Author: Dr Rick Thomas
Insurance Pricing with GIS
Abstract
Insurance and reinsurance are generally priced on the basis of past claims experience. This approach has two key weaknesses. The first problem is the limited time span for which claims data is available. The second is that the past is not necessarily a reliable predictor of the future.
For the first problem the general solution involves linking natural hazard information from outside of the insurance industry to claims data, and hence producing models for geographically rating primary insurance. For the second problem, theories about possible climate trends, demographic changes etc. can be built into GIS based models.
Introduction
For an individual the risk of losing everything in a house fire or river flood is normally unacceptable. Insurance is a viable business, because these individually unacceptable risks can be pooled into a far less risky portfolio. A mathematical measure of risk in this context is the volatility (measured as the coefficient of variation) of the losses incurred. For an ideal portfolio of independent risks the volatility would be a decreasing function, proportional to the square root of the number of policies written. In reality this ideal cannot be met, as single events may affect more than one risk at a time. Examples of this are hurricanes, which have widespread effects, or even more spatially restricted events like floods and small earthquakes. In a more mathematical language the risks can be referred to as being non-independent. It is in an insurers best interest to maximize the independence of the risks he insures, and it is intuitively clear that a wide spatial distribution of risks will significantly help.
This approach is a good beginning, but what about widespread perils like hurricanes? A solution would be to entirely avoid hurricane prone areas, but this is a very drastic response, which would leave most of the US east coast uninsurable for one of the key natural perils that threatens homeowners there. In this case, part of the solution is reinsurance. Reinsurance is insurance for insurers bought to keep their results stable and their shareholders satisfied. To run a viable business, reinsurers must themselves construct a diversified portfolio, and to do this effectively their geographic diversification must be global.
So far we have only introduced one geographic element to insurance pricing, namely the spatial distribution of risks. A second geographic element is the site specific risk, essentially the exposure of a specific site to all possible perils. For example a house located on a flood plain has a high site specific flood risk. After a general discussion of insurance pricing and its relationship to geography the role of GIS systems will be illustrated using case studies.
Pricing
The technical pricing of insurance aims to set a fair price level. This price must combine expected loss, with a risk premium related to the volatility. The normal approach is to set a price at some geographic aggregation using claims experience to estimate both the expected loss and its volatility. For some perils, for example fire, claims experience and standard actuarial methods provide a reliable solution. For infrequent perils it is advisable to draw on other sources of information, and GIS provides an invaluable framework within which to do this. For any worldwide location the following infrequent perils can be modeled using data from non-insurance sources.
(This is not an exhaustive list.)
In order to use this external data insurers must produce a model of the loss process that they are pricing for. As a first step towards such a model, it is normal to split the problem into two separate parts: hazard and vulnerability. Hazard is defined as the natural or man made agent that gives rise to insurance claims, whilst vulnerability is defined as the claims level at a given hazard intensity.
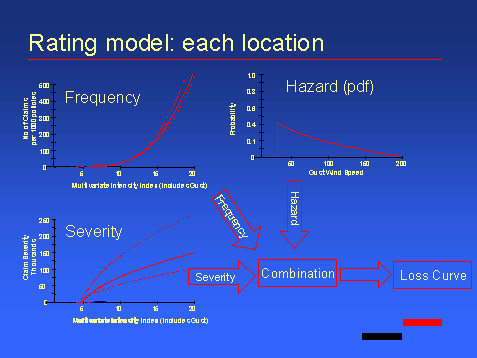
From an insurer's perspective, hazard is best modeled based on external data, whereas vulnerability can only be properly defined using internal claims data. This claims data must then be combined with hazard information from events where hazard intensities are known or can be modeled (see example 2). In any single location, the price for a given peril can be calculated using the following:
The hazard intensity probability density function can be converted into a loss distribution using the vulnerability function. The form of both of these functions is highly dependent on the peril considered, and also varies significantly with location.
To provide a concrete example of an implementation of this sort of pricing approach a simple hypothetical windstorm model will be described.
Hazard: For wind some form of gust wind speed is normally used, for example 3 second peak gust.
Vulnerability: This can be modeled as the loss (% of sum insured), as a function of the hazard intensity defined above.
It is clear that damaging wind speeds are a rare event at most localities where houses are built, and local building practices tend to ensure that this remains the case. In modeling terms this means that only gusts over a certain minimum threshold need to be considered. A probabilistic treatment of these extreme gusts can be built up using meteorological records for a given region combined with site specific features. This sort of work is best carried out by professional meteorologists as there are often many pitfalls associated with data quality. At this stage it is also possible to produce a forward looking view of the wind hazard at a site, this could be essential if climate change trends are likely to have a significant effect in the region under consideration.
For insurance statisticians it is normal for such probabilistic hazard models to be presented as a separate frequency and intensity distributions. For example a Negative Binomial frequency distribution with a mean of say 2 gusts per year, combined with a Pareto distribution describing the intensity of the gusts. These distributions can be compounded to produce a pdf of gust wind speed, and hence a pdf of loss level, which in turn provides all the information required to produce the price for wind. If windstorms were spatially restricted events this would be a complete pricing solution, however the issue of correlation is very important for this peril. Hence the limits of this local method are explored in the first case study where US and Caribbean hurricane exposure is examined.
In the preceding windstorm pricing example we assumed that the vulnerability functions for the risks were known. Although published data on vulnerability is available, in general it is better to derive vulnerability functions using claims data. The second case study outlines such an analysis carried out on claims data split according to US ISO forms and construction types. The study used GIS to link the explanatory variables such as modeled wind speed, duration, local shelter etc. with the observed claims experience. The statistical analysis and derivation of loss functions was carried out using S+.
In some cases no claims data exists and vulnerability needs to be assessed by some other means. The third case study outlines a flood study done in Basel where vulnerability was estimated by PartnerRe engineers and loss adjusters. In this study the GIS was used to bring together the data from different sources, rather than to carry out the analysis.
The final example presents a complete pricing solution for the earthquake peril. It is generally acknowledged that the only way to price this peril is to model it, and in this case a GIS can be used to implement the whole solution.
Example 1:
Caribbean correlation/Accumulation Control
Introduction
This study analyses the correlation between various windstorm zones in the US and Caribbean. The purpose was to help answer two questions.
Method
A map of arbitrarily defined Atlantic windstorm zones was created. Using this map, published NOAA best track data for all hurricanes since 1886 were analyzed, to determine which locations they had affected. The following screenshot shows the Arc View3.0a project used for the analysis.
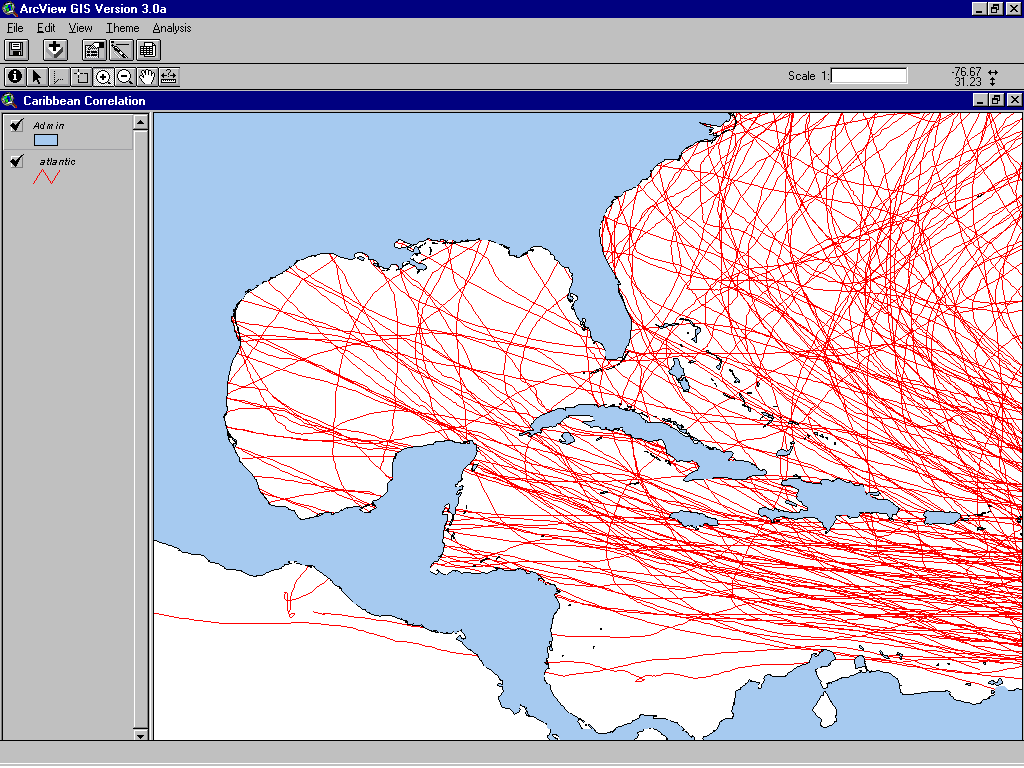
A hurricane was determined to have affected a location if the track center passed within 100 km of it. The zones used were defined as follows:
|
Zone |
Definition |
|
US_1 |
Florida, Alabama, Carolinas, Georgia |
|
US_2 |
Delaware, District of Columbia, West Virginia, Vermont, Virginia, Connecticut, Maine, Rhode Island, Massachusetts, New Jersey, New York, Pennsylvania, Maryland, New Hampshire |
|
US_3 |
Texas, Kansas, Louisiana, Arkansas, Mississippi, Oklahoma |
|
Bahamas |
Standard |
|
Barbados |
Standard |
|
Cayman Islands |
Standard |
|
Dominican Republic |
Standard |
|
Lesser Antilles |
Antigua, Saint Christopher, Marie Galante, Barbuda, Nevis, Bequia, Union Island, Isle Quatre, Baliceaux Island, Mayreau, Grenadine Islands, Grenadine Islands, Scrub Island, Saint Martin, Redonda |
|
Jamaica |
Standard |
|
Netherland Antilles |
Curacao, Bonaire, Saint Eustatius, Saba Island |
|
Trinidad |
Standard |
|
Puerto Rico |
Standard |
|
Bermuda |
Standard |
|
Virgin Islands |
Includes British Virgin Islands |
Results
The results of the analysis showed that 65% of hurricanes affected at least one location. The included histogram shows how multiple hits were distributed. Analysis of this count data using Maximum Likelihood fits to discrete probability distributions found no standard distribution that adequately fitted.
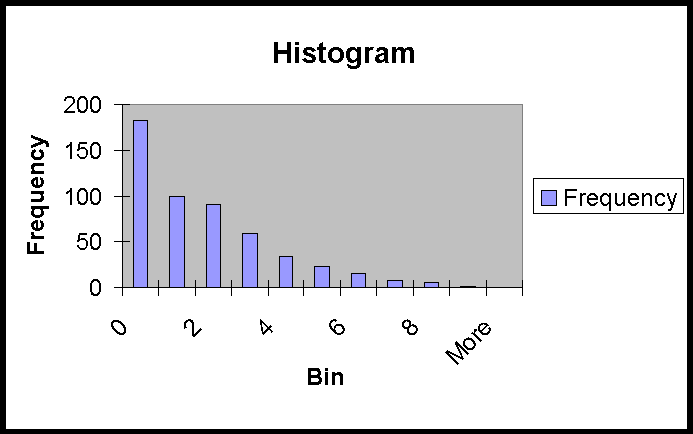
The data from the 521 analyzed hurricanes can be used to approximate the joint distribution of hits to zones. A more accessible use of the data is to define the correlation between each of the zones, which can be expressed with a matrix as below.
|
US_1 |
US_2 |
US_3 |
Bah-amas |
Barba-dos |
Cay-man |
Dom-Rep |
LesserAnt |
Jam-aica |
Neth Ant |
Trini-dad |
PuertoRico |
Ber-muda |
Virgin Island |
|
|
US_1 |
1.00 |
|||||||||||||
|
US_2 |
0.52 |
1.00 |
||||||||||||
|
US_3 |
0.13 |
-0.03 |
1.00 |
|||||||||||
|
Bah-amas |
0.31 |
0.13 |
-0.04 |
1.00 |
||||||||||
|
Barba-dos |
-0.11 |
-0.03 |
0.08 |
-0.03 |
1.00 |
|||||||||
|
Cay-man |
0.00 |
-0.02 |
0.14 |
0.14 |
0.13 |
1.00 |
||||||||
|
Dom-Rep |
0.05 |
0.15 |
0.07 |
0.22 |
0.06 |
0.06 |
1.00 |
|||||||
|
LesserAnt |
-0.02 |
0.10 |
0.10 |
0.12 |
0.49 |
0.24 |
0.46 |
1.00 |
||||||
|
Jam-aica |
-0.10 |
-0.08 |
0.15 |
0.04 |
0.14 |
0.53 |
0.13 |
0.32 |
1.00 |
|||||
|
Neth Ant |
0.02 |
0.07 |
0.00 |
0.06 |
0.17 |
0.08 |
0.26 |
0.54 |
0.10 |
1.00 |
||||
|
Trini-dad |
-0.03 |
-0.06 |
0.05 |
-0.03 |
0.09 |
0.01 |
-0.04 |
0.26 |
0.09 |
0.23 |
1.00 |
|||
|
PuertoRico |
0.07 |
0.14 |
0.01 |
0.24 |
0.10 |
-0.02 |
0.60 |
0.47 |
0.01 |
0.40 |
-0.04 |
1.00 |
||
|
Ber-muda |
-0.10 |
-0.12 |
-0.12 |
0.06 |
0.04 |
-0.05 |
0.08 |
0.03 |
-0.03 |
-0.02 |
-0.03 |
0.01 |
1.00 |
|
|
Virgin Island |
0.04 |
0.11 |
0.00 |
0.19 |
0.08 |
-0.04 |
0.34 |
0.54 |
0.02 |
0.58 |
-0.05 |
0.68 |
0.10 |
1.00 |
Negative correlations are highlighted in bold, and positive ones above 0.5 shown in red. At first sight the most worrying correlation is between US_1 (Florida) and US_2 (North East). It is, however, very important to note that the correlation between losses will be less than the 0.52 figure shown, because the method used above is based on hits and doesn't consider the strength of the storm at each location
Pricing
It is easier, more accurate and more complete to work out a local hazard curve than create a set of events for modeling portfolio losses. Such a local hazard curve can be combined with local vulnerability to define a fully probabilistic loss curve (as in the pricing example). To calculate a portfolio wide loss distribution these local loss curves must be aggregated taking into account their joint distributions. However, this aggregation step is very difficult as the necessary joint loss distributions are hard to define. It is extremely important to note that the correlation coefficient between two variables is not sufficient to define a joint distribution except in trivial cases.
Despite the preceding points pricing models have been developed using an approach based on aggregation of local loss distributions to calculate the ground up loss distributions for portfolios. The joint distribution problem is partly solved using a giant correlation matrix linking all modeled locations. This correlation matrix allows the correlation between all combinations of locations to be calculated via covariances. A specific form of joint distribution must then be assumed to carry out the next step in the calculation.
The following numerical example serves to illustrate the point that correlation alone doesn't define a joint distribution even in simple examples. The example will also hopefully clarify what a joint distribution is.
For two discrete random variables X and Y with possible values restricted to 0,1 or 2, the following two tables show the 'Marginal Distributions'. The distributions of X and Y alone.
Marginal distribution of X
|
X |
0 |
1 |
2 |
|
P(X) |
0.5 |
0.3 |
0.2 |
E(X) = 0.7
Var(X) = 0.61
Marginal Distribution of Y
|
Y |
0 |
1 |
2 |
|
P(Y) |
0.4 |
0.5 |
0.1 |
E(X) = 0.7
Var(X) = 0.41
For a correlation of 0.5, E(XY) must be equal to 0.49. Two possible (approximate) joint distributions with this property are shown in the following tables.
Joint distribution P1(X,Y)
|
X |
0 |
1 |
2 |
|
|
Y |
0.5 |
0.3 |
0.2 |
|
|
0 |
0.4 |
0.2255 |
0.1135 |
0.061 |
|
1 |
0.5 |
0.2004 |
0.1605 |
0.1391 |
|
2 |
0.1 |
0.0741 |
0.0259 |
0 |
Joint distribution P2(X,Y)
|
X |
0 |
1 |
2 |
|
|
Y |
0.5 |
0.3 |
0.2 |
|
|
0 |
0.4 |
0.1682 |
0.1255 |
0.1064 |
|
1 |
0.5 |
0.2982 |
0.1697 |
0.0321 |
|
2 |
0.1 |
0.0336 |
0.0047 |
0.0617 |
These are clearly different as in the first there is no chance of both X and Y having the value 2, whereas in the second this has a probability of 0.0617. To turn this into an insurance example, X+Y can be used to define the aggregate loss. If an excess of loss reinsurance cover with a deductible of 3 is in place for the joint distribution P1(X,Y) it would never be hit, whereas for P2(X,Y) the risk premium would be 0.0617.
It is worth noting that the mean and the variance of the joint distribution are uniquely defined thus the expected ground up loss and its variance can be calculated. For a primary insurer, where the claims activity comes from all of the loss distribution, it may be adequate to work with moments alone. Reinsurers are interested in only a small part of the overall distribution, namely the tail, and as illustrated not knowing the true loss distribution could have dramatic effects on profitability. From this example it is clear that it is better to use a method that correctly builds the joint distribution than a method that arbitrarily uses correlation coefficients. The next section on accumulation control introduces such a method.
Adding Accumulations
To protect themselves from large losses 'accumulating' due to a single event insurers and reinsurers use various methods to limit and monitor their exposures. In order to add and control accumulations it is necessary to consider how those accumulations are defined and also to be clear on exactly how the result is to be used.
The most basic approach is to define a set of geographic zones (eg) the CRESTA zones, and write to a maximum aggregate exposure in each of them. This is easy for reinsurers working with excess of loss contracts, as the aggregates can be defined as the sum of exposed layers, and it is perfectly possible that all layers will be blown. A slightly refined version is necessary for contracts that are unlikely to suffer 100% losses, and approaches based on PMLs (Probable maximum losses) or EMLs (Estimated maximum loss) are generally used. The control element of this approach is to limit the accumulations to a fixed maximum value per zone.
A significantly more elegant accumulation control solution uses a set of events representing thousands of years of insurance losses, and overlays them on the whole in force portfolio. Such an event set is used to calculate the losses from each exposed line of business with all correlation correctly built in, and hence provides a fully probabilistic model of the loss potential. For the Caribbean this solution would be practical using PartnerRe's simulations of Atlantic Hurricanes. With such an event set it would be possible to measure accumulations as market wide wide losses with given return periods. It would also be possible to drill down and identify the events and hence the locations contributing most to any loss.
Conclusions
Although both a solution for both accumulation control and pricing is possible using correlated local loss distributions, such a solution has significant flaws. In fact an event set looks the most sensible pricing and accumulation control method. This is because it will reproduce the true joint distribution of losses, rather than an arbitrarily selected one.
Example 2
Vulnerability analysis
Introduction
Using loss data provided by clients and wind fields calculated using the PartnerRe Hurricane model a statistical analysis of building performance was carried out. The analysis was performed at Zip code resolution for all data, and vulnerability functions relating the mean damage ratio (MDR) to the peak gust wind speed within the Zip code were derived for three ISO building classes (1, 2 and 3) and three standard "forms" (HO2, HO3 and HO4). The data were inadequate to provide reliable results for "form" HO6 or any other ISO classes.
The statistical analysis was split into two parts, a study of loss frequency and a study of loss severity. This is an informative approach as it highlights features such as high frequency low severity claims that could be avoided with higher deductibles.
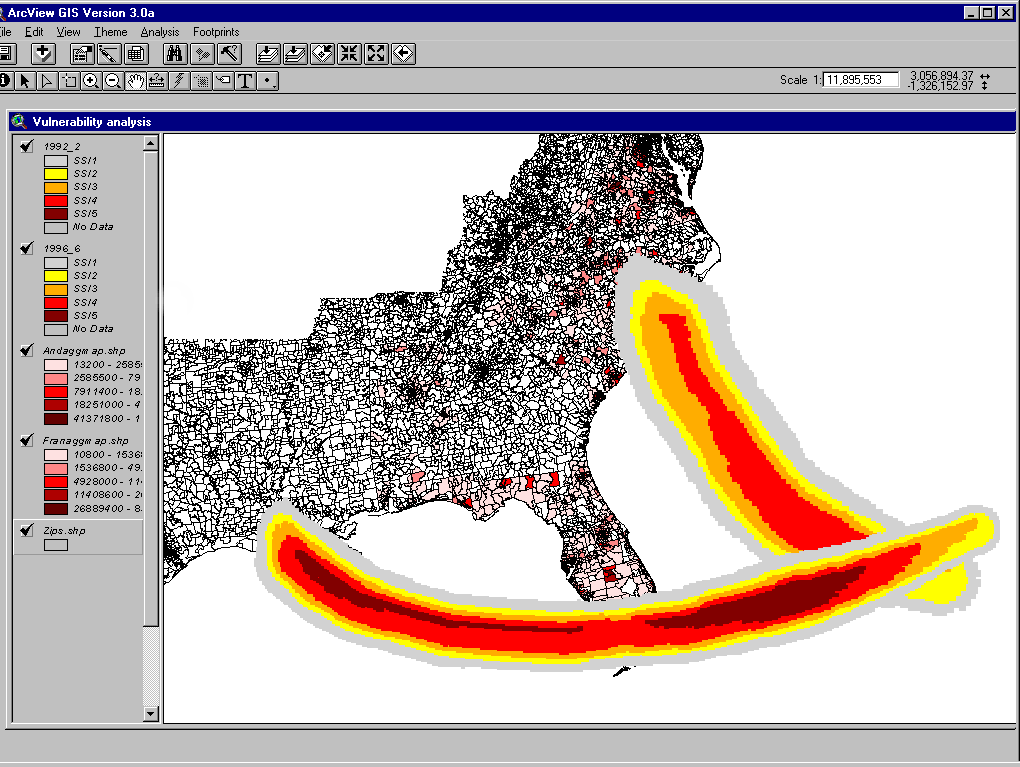
In this summary one of the four hurricane wind fields is presented, colored according to Saffir-Simpson category, as an overlay for the client portfolio. The portfolios is thematically mapped to show the total aggregates within each Zip code.
Results Summary
Analysis was carried out at Zip code level for the clients homeowners business affected by Andrew, Hugo, Opal and Fran.
Loss frequency curves for HO3 showed generally higher claims rates than Friedman (1982), whilst HO2 results were almost identical to Friedman (1982). We return to this observation in the conclusion.
Vulnerability curves were calculated for the following ISO classes and forms:
ISO Classes
ISO1: Frame (not aluminum or plastic siding over frame)
ISO2: Brick veneer, stone veneer or masonry veneer
ISO3: Brick, stone or masonry
Forms
HO2: Standard
HO3: Executive home
HO4: Tenants, contents only
The standard conversion between knots and mph used was 1mph = 0.864 Knots.
Conclusion
It is possible to neatly split the conclusions into two parts the first discusses the relative performance of each ISO category and the second part covers the comparisons between the "forms".
ISO
The general conclusion based on the ISO classes is that ISO1 and ISO2 are the least wind resistant, with similarly poor performance. The only exception is that ISO2 for HO2 forms becomes significantly worse than ISO1 for winds above 110 knots (127 mph). A possible explanation is that the ties linking the brick (stone) veneers to the house frame are less reliable for the relatively lower quality housing covered by form HO2 than for the executive homes covered by HO3. The ISO3 (Brick, stone or masonry) consistently performs better than the other two classes, although the difference is less marked for executive homes than for standard policies.
Forms
The basic comparison of the three forms holds no great surprises. The standard homes covered by form HO2 perform worse than the better quality homes covered by form HO3. Two further more detailed observations follow.
First, the contents only forms show an initially lower vulnerability than any of the building types, followed by a very steep rise in MDR at higher wind speeds. This makes sense, as a lot of lower wind speed building damage (e.g. snapped TV aerials, lost roof tiles) would occur before any structural elements or windows/shutters failed. Once a window failed however, the resulting water ingress would cause severe levels of damage especially to electrical goods bedding etc.
Second, the frequency of claims for the HO3 forms is notably high in comparison with Friedman, but the level of claims as a function of the total sum insured is relatively much lower, (hence the overall better performance). This indicates a significantly higher readiness to claim amongst HO3 policy holders relative to standard policy holders. The best explanation hinges on the deductible size. Although the absolute value of the average deductible for HO3 policy holders is more than that of any other types of policy, as a fraction of the total sum insured it is a factor of two lower. (0.1% HO3 compared to 0.21% HO2).
Example 3:
Flood study
Introduction
Hydrological modeling using GIS is a highly developed field, and a considerable amount of expertise is accessible to insurers and reinsurers. Tapping into these skills is best done through hydrological institutes, university research departments or consultancy companies. The flood study outlined here was done in Basel, Switzerland, which is situated on the Rhine, and hence potentially flood exposed. The purpose of the study was to estimate the potential losses at specified flow rates, and hence the reinsurance price and requirements for the peril. As there have been no significant floods in Basel since the late nineteenth century, pricing based on claims statistics was impossible.
Method
The hazard component was analyzed using a model specifically developed for the Rhine in Basel by the ETH in Zurich (Federal Institute of Technology). This hazard model is based on a detailed geodetically surveyed elevation model of Basel, and numerous cross sectional profiles for the Rhine, combined with standard flow equations. The selected approach was to create three deterministic scenarios for different fluxes 4900, 5200 and 5500 m3/s. The return periods for these fluxes were estimated as 98, 171 and 289 years respectively. Vulnerability was assessed by comparing the sums insured with site surveys of many of the potentially affected risks. These surveys were carried out by PartnerRe engineers and local loss adjusters, and revealed significantly higher vulnerability than would have been assumed using standard published vulnerability curves. To produce final loss estimates a map of flood depths for each event was combined with the map of insured risks using Arc View. This gave the hazard intensity at each location, which was converted to the loss for each location using the vulnerability curves.
Results
Losses varied by a factor of four over the three scenarios considering both summer and winter conditions. In winter the potential losses are far greater than summer for the same event. This is because the main component of the cost is drying of the buildings, which requires far more time and energy in winter than summer. Although the fluxes used to define the scenarios have specific return periods these return periods cannot be directly translated into loss return periods. In this case this is because the same flux produces radically different losses depending on the time of year. This is a general drawback of scenario based approaches.
Conclusion
This scenario based approach illustrates the opposite extreme to the first example. In this flood study here a limited number of single events simultaneously affect a significant number of the risks in a given portfolio. The probability of these individual events is however hard if not impossible to determine. It is however clear that without external data no price estimates could have been produced.
Example 4:
Earthquake pricing
Introduction
Damaging earthquakes are fortunately rare events, and as a result it is not possible to price for earthquakes using loss experience alone. In fact for this peril the only viable pricing solution is an earthquake model. Such a model must credibly reproduce hazard, and deal with data in the form that underwriters receive it. PartnerRe has developed models using Arc View GIS, because the customizable user interface has allowed a standard model template to be created. This template deals with all the basic data manipulation, and data formats in a common way for all models. The hazard and vulnerability are then built in as peril and location specific components.
Method
A standard underwriting interface has been developed for PartnerRe models, and this is illustrated below.
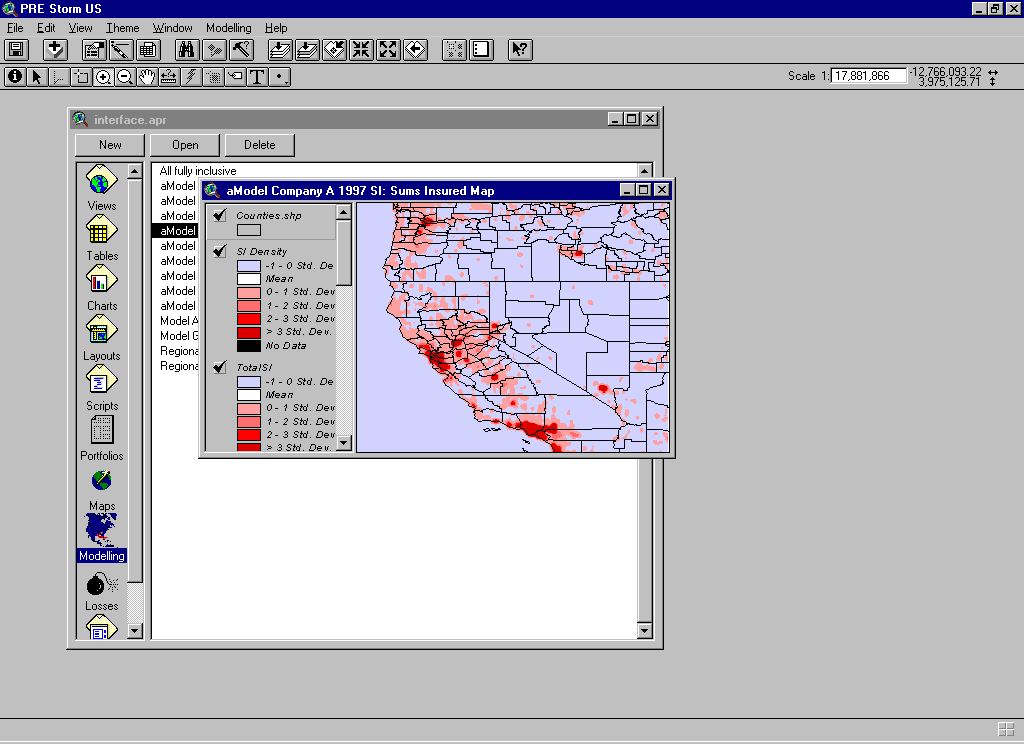
For earthquake, hazard can be modeled based on a combination of historical seismicity, fault and palaeoseismic data. This data is used to produce a worldwide seismic zonation, as the basis for event simulation. Any such model must implement, as far as possible, the best practice for each location worldwide, which requires a thorough literature search. Earthquake events can then be created using Monte Carlo simulation based on the parameters defined in the seismic zonation. For each potentially damaging earthquake a ground motion map must be produced using standard attenuation functions and local soil conditions. Vulnerability is modeled based on ATC13, or modifications ATC13 based on more recent published damage studies and actual claims experience. These data can then be combined with client portfolio information within the standard model interface, and used to produce prices.
Conclusion
An event set must be used rather than a seismic hazard map because it is essential to build in the effects of simultaneous losses correctly (joint distribution problem discussed in example 1). The following key advantages of using GIS for model development have been repeatedly demonstrated within the PartnerRe research team:
Summary of case studies
A range of applications has been given showing that GIS can be used as anything from a complement to traditional methods to a full pricing solution. The simple analysis of landfalls in the Caribbean could be carried out by most users with limited training, and the output built into a traditional accumulation control or pricing system. The second example, derivation of vulnerability functions, is technically more complex and requires some scripting or programming to calculate the hurricane wind fields. Such work is however far simpler than the statistical analysis of loss data that is required to turn the raw data into a good vulnerability model. It is this very statistical analysis, however, that is a standard part of actuarial work, and hence a core competence in many insurance companies. The application of vulnerability functions produced in this manner is not limited to in house models, because they can also be compared to those provided in vendor models or even built into such models.
The flood study and earthquake model illustrate two different approaches to GIS use for full loss modeling. In the first example GIS is used simply as a means of displaying and linking the data, whereas in the second case GIS provides the complete framework from hazard modelling to a desktop pricing tool for underwriters.
Overall conclusions
This paper has presented a snapshot of GIS for the pricing of insurance. All the examples address different aspects of insurance pricing, and hopefully give a good overview of the diversity of possible applications that GIS has for property insurance pricing. To implement any of these approaches external data is essential, and in fact the acquisition of such data is often a significant challenge. An obstacle in this field has been that existing service providers were more interested in selling complete software solutions than data. This made economic sense for them, but the flexibility gained by the creation of in house expertise and GIS based systems gives insurers and reinsurers such a competitive advantage that the demand for data only and contract research type solutions is growing. Another key advantage of in house expertise is cost savings, although the service providers offer large teams of 'experts' one a one stop basis, equivalent experts are more cheaply available in university departments and specialized consultancies worldwide. A fairly small competent in house team can manage such contacts efficiently .
The case studies were chosen to illustrate different levels of application of GIS technology, from work that is possible with an out of the box product, to more technical uses where customization is necessary. The main contribution of GIS is the provision of an environment where previously separate data can be linked together. This enables insurers to escape from simply rating using claims experience, to an extended approach where longer timescales can be better assessed. This is an especially important step when pricing for natural catastrophes. In this field models are the only way to estimate the magnitude of extreme events, even 20 years of claims experience are of limited value when estimating a fifty or hundred year event. In fact using such long claims records bring with them significant problems of 'as if' correction, where inflation rates, policy changes and population growth have to be corrected for, to bring each loss up to its present value.
The overall conclusion is that GIS increases flexibility, however this flexibility comes with a price. Although GIS technology is relatively easy to use, it is not so simple that anyone can use it to its full capacity without a significant training period. This argument has often been used to justify outsourcing of all geographic modeling tasks, but this cannot remain a long term solution. It is generally argued that firms should concentrate on core competencies only. When GIS is considered split from its possible applications, it can be argued that it is nothing to do with the core competencies of an insurer. This is however a short sighted approach, because as this paper demonstrates, GIS is an essential tool for modern insurance pricing.