Tangled in the Web: Procedures for Managing Web-based Projects
David M. Theobald1, Chris Johnson2, James Zack3, Tammy Bearly1, and Tom Hobbs1,2
1Natural Resource Ecology Lab, Colorado State University
2Habitat Section, Colorado Division of Wildlife
3Geomega, Boulder, Colorado
Abstract
The web provides a powerful means of disseminating spatial information, but managing and updating web-based applications can be a complex and time-consuming process. Managing a web-based application typically requires maintaining and updating different versions of Avenue scripts, AV extensions, HTML files, Java code, and spatial data. To simplify the inevitable complexity of web-based projects, we have developed a number of procedures to help manage ArcView IMS projects. We discuss issues such as maintenance of working and serving projects, reduction of script proliferation and redundancy by building extensions, addressing the numerous details prior to serving a project, and working within a team-development environment.
Introduction
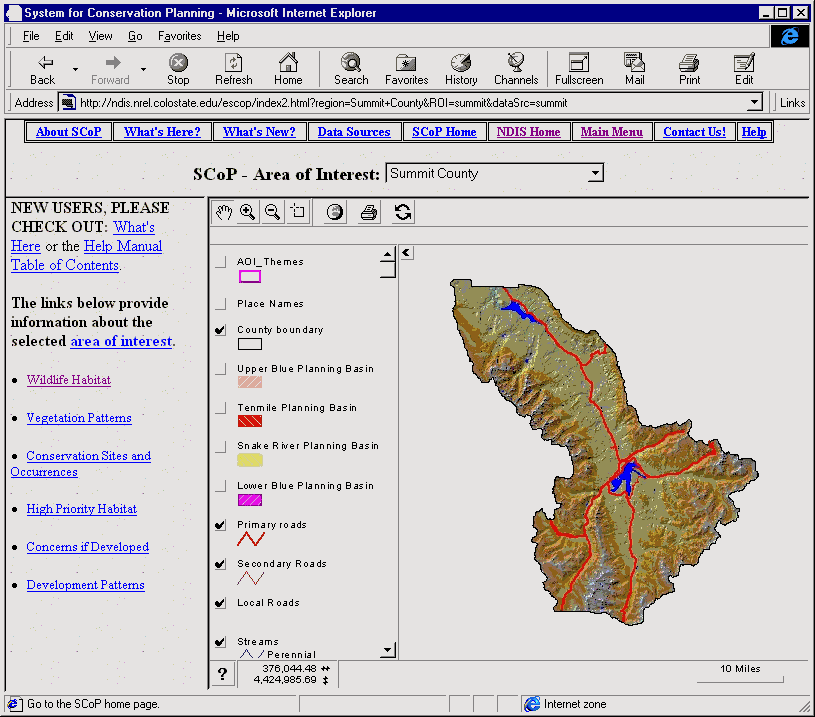
The Colorado Natural Diversity Information Source (NDIS) is a project that aims to inform Colorado residents, decision makers, planners, and professionals about their wildlife and plant resources. This information is aimed to improve local land use planning and decision making. The core of the NDIS project is the System for Conservation Planning (SCoP) (Figure 1). SCoP is a GIS-based decision support system that utilizes spatial data and analyses fine-tuned to provide a scientific, rationale basis for understanding the potential effects of residential development on wildlife habitat in Colorado (Hobbs et al. 1997; Theobald et al. 2000). Typical queries of NDIS and SCoP users follow the two classic GIS questions--"what is here?" and "where do such-and-such conditions exist?" That is, our users want to know what wildlife is found in a particular location and where are the hot spots of biological richness. Because the data is fundamentally spatial in nature, maps are the principal format for delivery of this information, but we also provide information in other forms as well: tables of statistics, lists of species, pictures, and documentation.
We began development of the NDIS web-site using ArcView Internet Map Server v1.0 about 3 years ago. We quickly found that the requirements of the application forced us to develop functionality beyond the out-of-the-box IMS. Over time, the project has evolved and currently is programmed using Avenue, JavaScript, Java, HTML, and Microsoft's Active Server Pages (ASP). We described the interactions among these components in a paper we presented at last year's conference (Bearly et al. 1998).
More recently, we have found that an unfortunate consequence of the natural growth and evolution of this application is a considerable increase in the difficulty of updating, modifying, and maintaining our application. In this paper we describe both the causes for the increase in complexity and some of our responses to reduce the difficulty of managing projects served on the web.
Why do applications become complex and difficult to manage?
Customization
The requirements of our users meant that we needed to develop functionality to support full interaction with the application beyond that available in out-of-the-box ArcView IMS. To achieve this functionality, we have used 5 languages to program the application: Avenue, HTML, JavaScript, Java, and ASP.
The application is primarily written in Avenue, which provides great flexibility and power to customize analysis and queries. Because much of the information available on our website is tied to maps, the raw data is stored primarily in theme attribute tables. These data are used to dynamically generate HTML pages to display maps, tables, and even menus, through which the user accesses various components of the system. Furthermore, Avenue is used as the "glue" between the various databases and different program routines.
The user navigates through the application primarily through HTML pages. Also, many of the queries and map requests result in HTML pages or tables.
JavaScript is used to add functionality to the HTML pages. An important use is to track and maintain a client's Area of Interest (AOI), while at the same time maintaining statelessness. This is accomplished by passing and storing in a client-side HTML frame (via JavaScript global variables) the spatial extent of the AOI and the name of a temporary directory created on and by the server to store client-specific tables and themes. Without this function, it would be impossible to allow different users to be simultaneously accessing the system. Another valuable JavaScript function is the ability to pass a user�s selection from an HTML list of species back to IMS and the Esrimap.dll. We pass the selection variable to return textual, statistical or spatial data specific to the user's selection. Finally, we use JavaScript to dynamically create "user-friendly" HTML pages with preset window sizes and GUI configurations. This allows us to maximize screen "real estate" by excluding browser buttons and menus to satisfy users that have small monitors.
We extended the MapCafe classes using a Java method to allow a user-defined tool to be placed on the MapCafe toolbar. The Java program allows the user to draw a rectangle on the screen and display the rectangle as it is defined. The MapCafe Applet starts the process when the user selects the user-defined area button from the MapCafe toolbar. The applet then calls a Java function to retrieve the extent of the user-defined area, then calls an Avenue script and specifies which HTML frame to write to, then Avenue writes HTML code to store the extent in a client-side HTML frame.
Microsoft�s Active Server Pages have also been used to protect sensitive data code from potential marauders. Although similar to JavaScript, ASP is a server-side technology rather than client-side. For developers, this means code can be hidden from clients with only the resulting HTML being viewable. ASP provides a fairly easy way to create NT CGI programs such as password protection, HTML form processing, and user-specific dynamic HTML.
One of the most important causes of complexity is that the scope of variables is different for each programming language. For example, in an Avenue script that writes a Dynamic HTML document, tokens can be either JavaScript variables or Avenue variables. A given variable may have its value set when the code executes or may merely be declared and ready to have its value assigned through some user interaction. The programmer(s) must be diligent to ensure that variables are used in the proper context. Another source of tedium is the building of a line of JavaScript code that contains string concatenation using Avenue variables as string constants. Single-quotes and double-quotes must be used appropriately or the code will not execute and may even crash the application.
Another challenge that makes our application more complicated is that we need to support different browser technology, primarily MS Internet Explorer and Netscape. The most significant differences are: 1) the unique caching mechanisms available in each browser, and 2) the two methods for compressing and delivering Java bytecode (ZIP vs. CAB files).
Multiple skills
Application requirements have driven the need to use many different programming languages, and thus our development team has had to develop a broader skill set than those needed for typical GIS applications and projects. In addition to developing expertise in Avenue, HTML, JavaScript, Java (which is considerable enough), we have found that a number of additional skills are needed, by either project personnel dabbling, getting help from buddies or support staff, or, in some cases, conferring with consultants.
One of the most important skills to acquire is systems administration. Due to the rapid pace at which web development occurs, combined with the specialized GIS focus, it is unrealistic to expect the needed attention from a System Administrator who serves an entire company. Therefore, if falls to someone on the development team to learn how to configure networks, set up and maintain virtual directories (e.g., FTP and HTML directories), add and manage offsite user permissions (security issues), and "tune" server software using parameters such as thresholds on hits, time-outs, bandwidth and router infrastructure. Furthermore, general web design skills are needed, both in graphic layout, but also in technical issues such as knowing transfer speeds of different graphic formats, nuances in different browsers and versions, network behavior, etc.
Team development
Because many skill sets are needed, development tasks have been assigned (or assumed) based on whether personnel are on-site or telecommute, as well as by areas of expertise. Such a team approach creates its own set of challenges. Technical issues such as hardware limitations are relatively easy to overcome (within budget constraints), however network speeds and bandwidth problems can at times only be solved with an appropriate work around. Version control is difficult when the same script requires modifications by multiple programmers working on separate tasks. A primary limitation to team development is that testing a served project can only be accomplished by having someone directly at the server terminal. This makes testing the modified script a challenge because the person inserting the new script into the project is frequently not the developer of the script and therefore isn't well suited to adequately test the correct behavior of the script. Lastly, analysis of web log files is necessary both to justify the application itself, and to guide the development of future versions of it.
One workaround is for offsite team members to have "mirror" sites on their local workstations and use Microsoft�s Personal Web Server technology to validate their code changes on this "mirror" site. Validated code changes could then be FTP�d to the SCoP server and propagated into the served version of the application. This approach runs into problems of data/code concurrency, however.
Working/serving version
Assuming that you have now got your application up and serving, take a deep breath -- but not too deep. In most work situations, the next version of the application or updates to the application will be required. Rather than coming in to work during times of low use (e.g., midnight) to update the serving version, we have opted to maintain a "working" version of the application. The working version is installed on a separate machine because frequent reboots needed during development of the working version will bring down the served application. Although this gives us the freedom to modify and test new code at will, it compounds the difficulty of controlling versions. Tracking code changes and fixes with a working-serving configuration involves numerous stages of modifications and testing between machines, as well as coordination between multiple programmers. This is similar to the problem of data/code concurrency addressed in the previous section.
Data updating
One of our main reasons for maintaining a GIS web-site was to enable us to easily display the most current data. So, if data updating is difficult, a primary advantage of the web-site may not be realized. Although many GIS initiatives rely on "clean" data from numerous sources, this issue is more important to projects with highly-customized Web-based applications. Data that have unexpected or missing values, or even fields with different names, can cause an entire web-site to crash. Therefore data must be rigorously tested for quality and uniformity.
In order to provide adequate response time over the Internet, we have found it necessary to "can" or prepare some common user queries, particularly those that are time-consuming. The downside of this approach, however, becomes painfully apparent when the application must be updated. One minor change in a primary data set could very easily ripple through all of the canned data sets, requiring them to be re-created at each update cycle. For this reason, we recommend that "canning" should be avoided, but if needed, then data creation procedures should be well-documented.
How we reduced complexity to maintain our sanity
Extension
We decided to package the 34 customized scripts into an ArcView extension to simplify the distribution process both onsite between the "working" version and the "online" version, and offsite between programmers. We have also found that it is much easier to track temporary changes in the project file when there are only a few local scripts rather than all 34 scripts. Furthermore, we have served three different projects that require the same functionality, so using the extension maintains consistency among them. For each extension version, we generate a brief description of the changes made.
Procedure
One of the most important means of managing the complexity, which actually took us a long time to realize, was to establish a procedure to methodically make changes to the on-line application. This method is needed because when a client hits the site, the serving project temporarily changes in response to the user's request. For example, if a user zooms in to an area, then the view's extent gets modified to the user's extent. If you stop serving the project before the project resets itself to "stateless" mode, then the state of the project may not be as assumed. So, if a change needs to be made to a serving project, then we:
Debugging
We have found it helpful to track the execution of scripts for debugging purposes. ArcView automatically tracks just EsriMAP.DLL hits. We modified the Error routine to write so that errors were written to our own log file. Furthermore, each error message is time-stamped and contains the project name from which it was generated. Unfortunately, we were unable to redirect ArcView run time errors to this log file -- these errors are written to the nd.dbg file in the current ArcView working directory instead. A further challenge is to track web-hits on dynamically-generated HTML pages (which is not possible with conventional Web log file analyses), not only to track errors but also to track what parts of the application are being used.
Because of the numerous details that must be specified in the serving project, we created a script that runs at project start-up that sets variables and checks for appropriate set up conditions. In particular, the script:
Documentation
It has been wisely said that you can never document your work enough. We have found that good documentation is especially important when working on team projects, complex projects, projects that last longer than a few months, and projects that involve a change in personnel -- all of which describe our situation (and virtually any other). We have produced documention on: procedure calls (Figure 2), data flow (Figure 3), data dictionary (Table 1), and variable tracking.
Data updating
Data updating is probably the most underestimated challenge for GIS project management. In the initial stages of a project, simply getting the application to work correctly is all consuming. If the project is successful, eventually the data will need to be updated and the application will need to be modified and/or improved. One of the biggest challenges of updating data is simply ensuring its quality and conformity with what your application requires. During our quarterly to semi-annual update cycle we examine each new data set to identify:
Perhaps more importantly, though, is to design the project from the outset to minimize updating difficulties. Unfortunately, many of the solutions required by the application compromise the ability to update efficiently. For example, recall our earlier discussion on the need for "canning" data sets to increase application performance. Each processing step required for data to be used in the application compounds the updating headaches. One method we used to reduce these problems was to identify both the data that are most frequently updated and the data that are most dependent on other data. For example, in Figure 3 the "ROI Statistics" table stands out as the data set most dependent on other data. Because these must be re-created with virtually any change in data, we are making efforts to reduce or eliminate our use of static statistic tables.
Conclusion
We conclude this paper by listing a number of general rules of thumb:
References
Bearly, T., Theobald, D., Hobbs, T., and Zack, J. 1998. Disseminating natural diversity information using ArcView IMS: Design issues and technical considerations. Proceedings of the Esri User Conference '98. (http://www.Esri.com/library/userconf/proc98/proceed/tO200/pap184/p184.HTM)
Hobbs, N.T., D.M. Theobald, J.A. Zack, T. Bearly, W.E. Riebsame, T. Shenk. 1997. Forecasting Impacts of Land Use Change on Wildlife Habitat: Collaborative Development of an Interactive GIS for Conservation Planning. (http://ndis.nrel.colostate.edu/escop/SCoPwww.html)
Theobald, D.M., N.T. Hobbs, T. Bearly, J. Zack, T. Shenk, and W.E. Riebsame (in review). Incorporating biological information into local land-use decision making: Designing a system for conservation planning. Landscape Ecology.
Figure 1. The System for Conservation Planning application.
Figure 2. Example of programming document for the User-Defined MapCafé Button.
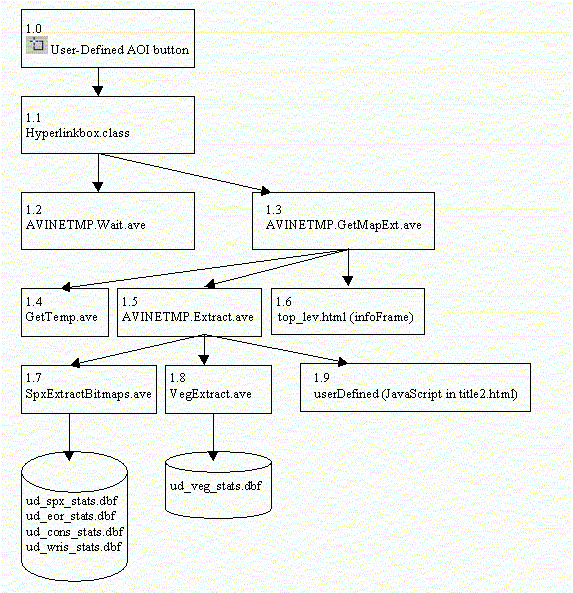
Figure 3. Documentation on data flow/updating.
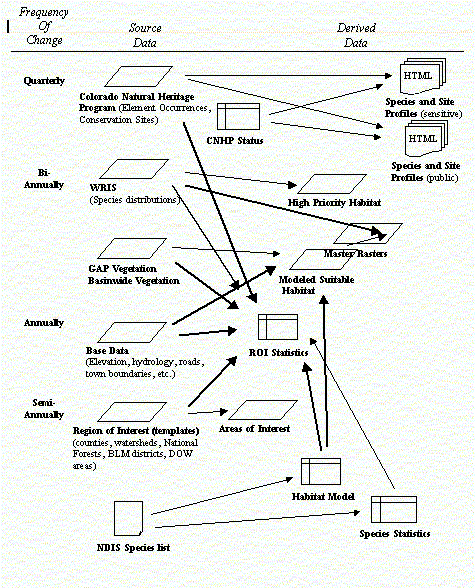
Table 1. Example of SCoP data dictionary.
Theme: [CNHP Element Occurrences]
Attributes: 4605 (0 selected)
FIELD, ALIAS, TYPE, WIDTH(PRECISION), DESCRIPTION
Shape(Shape) FIELD_SHAPEPOLY, 8(0),
Area(Area) FIELD_DECIMAL, 12(3),
Perimeter(Perimeter) FIELD_DECIMAL, 12(3),
Eocode(Eocode) FIELD_CHAR, 14(0), element occurrence
Sname(Sname) FIELD_CHAR, 90(0), scientific name
Scomname(Scomname) FIELD_CHAR, 90(0), common name
Taxgroupdb(Taxgroupdb) FIELD_CHAR, 20(0),taxonomic group
Grank(Grank) FIELD_CHAR, 10(0), Glogal Rank
Srank(Srank) FIELD_CHAR, 10(0), State Rank
Usesa(Usesa) FIELD_CHAR, 4(0),ESA (values=C,LE,LT,PE,"")
Fed_sens(Fed_sens) FIELD_CHAR, 10(0),Federally sensitive (value = BLM, FS, FS/BLM, "")
Sprotcasdb(Sprotcasdb) FIELD_CHAR, 4(0), State ESA (value = E, SC, T, "")
Precision(Precision) FIELD_CHAR, 1(0), sampling precision (S- seconds, M - minutes)
Lastobs(Lastobs) FIELD_CHAR, 10(0), last observation
Bestsrcdb(Bestsrcdb) FIELD_CHAR, 254(0), Best source description
Cnhp_code(Cnhp_code) FIELD_CHAR, 10(0), Element occurrence
Data_sens(Data_sens) FIELD_DECIMAL, 1(0), sensitive data flag (1 sensitive, 0-not sensitive)
Table:[status_codes.dbf]
FIELD, ALIAS, TYPE, PRECISION
Code(Code) FIELD_CHAR, 20(0), Look up value for SRANK and GRANK Descriptio(Descriptio) FIELD_CHAR, 170(0), text description