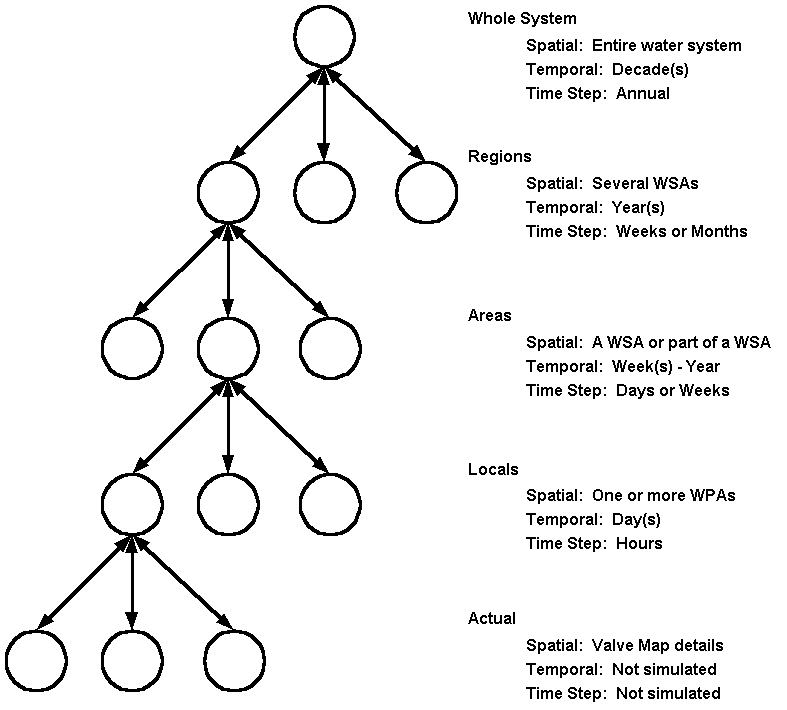
The hierarchical approach allows a coarse model of the entire water system to always be used. When greater detail is necessary to answer a particular question, then portions of the coarse model are removed and replaced with greater detail. When necessary, portions of this expanded model can be removed and replaced with even greater detail. The overall hierarchical model structure is shown in Figure 1 below.
Figure 1. The System and its Subsystems in the Context of a Regional Water System Network
At the "Whole System" level, we do not really have simulation model. It may be thought of as an accounting of the location and use of water at a gross level – how much is stored in what reservoir, how much is pumped from each well field, how much is used in total. This is more of an accounting system and can be tracked, for example, in a spreadsheet. There is no real effort made at this level to try to examine the spatial distribution of water movement or use.
At the Region level, coarse representations of the water network are created by aggregation. The major pipes of the system are present. Pumps are usually represented by booster stations (aggregated pumpage) and water sources are represented by clusters of wells. Only the larger storage facilities are typically represented.
At the Area level, much greater detail is introduced. Demand is spatially located much closer to the actual point of use (service). Smaller diameter pipes are represented. This elaboration continues at the Local level. Finally, the Actual level is the one at which all real components of the system are present. While this is mapped, it is not modeled (simulated).
General Systems Theory guarantees that we can make these hierarchical elaborations (substitutions) while maintaining overall system behavior. For example, if my neighbor turns on all of their water taps at one time, I may notice a slight drop in my water pressure. If many of my neighbors do this, I will definitely notice a change. But people that live on the other side of the City (20 miles away) will notice nothing. In fact, water systems are designed specifically to minimize this type of impact.
A further motivation for using the hierarchical approach is the cost of the CYBERNET licenses (EPANET is freely available). One advantage that CYBERNET has is that of displaying other information (such as parcel lines) along with the water network. Currently, Tucson Water’s licensing only allows for the construction of models having 5,000 or fewer links. The hierarchical approach allows construction of detailed models that, within a limited geographic region, are always linked and simulated within the context of the entire system.
Before examining the spatial structure of the water service area, the simulation model requirements need to be briefly introduced. EPANET / CYBERNET use two primary model element types. These two types are represented by specific model elements. Briefly, these are:
Links (linear features):
Nodes (point features):
All links connect between nodes. Not all junction nodes may actually have a demand; they may simply be a connection between two pipes). Reservoirs, in model terms, are large water bodies which never have their surface level change. None of Tucson Water’s reservoirs are actually this big (they all have some fluctuation in their water level). Wells can be modeled this way, however, as we do not look at groundwater effects with these hydraulic models (i.e., well production is a driving data set of the model).
EPANET / CYBERNET is a state-variable model. As such, it has certain data required in order to make a simulation run. These requirements may be summarized as:
The spatial locations of these various elements are stored in the GIS map. It is convenient to also store the (x,y) coordinates of the point features in the data tables at times. Further discussions on the data are presented in the "Supporting Data Structures and Schema" below.
One way of thinking of hierarchies is as nested "Chinese" boxes. In the case of the utility, the image is one of nested service area polygons. Figure 2 shows the Tucson Water Service Area, both currently and its projected extent in 50 years.
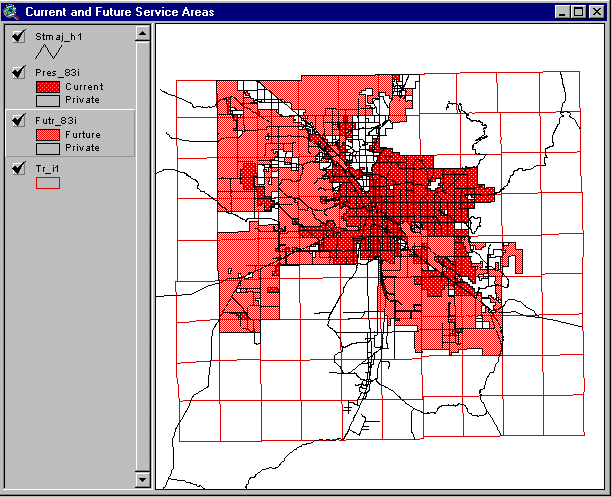
Figure 2. Tucson Water Service Area – Current and 50 Year Potential Extent
At present, there are certain isolated portions of the system that are not connected to the main network (these are modeled in isolation). To give some idea of the maps scale, each of the red boxes is a Township. Major roads are shown in black. The service area extends outside of the city limits in many places, and there are portions within the City that are serviced by private water companies. The solid red area (the service area) can be thought of as the first hierarchical level, the entire system.
The second hierarchical level, the Region, is roughly analogous to the pressure zones. These are shown in Figure 3.
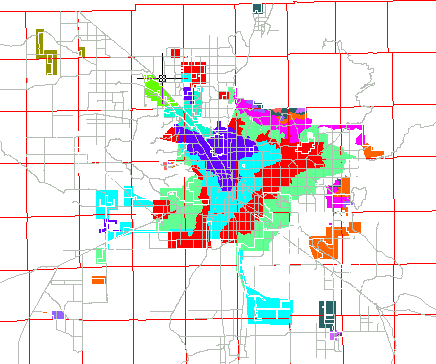
Figure 3. Water Pressure Zones by Area
Comparing this with Figure 2 will show that we have "zoomed" in to the current actual service area. At the Region hierarchical level, it is sometimes convenient to "group" or aggregate some of the smaller zones into one. At the Area hierarchical level, the pressure zone boundaries are never crossed; some of the larger pressure zones will be divided into more than one area at convenient locations (i.e., where there is a minimal amount of network coupling).
However, what is being modeled (simulated) is a linear network, not a polygonal area! Figure 4 shows the same Water Pressure Zones in the context of the skeletal (Region) pipe network. This is not the actual Region hierarchical level pipe network, but a simplification of it. It does demonstrate the interconnection between the pipes of the different pressure zones. Only large pipes are shown here; no other network (or model) features (such as pumps, storage facilities, etc.) are shown.
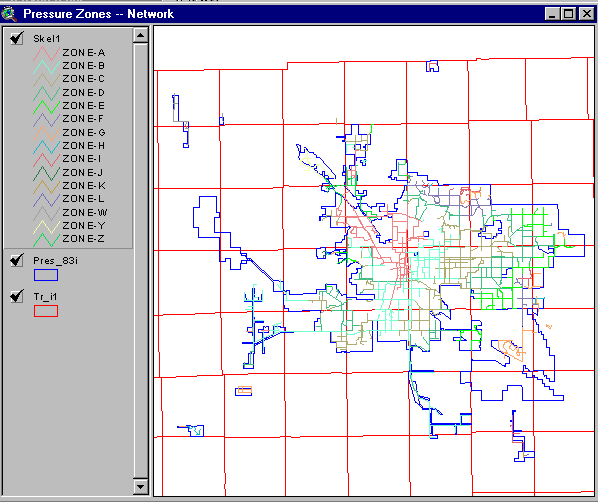
Figure 4. Water Pressure Zones by Skeletal Pipe Network
In order to see the next hierarchical level, it is necessary to "zoom" in to a particular locality. This is shown in Figure 5. Here the depicted skeletal (Region) model is shown in comparison with the real (Actual) pipe network in one Township. This illustrates the type of aggregation that takes place between the finest and coarsest levels of the hierarchy.
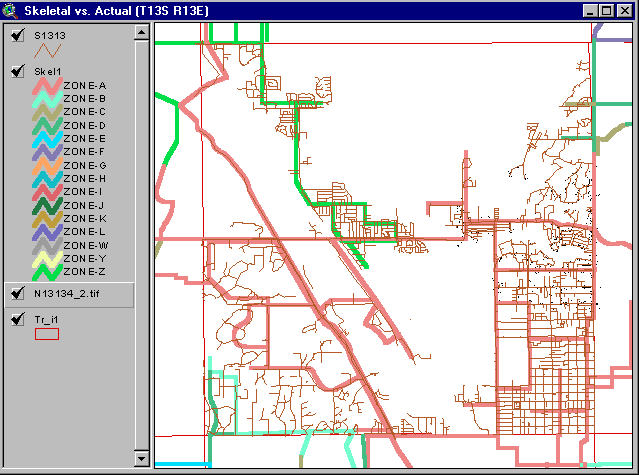
Figure 5. Skeletal Network Compared to Actual Network
Even at this scale, it can be seen how the current skeletal model differs in spatial location from the real network. Creating this model from the real-world features meets the objective of aligning the model with the County basemap data. In other words, the skeletal model is not modified; it is recreated from the accurately mapped water system network.
In order to see the next hierarchical level, it is necessary to "zoom" in to a particular locality. This is shown in Figure 6 (the area of the zoom is in the middle right of the view displayed in Figure 5). The thick colored line running across the middle of this Figure is a portion of the skeletal (Region) model. The fine colored lines are the (Actual) water network. The black lines are the Area model, with the circles being demand nodes (junctions).
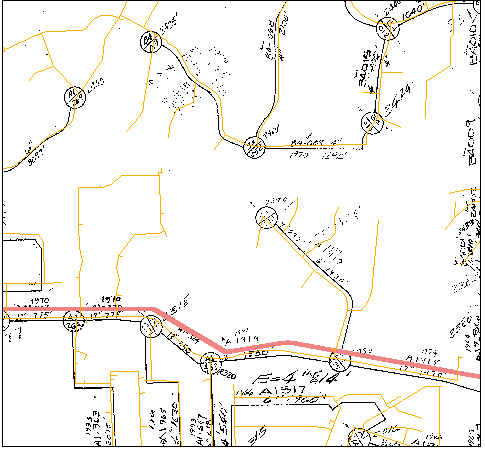
Figure 6. Region, Area and Actual Networks
The data depicted in Figure 6 comes from three different sources and illustrates the spatial inconsistencies in the various data sets. The real-world (Actual) network features are spatially accurate (to the extent that they are consistent with the features in the County basemap data). The Area model displayed is from a georeferenced scanned image of the current Water Service Area model (this is the detailed model for a single pressure zone). While not exact, its features show fairly close agreement with the placement of the Actual network features. The single skeletal (Region) model feature shows the greatest discrepancy from Actual (and Area) network feature locations. Again, all model hierarchical levels (Region, Area, and Local) become spatially correct because the model generation process derives them from the Actual water network.
In applying GIS technology to simulation models, in general, the typical approach is to utilize the GIS to maintain the necessary data sets (parameter and initial condition values) required by a model. Various tools (programs, scripts) are developed that allow input data sets to be written for an external model, and then to import and display the results of the actual model simulation runs within the GIS. (For example, see McLeroy, R. J. [1994]). Certain types of models (particularly cellular automata) lend themselves to implementation within a GIS (e.g., wildfire simulations – see Liu and Chou [1997]). Even when it might be possible to rewrite a model strictly within a GIS, it might not be desirable. Certain models are certified or required by the Federal or State governments, or their output is recognized as a standard within an industry. The EPANET water distribution system model is within this class (a standard).
The approach taken here is slightly different. In the process of creating input files for the EPANET (or CYBERNET) simulation engine written, the actual model structure is also created. That is, there is not just one configuration of pipes that is being maintained and simulated. Rather, a unique model network is created "on the fly" depending on the type of question being asked and the level of detail required for that question. (How this will be done is discussed in more detail in the "User Interface Design" section below).
In order to do this, certain information must be stored in a Relational Data Base Management System (RDBMS). Obviously, those data elements stored in Esri Feature Attribute Tables (e.g., PATs and AATs) must follow the rules of those tables. In order to keep these simple, the primary item (field) that is added to each Feature Attribute Table is an appropriate unique identifier; the "USER-ID" item (field) is not used since it is an integer field, and typical identifiers used by the utility incorporate alpha characters. A few additional fields are added as convenient to symbolize the spatial features. Most of the model data is stored in independent tables. At each hierarchical level the same type of tables are maintained. Figure 7 shows the basic data structure for the real-world (Actual) network.
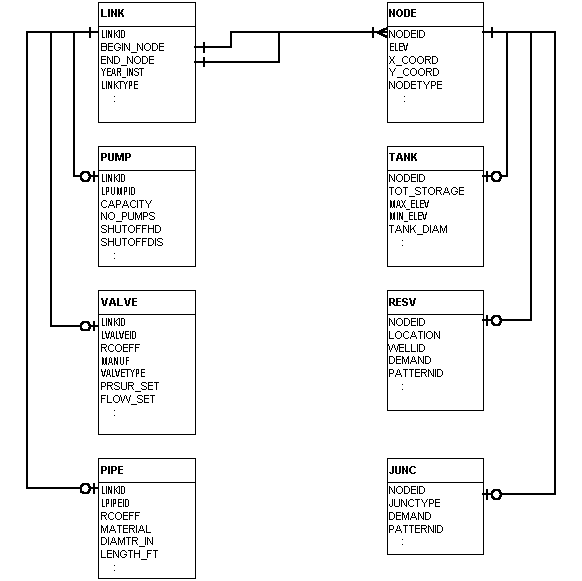
Figure 7. Basic Data Structure – "Actual Network Elements
All attributes for each data table are not shown in this Figure. Part of the data base design effort is based on an object-oriented modeling and design approach (for a good introduction, see Rumbaugh, et al [1991]). In essence, the link object is the superclass of the pump (booster), valve and pipe classes. A link object is never instantiated; only its subclasses (e.g., a pipe) have objects instantiated (actually created and used in the model). The same holds true for the superclass node and its subclasses tank, reservoir and junction.
Applying object-oriented methodology means that attributes at the superclass level should be carried in a separate data table from the attributes specific to the subclass level. This is, operationally, identical with standard data base normalization. Thus, all links have a begin and end node and so that information is carried in the LINK table. The field LINKID is the primary key that allows each subclass table to be related back to the superclass table. Note that the relationship from subclass to superclass is one-to-one (1:1), but from the superclass to the subclass it is one-to-optional (1:0 or 1).
Each link can be of only one subtype so that if a link is assigned to the pipe it cannot be assigned to being a pump or valve. That is, the subclasses partition the superclass exactly. All links must be either a pump, valve or pipe, and the union of all pumps, valves and pipes is equal to the set of all links. The same holds true for the superclass nodes and its subclasses.
The two primary model component types are relatable by the node identifier (NODEID). Each link stores its begin and end node’s identifier. This can then be used to establish a relationship between the LINK and NODE tables. While each link explicitly knows the nodes it is associated with, it requires some processing to create a list of all links for a particular node. The relationship from the LINK to NODE table for one of the fields (e.g., BEGIN_NODE) is one-to-one (1:1). That is each node must be in the NODE table. The relationship from the NODE to LINK table is one-to-many (zero or more) (1:0+) for each field. That is, each node identifier may appear more than once in one field (e.g., BEGIN_NODE) or not at all.
As mentioned, this data structure is repeated at each hierarchical level. Thus, there is the LINK table for the Actual hierarchical level, LLINK for the Local level, ALINK for the Area level and RLINK for the Regional level. Each table stores information that is relevant to it. Thus, the PIPE table stores the actual pipe length (derived from as-built plans) while APIPE stores the modeled feature’s length. Also, since the Area pipe is an aggregation of many pipes, such attributes such as diameter may differ from the Actual pipes that are aggregated which may differ in diameter. The relationship between hierarchical levels is shown in Figure 8.
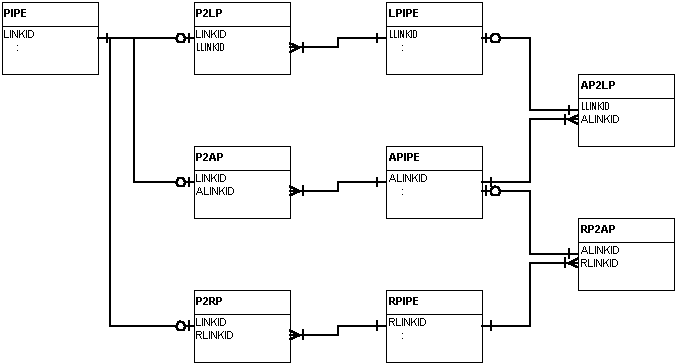
Figure 8. Hierarchical Relationships -- Pipes
Each pipe table carries an identifier that allows them to be related. These need not be, and are not, the same value. A separate table carries the relationship between the layers. Again, this is based on object-oriented modeling and design methodology. The association between features is a separate object and thus requires separate data storage. The relationship from LPIPE to P2LP, for example, is one-to-one-or-more (1:1+). Each Local pipe must be based on at least one Actual pipe, but will usually be based on several. The relationship between PIPE and P2LP is one-to-optional (zero or one) (1:0 or 1). That is, a Local pipe may be associated with a Local pipe or it may not be associated with any Local pipe (not aggregated). If it is associated with one, it can only be associated with that one and no more (e.g., it cannot be aggregated into two separate pipes).
The relationship between hierarchical levels is also shown in Figure 8. It follows the same pattern as that just discussed. Only Local pipes can be aggregated into Area pipes. If an Actual pipe does not get aggregated to the Local level, it cannot be aggregated into any higher level. Another way of saying this is that Regional pipes can only be aggregated from Area pipes, which can only be aggregated from Local pipes, which can only be aggregated from Actual pipes. New links or nodes cannot be created at any hierarchical level; they must have existed at the next lower level.
One of the reasons for treating the table associations as separate objects is that this allows them to have unique attributes. For example, in aggregating nodes from the Area to the Region hierarchical level, the Region node must be located at one (and only one) Area node. This node can be tracked by a separate attribute (field) in either the ANODE table or the RN2AN (the Region node to Area node) association table. And each association (relation) can be given a unique identifier. This allows the hierarchical relationship to be visualized as is shown in Figure 9.
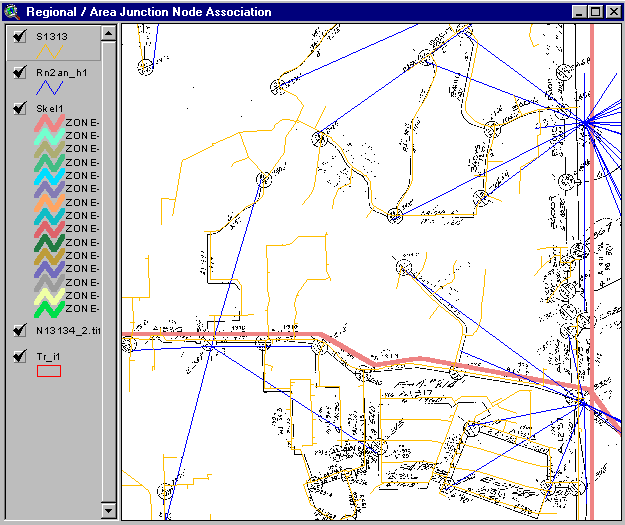
Figure 9. Hierarchical Relationships – Region to Area Junctions
This Figure shows the RN2AN (Region node to Area node) association table information. It covers about the same area and information as that in Figure 6, but the additional blue lines indicate which Area nodes are being aggregated into a particular Region node. The center of each "star burst" is the location of that Area node which is also a Region node. Each of the node (point) model component type associations may be represented in such "star burst" diagrams. The corresponding association of link (line) model components yields colored line diagrams, with each set of links at the lower (e.g., Area) level having a particular color while being labeled with the identifier of the higher (e.g., Region) level.
The ability to visually inspect the data table relationships is a key advantage of using a GIS, yet it is seldom (if ever) used judging from my almost 15 years of GIS experience.
This section presents a brief discussion on some of the issues involved in designing the user interface for actual model construction. The primary selection screen shows the Regions as polygons; the underlying pipe network is not shown. By default, all Region features (pipes, etc.) are used in the model. If the user simply wishes to run the current skeletal (Region) model, no further selection is necessary. A button is provided to construct the model. A dialog box will gather the pertinent information (user identifier, base file name, etc.) required and the model is constructed.
Model construction is twofold. The first output is an EPANET input file, which is simply a text file with the appropriate information in it. An optional input file allows the entry of node coordinates so that the model results can be displayed spatially; this file is also generated, but requires little more than listing the (x,y) coordinates of each of the model’s nodes.
The second output is a set of shape files, one for each model component type (e.g., pipes, valves, etc.) that can then be imported into CYBERNET running in AutoCAD. The attribute tables of each shape file have a pre-defined format (by CYBERNET) which includes the field names and types of values that must be included. These are constructed from the relevant data tables described in the preceding section.
The interesting action occurs when the user wishes to "drill-down" to include a finer level of detail. A tool is used to pick the Region that is to be elaborated. The general rule is that one, and only one, Region will be selected so that picking any one Region will deselect any other that might be chosen. The Area polygons within that Region are then displayed. If the user wishes to "drill-down" another level, then the same tool is used to select one (and only one) Area within the Region. The Local polygons within that Area are then displayed.
Selecting the model construction button now has a slightly different impact. Initially all features at the Region hierarchical level are marked for selection (inclusion in the model) within the data base tables. When Area polygons have been displayed, then the Region features within that Region are unmarked and the Area features within those Area polygons are marked. This is done by straightforward data table manipulations (the Area identifiers are part of the feature identifiers, e.g., pipes in the "A1" Area have "A1" as their first two characters); no GIS spatial operations (e.g., line in polygon selection) are required.
Similarly, if an Area has been elaborated to the Local level, then the Area features within that Area are unmarked and the Local features in those Local polygons are marked.
The process of building a model essentially pulls the selected (marked) features out of the Actual data tables (and spatial data sets) by transferring the mark down to the Actual table level. All marked features are extracted. Linear features are then aggregated into a single line (arc) by removing all intermediate breaks. At present, this is planned to be accomplished in AutoCad Map / ArcCAD using a combination of their respective commands. Appropriate information is transferred from the data tables into the shape file attribute tables (for CYBERNET input) and written to a text file (for EPANET input).
There are certain advantages and disadvantages to using each of the model simulation engines. There is no way to avoid doing certain manual input of information into CYBERNET simply because its Scenario Manager, which is used to construct the actual simulation run, is not exposed to outside manipulation. Conversely, EPANET offers no such metadata manager, so one must be constructed.
Current plans are to prototype the user interface design in ArcView and then put it into production using MapObjects inside Visual FoxPro v6.0. The current data base schema is implemented in Visual FoxPro with plans to migrate it to SQL Server (currently the utility is using v6.5). This allows the interface to remain in Visual FoxPro. Data conversion is greatly simplified using the upgrade wizard provided as part of the Visual Studio software package.
This is a very brief overview of the planned user interface. Additional needs not discussed are the requirements of specifying the length of the simulation run (static or extended period), the type of demand curves (driving data sets) that are to be used, the inclusion of water quality simulation (if desired), and a number of other items.
Once the model has been constructed, then the actual simulation run may be made. With EPANET v1.1e, this requires that the program be invoked and the input data sets loaded. The simulation run is then made. Results may be printed (e.g., water pressure at selected nodes) or viewed graphically if the optional (x,y) coordinate information has been created. A typical graphical view is shown in Figure 10.
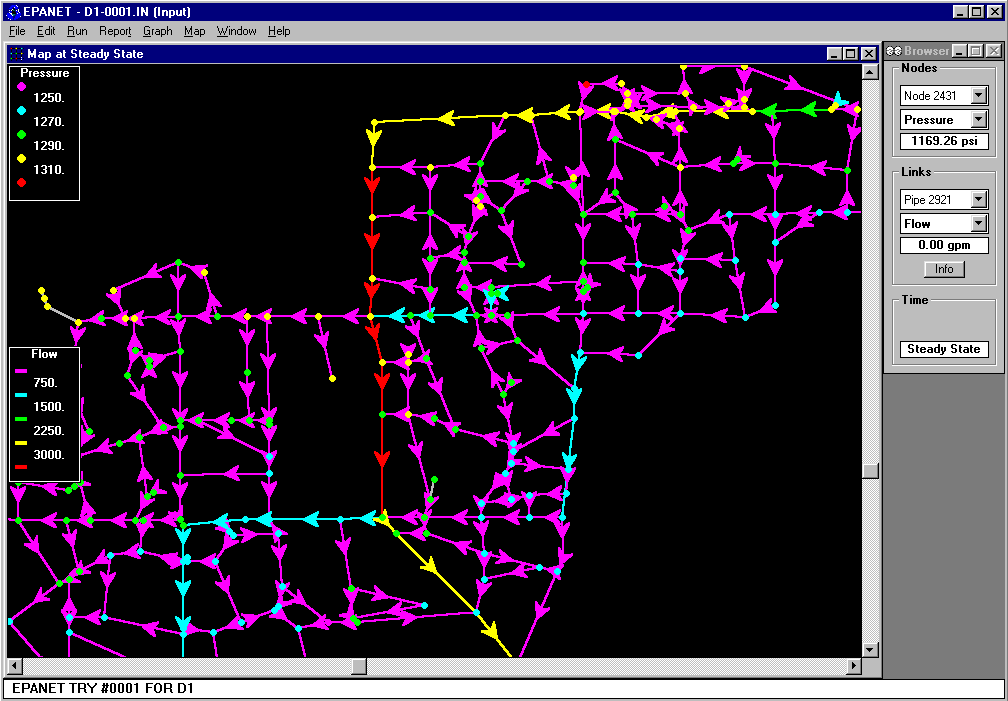
Figure 10. Sample EPANET Model Output – Pressures and Flows
Note that all pipes (the predominant link model component in the Figure) are straight lines that run between the nodes. Specific information about any node or link can be obtained by clicking on that particular feature to get the state variable value of interest (selectable from the pull-down list in the appropriate section of the Browser window).
The primary difference between this type of view and the one afforded by CYBERNET is that the link (e.g., pipe) shape corresponds to its actual mapped shape. In addition, since CYBERNET runs inside of AutoCAD, additional basemap (background) data, such as parcel boundaries or street centerlines, may be displayed to help orient the viewer.
One of the key decisions that must be made is how to deliver the results of model simulation runs to users other than the modelers. These engineers have access to EPANET and CYBERNET for examining the results of simulations. For others (e.g., planners, managers, hydrologists, maintenance staff, etc.) a more general method must be used. At this time, the plan is to deliver such results over the utility’s Intranet using one of the Internet Map Server technologies provided by Esri.
Initially, it was planned to prototype the delivery visualization tool using ArcView IMS and then put it into production using MapObjects IMS. This is currently being reviewed with the imminent release of the new ArcIMS product.
Various company names and their software programs referred to herein are copyright or trademarks of their respective organizations.
CYBERNET User Guide version 3.0 (1997). Haestad Methods, Inc., Waterbury, CT.
Liu, P. S. and Y. H. Chou (1997). "A Grid Automation of Wildfire Growth Simulation." Proc. 1997 Esri User Conference, San Diego, CA.
McLeroy, R. J. (1994). "Linking AM/FM/GIS with Work Order Management and Hydrualic Analysis Models." Proc., AM/FM Int. Annual Conf. XVII, Denver, CO, 374-383.
Rossman, L. A. (1994). EPANET Users Manual v1.1, Risk Reduction Engineering Laboratory, Office of Research and Development, U. S. Environmental Protection Agency, Cincinnati, OH.
Rumbaugh, J., M. Blaha, W. Premerlani, F. Eddy and W. Lorensen (1991). Object-Oriented Modeling and Design, Prentice Hall, Inc., Englewood Cliffs, NJ.
White, C., T. F. Victory and L. Mulhern (1999). "Using Hierarchical Organization to Reduce Complexity in Water Distribution System Simulation Models", Proc. of the 26th Annual Water Resources Planning and Management Conf. (Amer. Soc. of Civil Eng.), Tempe, AZ.
Curtis White, President
Global Systems Modeling Ltd.
P.O. Box 36221
Tucson, AZ 85740
(520) 575-8636
cwhite@primenet.com